Differential diagnosis
| Differential diagnosis | |
|---|---|
| Intervention | |
| MeSH | D003937 |
In medicine, a differential diagnosis is the distinguishing of a particular disease or condition from others that present similar symptoms.[1] Differential diagnostic procedures are used by physicians and other trained medical professionals to diagnose the specific disease in a patient, or, at least, to eliminate any imminently life-threatening conditions. Often each individual option of a possible disease is called a differential diagnosis (for example, bronchitis could be a differential diagnosis in the evaluation of a cough that ends up with a final diagnosis of common cold).
More generally, a differential diagnostic procedure is a systematic diagnostic method used to identify the presence of a disease entity where multiple alternatives are possible. This method is essentially a process of elimination or at least a process of obtaining information that shrinks the "probabilities" of candidate conditions to negligible levels, by using evidence such as symptoms, patient history, and medical knowledge to adjust epistemic confidences in the mind of the diagnostician (or, for computerized or computer-assisted diagnosis, the software of the system).
Differential diagnosis can be regarded as implementing aspects of the hypothetico-deductive method, in the sense that the potential presence of candidate diseases or conditions can be viewed as hypotheses that physicians further determine as being true or false.
Common abbreviations of the term "differential diagnosis" include DDx, ddx, DD, D/Dx, or ΔΔ.
General components
There are various methods of performing a differential diagnostic procedure, but in general, it is based on the idea that one begins by considering the most common diagnosis first: a head cold versus meningitis, for example. As a reminder, medical students are taught the Occam's razor adage, "When you hear hoofbeats, look for horses, not zebras," which means look for the simplest, most common explanation first. Only after ruling out the simplest diagnosis should the clinician consider more complex or exotic diagnoses.
Differential diagnosis has four steps. The physician:
- Gathers all information about the patient and creates a symptoms list. The list can be in writing or in the physician's head, as long as they make a list.
- Lists all possible causes (candidate conditions) for the symptoms. Again, this can be in writing or in the physician's head but it must be done.
- Prioritizes the list by placing the most urgently dangerous possible causes at the top of the list.
- Rules out or treats possible causes, beginning with the most urgently dangerous condition and working down the list. Rule out—practically—means use tests and other scientific methods to determine that a candidate condition has a clinically negligible probability of being the cause.
In some cases, there remains no diagnosis. This suggests the physician has made an error, or that the true diagnosis is unknown to medicine. The physician removes diagnoses from the list by observing and applying tests that produce different results, depending on which diagnosis is correct.
A mnemonic to help in considering multiple possible pathological processes is VINDICATE'M:
- Vascular
- Inflammatory/Infectious
- Neoplastic
- Degenerative/Deficiency/Drugs
- Idiopathic/Intoxication/Iatrogenic
- Congenital
- Autoimmune/Allergic/Anatomic
- Traumatic
- Endocrine/Environmental
- Metabolic[2]
Specific methods
There are several methods for differential diagnostic procedures, and several variants among those. Furthermore, a differential diagnostic procedure can be used concomitantly or alternately with protocols, guidelines, or other diagnostic procedures (such as pattern-recognition or using medical algorithms).
For example, in case of medical emergency, there may not be enough time to do any detailed calculations or estimations of different probabilities, in which case the ABC protocol (Airway, Breathing and Circulation) may be more appropriate. Later, when the situation is less acute, a more comprehensive differential diagnostic procedure may be adopted.
The differential diagnostic procedure may be simplified if a 'pathognomonic' sign or symptom is found (in which case it is almost certain that the target condition is present) or in the absence of a sine qua non sign or symptom (in which case it is almost certain that the target condition is absent).
A diagnostician can be selective, considering first those disorders that are more likely (a probabilistic approach), more serious if left undiagnosed and untreated (a prognostic approach), or more responsive to treatment if offered (a pragmatic approach).[3] Since the subjective probability of the presence of a condition is never exactly 100% or 0%, the differential diagnostic procedure may aim at specifying these various probabilities to form indications for further action.
