Discounted cumulative gain
Discounted cumulative gain (DCG) is a measure of ranking quality. In information retrieval, it is often used to measure effectiveness of web search engine algorithms or related applications. Using a graded relevance scale of documents in a search engine result set, DCG measures the usefulness, or gain, of a document based on its position in the result list. The gain is accumulated from the top of the result list to the bottom with the gain of each result discounted at lower ranks.[1]
Overview
Two assumptions are made in using DCG and its related measures.
- Highly relevant documents are more useful when appearing earlier in a search engine result list (have higher ranks)
- Highly relevant documents are more useful than marginally relevant documents, which are in turn more useful than irrelevant documents.
DCG originates from an earlier, more primitive, measure called Cumulative Gain.
Cumulative Gain
Cumulative Gain (CG) is the predecessor of DCG and does not include the position of a result in the consideration of the usefulness of a result set. In this way, it is the sum of the graded relevance values of all results in a search result list. The CG at a particular rank position 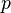 is defined as:
is defined as:

Where  is the graded relevance of the result at position
is the graded relevance of the result at position  .
.
The value computed with the CG function is unaffected by changes in the ordering of search results. That is, moving a highly relevant document 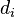 above a higher ranked, less relevant, document
above a higher ranked, less relevant, document  does not change the computed value for CG. Based on the two assumptions made above about the usefulness of search results, DCG is used in place of CG for a more accurate measure.
does not change the computed value for CG. Based on the two assumptions made above about the usefulness of search results, DCG is used in place of CG for a more accurate measure.
Discounted Cumulative Gain
The premise of DCG is that highly relevant documents appearing lower in a search result list should be penalized as the graded relevance value is reduced logarithmically proportional to the position of the result. The discounted CG accumulated at a particular rank position is defined as:[2]

Previously there has not been any theoretically sound justification for using a logarithmic reduction factor[3] other than the fact that it produces a smooth reduction. But Wang et al. (2013)[4] give theoretical guarantee for using the logarithmic reduction factor in NDCG. The authors show that for every pair of substantially different ranking functions, the NDCG can decide which one is better in a consistent manner.
An alternative formulation of DCG[5] places stronger emphasis on retrieving relevant documents:

The latter formula is commonly used in industry including major web search companies[2] and data science competition platform such as Kaggle.[6]
In Croft, Metzler and Strohman (page 320, 2010), the authors mistakenly claim that these two formulations of DCG are the same when the relevance values of documents are binary;  . To see that they are not the same, let there be one relevant document and that relevant document is at rank 2. The first version of DCG equals 1 / log2(2) = 1. The second version of DCG equals 1 / log2(2+1) = 0.631. The way that the two formulations of DCG are the same for binary judgments is in the way gain in the numerator is calculated. For both formulations of DCG, binary relevance produces gain at rank i of 0 or 1. No matter the number of relevance grades, the two formulations differ in their discount of gain.
. To see that they are not the same, let there be one relevant document and that relevant document is at rank 2. The first version of DCG equals 1 / log2(2) = 1. The second version of DCG equals 1 / log2(2+1) = 0.631. The way that the two formulations of DCG are the same for binary judgments is in the way gain in the numerator is calculated. For both formulations of DCG, binary relevance produces gain at rank i of 0 or 1. No matter the number of relevance grades, the two formulations differ in their discount of gain.
Note that Croft et al. (2010) and Burges et al. (2005) present the second DCG with a log of base e, while both versions of DCG above use a log of base 2. When computing NDCG with the second formulation of DCG, the base of the log does not matter, but the base of the log does affect the value of NDCG for the first formulation. Clearly, the base of the log affects the value of DCG in both formulations.
Normalized DCG
Search result lists vary in length depending on the query. Comparing a search engine's performance from one query to the next cannot be consistently achieved using DCG alone, so the cumulative gain at each position for a chosen value of should be normalized across queries. This is done by sorting documents of a result list by relevance, producing the maximum possible DCG till position , also called Ideal DCG (IDCG) till that position. For a query, the normalized discounted cumulative gain, or nDCG, is computed as:

The nDCG values for all queries can be averaged to obtain a measure of the average performance of a search engine's ranking algorithm. Note that in a perfect ranking algorithm, the  will be the same as the
will be the same as the  producing an nDCG of 1.0. All nDCG calculations are then relative values on the interval 0.0 to 1.0 and so are cross-query comparable.
producing an nDCG of 1.0. All nDCG calculations are then relative values on the interval 0.0 to 1.0 and so are cross-query comparable.
The main difficulty encountered in using nDCG is the unavailability of an ideal ordering of results when only partial relevance feedback is available.
Example
Presented with a list of documents in response to a search query, an experiment participant is asked to judge the relevance of each document to the query. Each document is to be judged on a scale of 0-3 with 0 meaning irrelevant, 3 meaning completely relevant, and 1 and 2 meaning "somewhere in between". For the documents ordered by the ranking algorithm as

the user provides the following relevance scores:

That is: document 1 has a relevance of 3, document 2 has a relevance of 2, etc. The Cumulative Gain of this search result listing is:

Changing the order of any two documents does not affect the CG measure. If  and
and  are switched, the CG remains the same, 11. DCG is used to emphasize highly relevant documents appearing early in the result list. Using the logarithmic scale for reduction, the DCG for each result in order is:
are switched, the CG remains the same, 11. DCG is used to emphasize highly relevant documents appearing early in the result list. Using the logarithmic scale for reduction, the DCG for each result in order is:
| |
|
 |
 |
|---|---|---|---|
| 1 | 3 | 0 | N/A |
| 2 | 2 | 1 | 2 |
| 3 | 3 | 1.585 | 1.892 |
| 4 | 0 | 2.0 | 0 |
| 5 | 1 | 2.322 | 0.431 |
| 6 | 2 | 2.584 | 0.774 |
So the  of this ranking is:
of this ranking is:

Now a switch of and results in a reduced DCG because a less relevant document is placed higher in the ranking; that is, a more relevant document is discounted more by being placed in a lower rank.
The performance of this query to another is incomparable in this form since the other query may have more results, resulting in a larger overall DCG which may not necessarily be better. In order to compare, the DCG values must be normalized.
To normalize DCG values, an ideal ordering for the given query is needed. For this example, that ordering would be the monotonically decreasing sort of the relevance judgments provided by the experiment participant, which is:
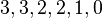
The DCG of this ideal ordering, or IDCG, is then:
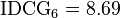
And so the nDCG for this query is given as:

Limitations
- Normalized DCG metric does not penalize for bad documents in the result. For example, if a query returns two results with scores
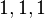 and
and  respectively, both would be considered equally good even if the latter contains a bad result. One way to take into account this limitation is to use
respectively, both would be considered equally good even if the latter contains a bad result. One way to take into account this limitation is to use  in the numerator for scores for which we want to penalize and
in the numerator for scores for which we want to penalize and  for all others. For example, for the ranking judgments
for all others. For example, for the ranking judgments  one might use numerical scores
one might use numerical scores  instead of
instead of  .
. - Normalized DCG does not penalize for missing documents in the result. For example, if a query returns two results with scores and
 respectively, both would be considered equally good. One way to take into account this limitation is to enforce fixed set size for the result set and use minimum scores for the missing documents. In previous example, we would use the scores
respectively, both would be considered equally good. One way to take into account this limitation is to enforce fixed set size for the result set and use minimum scores for the missing documents. In previous example, we would use the scores  and and quote nDCG as nDCG@5.
and and quote nDCG as nDCG@5. - Normalized DCG may not be suitable to measure performance of queries that may typically often have several equally good results. This is especially true when this metric is limited to only first few results as it is done in practice. For example, for queries such as "restaurants" nDCG@1 would account for only first result and hence if one result set contains only 1 restaurant from the nearby area while the other contains 5, both would end up having same score even though latter is more comprehensive.
References
- ↑ Kalervo Jarvelin, Jaana Kekalainen: Cumulated gain-based evaluation of IR techniques. ACM Transactions on Information Systems 20(4), 422–446 (2002)
- 1 2 "Introduction to Information Retrieval - Evaluation" (PDF). Stanford University. 21 April 2013. Retrieved 23 March 2014.
- ↑ B. Croft, D. Metzler, and T. Strohman (2009). Search Engines: Information Retrieval in Practice. Addison Wesley".
- ↑ Yining Wang, Liwei Wang, Yuanzhi Li, Di He, Wei Chen, Tie-Yan Liu. 2013. A Theoretical Analysis of NDCG Ranking Measures. In Proceedings of the 26th Annual Conference on Learning Theory (COLT 2013).
- ↑ Chris Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Greg Hullender. 2005. Learning to rank using gradient descent. In Proceedings of the 22nd international conference on Machine learning (ICML '05). ACM, New York, NY, USA, 89-96. DOI=10.1145/1102351.1102363 http://doi.acm.org/10.1145/1102351.1102363
- ↑ "Normalized Discounted Cumulative Gain". Retrieved 23 March 2014.