The following are two methods of differential diagnosis, being based on epidemiology and likelihood ratios, respectively.
An epidemiology-based method
One method of performing a differential diagnosis by epidemiology aims to estimate the probability of each candidate condition by comparing their probabilities to have occurred in the first place in the individual. It is based on probabilities related both to the presentation (such as pain) and probabilities of the various candidate conditions (such as diseases).
Theory
The statistical basis for differential diagnosis is Bayes' theorem. As an analogy, when a dice has landed the outcome is certain by 100%, but the probability that it Would Have Occurred In the First Place (hereafter abbreviated WHOIFP) is still 1/6. In the same way, the probability that a presentation or condition would have occurred in the first place in an individual (WHOIFPI) is not same as the probability that the presentation or condition has occurred in the individual, because the presentation has occurred by 100% certainty in the individual. Yet, the contributive probability fractions of each condition are assumed the same, relatively:
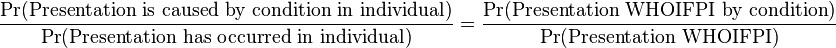
where:
- Pr(Presentation is caused by condition in individual) is the probability that the presentation is caused by condition in the individual
- condition without further specification refers to any candidate condition
- Pr(Presentation has occurred in individual) is the probability that the presentation has occurred in the individual, which can be perceived and thereby set at 100%
- Pr(Presentation WHOIFPI by condition) is the probability that the presentation Would Have Occurred in the First Place in the Individual by condition
- Pr(Presentation WHOIFPI) is the probability that the presentation Would Have Occurred in the First Place in the Individual
When an individual presents with a symptom or sign, Pr(Presentation has occurred in individual) is 100% and can therefore be replaced by 1, and can be ignored since division by 1 does not make any difference:

The total probability of the presentation to have occurred in the individual can be approximated as the sum of the individual candidate conditions:

Also, the probability of the presentation to have been caused by any candidate condition is proportional to the probability of the condition, depending on what rate it causes the presentation:
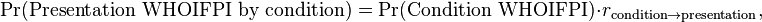
where:
- Pr(Presentation WHOIFPI by condition) is the probability that the presentation Would Have Occurred in the First Place in the Individual by condition
- Pr(Condition WHOIFPI) is the probability that the condition Would Have Occurred in the First Place in the Individual
- rCondition → presentation is the rate for which a condition causes the presentation, that is, the fraction of people with condition that manifest with the presentation.
The probability that a condition would have occurred in the first place in an individual is approximately equal to that of a population that is as similar to the individual as possible except for the current presentation, compensated where possible by relative risks given by known risk factor that distinguish the individual from the population:
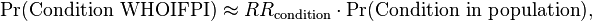
where:
- Pr(Condition WHOIFPI) is the probability that the condition Would Have Occurred in the First Place in the Individual
- RRcondition is the relative risk for condition conferred by known risk factors in the individual that are not present in the population
- Pr(Condition in population) is the probability that the condition occurs in a population that is as similar to the individual as possible except for the presentation
The following table demonstrates how these relations can be made for a series of candidate conditions:
| Candidate condition 1 | Candidate condition 2 | Candidate condition 3 | |
| Pr(Condition in population) | Pr(Condition 1 in population) | Pr(Condition 2 in population) | Pr(Condition 3 in population) |
| RRcondition | RR 1 | RR 2 | RR 3 |
| Pr(Condition WHOIFPI) | Pr(Condition 1 WHOIFPI) | Pr(Condition 2 WHOIFPI) | P(Condition 3 WHOIFPI) |
| rCondition → presentation | rCondition 1 → presentation | rCondition 2 → presentation | rCondition 3 → presentation |
| Pr(Presentation WHOIFPI by condition) | Pr(Presentation WHOIFPI by condition 1) | Pr(Presentation WHOIFPI by condition 2) | Pr(Presentation WHOIFPI by condition 3) |
| Pr(Presentation WHOIFPI) = the sum of the probabilities in row just above | |||
| Pr(Presentation is caused by condition in individual) | Pr(Presentation is caused by condition 1 in individual) | Pr(Presentation is caused by condition 2 in individual) | Pr(Presentation is caused by condition 3 in individual) |
One additional "candidate condition" is the instance of there being no abnormality, and the presentation is only a (usually relatively unlikely) appearance of a basically normal state. Its probability in the population (P(No abnormality in population)) is complementary to the sum of probabilities of "abnormal" candidate conditions.
Example
This example case demonstrates how this method is applied, but does not represent a guideline for handling similar real-world cases. Also, the example uses relatively specified numbers with sometimes several decimals, while in reality, there are often simply rough estimations, such as of likelihoods being very high, high, low or very low, but still using the general principles of the method.
For an individual (who becomes the "patient" in this example), a blood test of, for example, serum calcium shows a result above the standard reference range, which, by most definitions, classifies as hypercalcemia, which becomes the "presentation" in this case. A physician (who becomes the "diagnostician" in this example), who does not currently see the patient, gets to know about his finding.
By practical reasons, the physician considers that there is enough test indication to have a look at the patient’s medical records. For simplicity, let’s say that the only information given in the medical records is a family history of primary hyperparathyroidism (here abbreviated as PH), which may explain the finding of hypercalcemia. For this patient, let’s say that the resultant hereditary risk factor is estimated to confer a relative risk of 10 (RRPH = 10).
The physician considers that there is enough motivation to perform a differential diagnostic procedure for the finding of hypercalcemia. The main causes of hypercalcemia are primary hyperparathyroidism (PH) and cancer, so for simplicity, the list of candidate conditions that the physician could think of can be given as:
- Primary hyperparathyroidism (PH)
- Cancer
- Other diseases that the physician could think of (which is simply termed "other conditions" for the rest of this example)
- No disease (or no abnormality), and the finding is caused entirely by statistical variability
The probability that 'primary hyperparathyroidism' (PH) would have occurred in the first place in the individual (P(PH WHOIFPI)) can be calculated as follows:
Let’s say that the last blood test taken by the patient was half a year ago and was normal, and that the incidence of primary hyperparathyroidism in a general population that appropriately matches the individual (except for the presentation and mentioned heredity) is 1 in 4000 per year. Ignoring more detailed retrospective analyses (such as including speed of disease progress and lag time of medical diagnosis), the time-at-risk for having developed primary hyperparathyroidism can roughly be regarded as being the last half-year, because a previously developed hypercalcemia would probably have been caught up by the previous blood test. This corresponds to a probability of primary hyperparathyroidism (PH) in the population of:
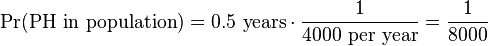
With the relative risk conferred from the family history, the probability that primary hyperparathyroidism (PH) would have occurred in the first place in the individual given from the currently available information becomes:
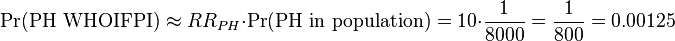
Primary hyperparathyroidism can be assumed to cause hypercalcemia essentially 100% of the time (rPH → hypercalcemia = 1), so this independently calculated probability of primary hyperparathyroidism (PH) can be assumed to be the same as the probability of being a cause of the presentation:
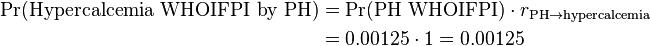
For cancer, the same time-at-risk is assumed for simplicity, and let’s say that the incidence of cancer in the area is estimated at 1 in 250 per year, giving an population probability of cancer of:
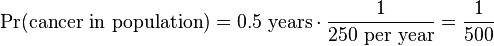
For simplicity, let’s say that any association between a family history of primary hyperparathyroidism and risk of cancer is ignored, so the relative risk for the individual to have contracted cancer in the first place is similar to that of the population (RRcancer = 1):
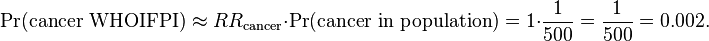
However, hypercalcemia only occurs in, very approximately, 10% of cancers,[4] (rcancer → hypercalcemia = 0.1), so:
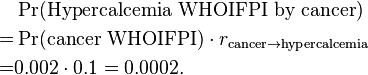
The probabilities that hypercalcemia would have occurred in the first place by other candidate conditions can be calculated in a similar manner. However, for simplicity, let’s say that the probability that any of these would have occurred in the first place is calculated at 0.0005 in this example.
For the instance of there being no disease, the corresponding probability in the population is complementary to the sum of probabilities for other conditions:

The probability that the individual would be healthy in the first place can be assumed to be the same:
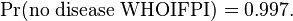
The rate at which the case of no abnormal condition still ends up in a measurement of serum calcium of being above the standard reference range (thereby classifying as hypercalcemia) is, by the definition of standard reference range, less than 2.5%. However, this probability can be further specified by considering how much the measurement deviates from the mean in the standard reference range. Let’s say that the serum calcium measurement was 1.30 mmol/L, which, with a standard reference range established at 1.05 to 1.25 mmol/L, corresponds to a standard score of 3 and a corresponding probability of 0.14% that such degree of hypercalcemia would have occurred in the first place in the case of no abnormality:
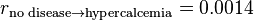
Subsequently, the probability that hypercalemia would have resulted from no disease can be calculated as:
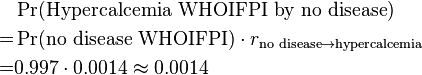
The probability that hypercalcemia would have occurred in the first place in the individual can thus be calculated as:
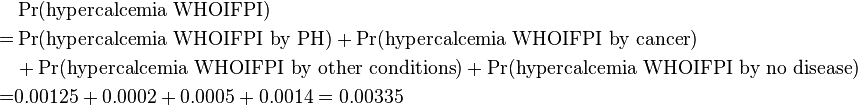
Subsequently, the probability that hypercalcemia is caused by primary hyperparathyroidism (PH) in the individual can be calculated as:
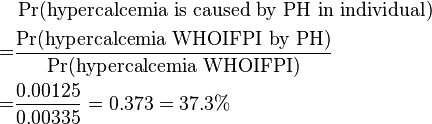
Similarly, the probability that hypercalcemia is caused by cancer in the individual can be calculated as:
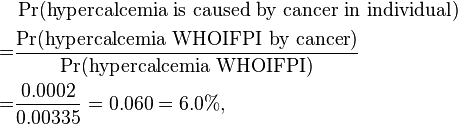
and for other candidate conditions:
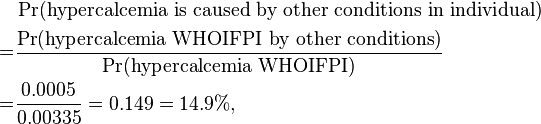
and the probability that there actually is no disease:
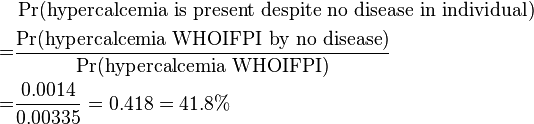
For clarification, these calculations are given as the table in the method description:
| PH | Cancer | Other conditions | No disease | |
| P(Condition in population) | 0.000125 | 0.002 | - | 0.997 |
| RRx | 10 | 1 | - | - |
| P(Condition WHOIFPI) | 0.00125 | 0.002 | - | - |
| rCondition →hypercalcemia | 1 | 0.1 | - | 0.0014 |
| P(hypercalcemia WHOIFPI by condition) | 0.00125 | 0.0002 | 0.0005 | 0.0014 |
| P(hypercalcemia WHOIFPI) = 0.00335 | ||||
| P(hypercalcemia is caused by condition in individual) | 37.3% | 6.0% | 14.9% | 41.8% |
Thus, this method estimates that the probabilities that the hypercalcemia is caused by primary hyperparathyroidism, cancer, other conditions or no disease at all are 37.3%, 6.0%, 14.9% and 41.8%, respectively, which may be used in estimating further test indications.
This case is continued in the example of the method described in the next section.
A likelihood ratio-based method
The procedure of differential diagnosis can become extremely complex when fully taking additional tests and treatments into consideration. One method that is somewhat a tradeoff between being clinically perfect and being relatively simple to calculate is one that uses likelihood ratios to derive subsequent post-test likelihoods.
Theory
The initial likelihoods for each candidate condition can be estimated by various methods, such as:
- By epidemiology as described in previous section.
- By clinic-specific pattern recognition, such as statistically knowing that patients coming into a particular clinic with a particular complaint statistically has a particular likelihood of each candidate condition.
One method of estimating likelihoods even after further tests uses likelihood ratios (which is derived from sensitivities and specificities) as a multiplication factor after each test or procedure. In an ideal world, sensitivities and specificities would be established for all tests for all possible pathological conditions. In reality, however, these parameters may only be established for one of the candidate conditions. Multiplying with likelihood ratios necessitates conversion of likelihoods from probabilities to odds in favor (hereafter simply termed “odds”) by:
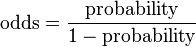
However, only the candidate conditions with known likelihood ratio need this conversion. After multiplication, conversion back to probability is calculated by:
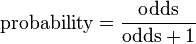
The rest of the candidate conditions (for which there is no established likelihood ratio for the test at hand) can, for simplicity, be adjusted by subsequently multiplying all candidate conditions with a common factor to again yield a sum of 100%.
The resulting probabilities are used for estimating the indications for further medical tests, treatments or other actions. If there is an indication for an additional test, and it returns with a result, then the procedure is repeated using the likelihood ratio of the additional test. With updated probabilities for each of the candidate conditions, the indications for further tests, treatments or other actions changes as well, and so the procedure can be repeated until an end point where there no longer is any indication for currently performing further actions. Such an end point mainly occurs when one candidate condition becomes so certain that no test can be found that is powerful enough to change the relative probability-profile enough to motivate any change in further actions. Tactics for reaching such an end point with as few tests as possible includes making tests with high specificity for conditions of already outstandingly high profile-relative probability, because the high likelihood ratio positive for such tests is very high, bringing all less likely conditions to relatively lower probabilities. Alternatively, tests with high sensitivity for competing candidate conditions have a high likelihood ratio negative, potentially bringing the probabilities for competing candidate conditions to negligible levels. If such negligible probabilities are achieved, the physician can rule out these conditions, and continue the differential diagnostic procedure with only the remaining candidate conditions.
Example
This example continues for the same patient as in the example for the epidemiology-based method. As with the previous example of epidemiology-based method, this example case is made to demonstrate how this method is applied, but does not represent a guideline for handling similar real-world cases. Also, the example uses relatively specified numbers, while in reality, there are often just rough estimations. In this example, the probabilities for each candidate condition were established by an epidemiology-based method to be as follows:
| PH | Cancer | Other conditions | No disease | |
| Probability | 37.3% | 6.0% | 14.9% | 41.8% |
These percentages could also have been established by experience at the particular clinic by knowing that these are the percentages for final diagnosis for people presenting to the clinic with hypercalcemia and having a family history of primary hyperparathyroidism.
The condition of highest profile-relative probability (except “no disease”) is primary hyperparathyroidism (PH), but cancer is still of major concern, because if it is the actual causative condition for the hypercalcemia, then the choice of whether to treat or not likely means life or death for the patient, in effect potentially putting the indication at a similar level for further tests for both of these conditions.
Here, let’s say that the physician considers the profile-relative probabilities of being of enough concern to indicate sending the patient a call for a doctor's visit, with an additional visit to the medical laboratory for an additional blood test complemented with further analyses, including parathyroid hormone for the suspicion of primary hyperparathyroidism.
For simplicity, let’s say that the doctor first receives the blood test (in formulas abbreviated as “BT”) result for the parathyroid hormone analysis, and that it showed a parathyroid hormone level that is elevated relatively to what would be expected by the calcium level.
Such a constellation can be estimated to have a sensitivity of approximately 70% and a specificity of approximately 90% for primary hyperparathyroidism.[5] This confers a likelihood ratio positive of 7 for primary hyperparathyroidism.
The probability of primary hyperparathyroidism is now termed Pre-BTPH because it corresponds to before the blood test (Latin preposition prae means before). It was estimated at 37.3%, corresponding to an odds of 0.595. With the likelihood ratio positive of 7 for the blood test, the post-test odds is calculated as:
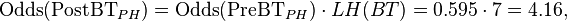
where:
- Odds(PostBTPH) is the odds for primary hyperparathyroidism after the blood test for parathyroid hormone
- Odds(PreBTPH is the odds in favor of primary hyperparathyroidism before the blood test for parathyroid hormone
- LH(BT) is the likelihood ratio positive for the blood test for parathyroid hormone
An Odds(PostBTPH) of 4.16 is again converted to the corresponding probability by:
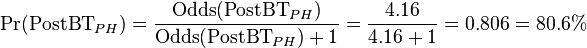
The sum of the probabilities for the rest of the candidate conditions should therefore be:
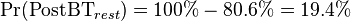
Before the blood test for parathyroid hormone, the sum of their probabilities were:
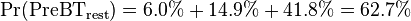
Therefore, to conform to a sum of 100% for all candidate conditions, each of the other candidates must be multiplied by a correcting factor:
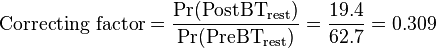
For example, the probability of cancer after the test is calculated as:
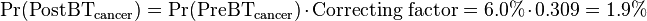
The probabilities for each candidate conditions before and after the blood test are given in following table:
| PH | Cancer | Other conditions | No disease | |
| P(PreBT) | 37.3% | 6.0% | 14.9% | 41.8% |
| P(PostBT) | 80.6% | 1.9% | 4.6% | 12.9% |
These “new” percentages, including a profile-relative probability of 80% for primary hyperparathyroidism, underlie any indications for further tests, treatments or other actions. In this case, let's say that the physician continues the plan for the patient to attend a doctor's visit for further checkup, especially focused at primary hyperparathyroidism.
A doctor's visit can, theoretically, be regarded as a series of tests, including both questions in a medical history as well as components of a physical examination, where the post-test probability of a previous test can be used as the pre-test probability of the next. The indications for choosing the next test is dynamically influenced by the results of previous tests.
Let's say that the patient in this example is revealed to have at least some of the symptoms and signs of depression, bone pain, joint pain or constipation of more severerity than what would be expected by the hypercalcemia itself, supporting the suspicion of primary hyperparathyroidism,[6] and let's say that the likelihood ratios for the tests, when multiplied together, roughly results in a product of 6 for primary hyperparathyroidism.
The presence of unspecific pathologic symptoms and signs in the history and examination are often concurrently indicative of cancer as well, and let's say that the tests gave an overall likelihood ratio estimated at 1.5 for cancer. For other conditions, as well as the instance of not having any disease at all, let’s say that it’s unknown how they are affected by the tests at hand, as often happens in reality. This gives the following results for the history and physical examination (abbreviated as P&E):
| PH | Cancer | Other conditions | No disease | |
| P(PreH&E) | 80.6% | 1.9% | 4.6% | 12.9% |
| Odds(PreH&E) | 4.15 | 0.019 | 0.048 | 0.148 |
| Likelihood ratio by H&E | 6 | 1.5 | - | - |
| Odds(PostH&E) | 24.9 | 0.0285 | - | - |
| P(PostH&E) | 96.1% | 2.8% | - | - |
| Sum of known P(PostH&E) | 98.9% | |||
| Sum of the rest P(PostH&E) | 1.1% | |||
| Sum of the rest P(PreH&E) | 4.6% + 12.9% = 17.5% | |||
| Correcting factor | 1.1% / 17.5% = 0.063 | |||
| After correction | - | - | 0.3% | 0.8% |
| P(PostH&E) | 96.1% | 2.8% | 0.3% | 0.8% |
These probabilities after the history and examination may make the physician confident enough to plan the patient for surgery for a parathyroidectomy to resect the affected tissue.
At this point, the probability of "other conditions" is so low that the physician cannot think of any test for them that could make a difference that would be substantial enough to form an indication for such a test, and the physician thereby practically regards "other conditions" as ruled out, in this case not primarily by any specific test for such other conditions that were negative, but rather by the absence of positive tests so far.
For "cancer", the cutoff at which to confidently regard it as ruled out may be more stringent because of severe consequences of missing it, so the physician may consider that at least a histopathologic examination of the resected tissue is indicated.
This case is continued in the example of Combinations in corresponding section below.
Coverage of candidate conditions
The validity of both the initial estimation of probabilities by epidemiology and further workup by likelihood ratios are dependent of inclusion of candidate conditions that are responsible for as large part as possible of the probability of having developed the condition, and it's clinically important to include those where relatively fast initiation of therapy is most likely to result in greatest benefit. If an important candidate condition is missed, no method of differential diagnosis will supply the correct conclusion. The need to find more candidate conditions for inclusion increases with increasing severity of the presentation itself. For example, if the only presentation is a deviating laboratory parameter and all common harmful underlying conditions have been ruled out, then it may be acceptable to stop finding more candidate conditions, but this would much more likely be unacceptable if the presentation would have been severe pain.
Combinations
If two conditions get high post-test probabilities, especially if the sum of the probabilities for conditions with known likelihood ratios become higher than 100%, then there is an the actual condition consists of a combination of the two. In such cases, that combined condition can be added to the list of candidate condition, and the calculations should start over from the beginning.
To continue the example used above, let's say that the history and physical examination was indicative of cancer as well, with a likelihood ratio of 3, giving an Odds(PostH&E) of 0.057, corresponding to a P(PostH&E) of 5.4%. This would correspond to a “Sum of known P(PostH&E)” of 101.5%. This is an indication for considering a combination of primary hyperparathyroidism and cancer, such as, in this case, a parathyroid hormone-producing parathyroid carcinoma. A recalculation may therefore be needed, with the first two conditions being separated into “primary hyperparathyroidism without cancer”, “cancer without primary hyperparathyroidism” as well as “combined primary hyperparathyroidism and cancer”, and likelihood ratios being applied to each condition separately. In this case, however, tissue has already been resected, wherein a histopathologic examination can be performed that includes the possibility of parathyroid carcinoma in the examination (which may entail appropriate sample staining). Let’s say that the histopathologic examination confirms primary hyperparathyroidism, but also showed a malignant pattern. By an initial method by epidemiology, the incidence of parathyroid carcinoma is estimated at about 1 in 6 million people per year,[7] giving a very low probability before taking any tests into consideration. In comparison, the probability that a non-malignant primary hyperparathyroidism would have occurred at the same time as an unrelated non-carcinoma cancer that presents with malignant cells in the parathyroid gland is calculated by multiplying the probabilities of the two. The resultant probability is, however, much smaller than the 1 in 6 million. Therefore, the probability of parathyroid carcinoma may still be close to 100% after histopathologic examination despite the low probability of occurring in the first place.
Let's finally say that the diagnosis of parathyroid carcinoma resulted in an extended surgery that removed remaining malignant tissue before it had metastasized, and the patient lived happily ever after.
Machine differential diagnosis
Machine differential diagnosis is the use of computer software to partly or fully make a differential diagnosis. It may be regarded as an application of artificial intelligence.
Many studies demonstrate improvement of quality of care and reduction of medical errors by using such decision support systems. Some of these systems are designed for a specific medical problem such as schizophrenia,[8] Lyme disease[9] or ventilator-associated pneumonia.[10] Others such as ESAGIL,[11] Iliad, QMR, DiagnosisPro,[12] VisualDx,[13] Isabel,[14] ZeroMD,[15] DxMate,[16] and Physician Cognition[17] are designed to cover all major clinical and diagnostic findings to assist physicians with faster and more accurate diagnosis.
However, these tools all still require advanced medical skills to rate symptoms and choose additional tests to deduce the probabilities of different diagnoses. Thus, non-professionals should still see a health care provider for a proper diagnosis.
History
The method of differential diagnosis was first suggested for use in the diagnosis of mental disorders by Emil Kraepelin. It is more systematic than the old-fashioned method of diagnosis by gestalt (impression).
Alternative medical meanings
'Differential diagnosis' is also used more loosely, to refer simply to a list of the most common causes of a given symptom, to a list of disorders similar to a given disorder, or to such lists when they are annotated with advice on how to narrow the list down (the book 'French's Index of Differential Diagnosis', ISBN 0-340-81047-5, is an example). Thus, a differential diagnosis in this sense is medical information specially organized to aid in diagnosis.
Usage apart from in medicine
Methods similar to those of differential diagnostic processes in medicine are also is used by biological taxonomists to identify and classify organisms, living and extinct. For example, after finding an unknown species, there can first be a listing of all potential species, followed by ruling out of one by one until, optimally, only one potential choice remains.
See also
- Comorbidity
- Diagnosis of exclusion
- Dual diagnosis
- Gender-bias in medical diagnosis
- List of medical symptoms
References
- ↑ "differential diagnosis". Merriam-Webster (Medical dictionary). Retrieved 30 December 2014.
- ↑ Cf. VINDICATE – Mnemonic for differential diagnosis at PG Blazer.com.
- ↑ Richardson, WS. (Mar 1999). "Users' Guides to the Medical Literature: XV. How to use an article about disease probability for differential diagnosis.". JAMA 281 (13): 1214–1219. doi:10.1001/jama.281.13.1214. PMID 10199432.
- ↑ Seccareccia, D. (Mar 2010). "Cancer-related hypercalcemia.". Can Fam Physician 56 (3): 244–6, e90–2. PMC 2837688. PMID 20228307.
- ↑ Lepage, R.; d'Amour, P.; Boucher, A.; Hamel, L.; Demontigny, C.; Labelle, F. (1988). "Clinical performance of a parathyrin immunoassay with dynamically determined reference values". Clinical Chemistry 34 (12): 2439–2443. PMID 3058363.
- ↑ Bargren, A. E.; Repplinger, D.; Chen, H.; Sippel, R. S. (2011). "Can Biochemical Abnormalities Predict Symptomatology in Patients with Primary Hyperparathyroidism?". Journal of the American College of Surgeons 213 (3): 410–414. doi:10.1016/j.jamcollsurg.2011.06.401. PMID 21723154.
- ↑ Parathyroid Cancer Treatment at National Cancer Institute. Last Modified: 03/11/2009
- ↑ Razzouk, D.; Mari, J. J.; Shirakawa, I.; Wainer, J.; Sigulem, D. (January 2006). "Decision support system for the diagnosis of schizophrenia disorders". Brazilian Journal of Medical and Biological Research 39 (1): 119–28. doi:10.1590/s0100-879x2006000100014. PMID 16400472.
- ↑ Hejlesen OK, Olesen KG, Dessau R, Beltoft I, Trangeled M (2005). "Decision support for diagnosis of lyme disease". Studies in Health Technology and Informatics 116: 205–10. PMID 16160260.
- ↑ "Evaluation of a Computer Assisted Decision Support System (DSS) for Diagnosis and Treatment of Ventilator Associated Pneumonia (VAP) in Intensive Care Unit (ICU).". nih.gov. Retrieved 3 October 2008.
- ↑ esagil.org
- ↑ "DiagnosisPro differential diagnosis reminder tool". diagnosispro.com. Retrieved 3 October 2008.
- ↑ visualdx.com
- ↑ isabelhealthcare.com
- ↑ "ZeroMD Diagnosis Tool and Community". www.ZeroMD.com. Retrieved 12 July 2013.
- ↑ dxmate.com
- ↑ physiciancognition.com
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||