Devanagari
| Devanagari देवनागरी | |
|---|---|
|
Devanagari script (vowels top, consonants bottom) in Chandas font. | |
| Type | |
| Languages | Several languages of India and Nepal, including, Hindi, Marathi, Nepali, Pali, Konkani, Bodo, Maithili, Sindhi and Sanskrit. Formerly used to write Punjabi and Gujarati. |
Time period | c. 1st century CE – present[1][2][3] |
Parent systems | |
Child systems |
Gujarati Moḍī |
Sister systems | Gurmukhi, Nandinagari |
| Direction | Left-to-right |
| ISO 15924 |
Deva, 315 |
Unicode alias | Devanagari |
|
U+0900–U+097F Devanagari, U+A8E0–U+A8FF Devanagari Extended, U+1CD0–U+1CFF Vedic Extensions | |

| Devanagari |
|---|
| Vowels |
| Diacritics |
|
| Consonants |
| Brahmic scripts |
|---|
| The Brahmic script and its descendants |
|
Northern Brahmic
|
Devanagari (/ˌdeɪvəˈnɑːɡəriː/ DAY-və-NAH-gər-ee; Hindustani: [d̪eːʋˈnaːɡri]; देवनागरी devanāgarī a compound of "deva" [देव] and "nāgarī" [नागरी]), also called Nagari (Nāgarī, नागरी),[4] is an abugida (alphasyllabary) alphabet of India and Nepal. It is written from left to right, has a strong preference for symmetrical rounded shapes within squared outlines, and is recognisable by a horizontal line that runs along the top of full letters.[5] In a cursory look, the Devanagari script appears different from other Indic scripts such as Bangla, Oriya or Gurmukhi, but a closer examination reveals they are very similar except for angles and structural emphasis.[5]
The Nagari script has roots in the ancient Brahmi script family.[6] Some of the earliest epigraphical evidence attesting to the developing Sanskrit Nagari script in ancient India, in a form similar to Devanagari, is from the 1st to 4th century CE inscriptions discovered in Gujarat.[2] The Nagari script was in regular use by the 7th century CE and fully it was developed by about the end of first millennium.[4][7] The use of Sanskrit in Nagari script in medieval India is attested by numerous pillar and cave temple inscriptions, including the 11th-century Udayagiri inscriptions in Madhya Pradesh,[8] a brick with inscriptions found in Uttar Pradesh, dated to be from 1217 CE, which is now held at the British Museum.[9] The script's proto- and related versions have been discovered in ancient relics outside of India, such as in Sri Lanka, Myanmar and Indonesia; while in East Asia, Siddha Matrika script considered as the closest precursor to Nagari was in use by Buddhists.[10][11] Nagari has been the primus inter pares of the Indic scripts.[10]
The Devanagari script is used for over 120 languages,[12] including Hindi,[13] Marathi, Nepali, Pali, Konkani, Bodo, Sindhi and Maithili among other languages and dialects, making it one of the most used and adopted writing systems in the world.[14] The Devanagari script is also used for classical Sanskrit texts.[12] The Devanagari script is closely related to the Nandinagari script commonly found in numerous ancient manuscripts of South India,[15][16] and it is distantly related to a number of southeast Asian scripts.[12]
Devanagari script has forty-seven primary characters, of which fourteen are vowels and thirty-three are consonants.[10] The ancient Nagari script for Sanskrit had two additional consonantal characters.[10] The script has no capital or small letters as in Latin, and weighs all characters as equal.[17] Generally the orthography of the script reflects the pronunciation of the language.[12]
Origins

Devanagari is part of the Brahmic family of scripts of Nepal, India, Tibet, and South-East Asia.[18] It is a descendant of the Gupta script, along with Siddham and Sharada.[18] Variants of script called Nāgarī, recognizably close to Devanagari, are first attested from the 1st century CE Rudradaman inscriptions in Sanskrit, while the modern standardized form of Devanagari was in use by about 1000 AD.[7][19] Medieval inscriptions suggest widespread diffusion of the Nagari-related scripts, with biscripts presenting local script along with the adoption of Nagari scripts. For example, the mid 8th century Pattadakal pillar in Karnataka has text in both Siddha Matrika script, and an early Telugu-Kannada script; while, the Kangra Jvalamukhi inscription in Himachal Pradesh is written in both Sharada and Devanagari scripts.[20]

The Tibetan king Srong-tsan-gambo of 7th century ordered that all foreign books be transcribed into Tibetan language, sent his ambassador Tonmi Sambota to India to acquire alphabet and writing methods, who returned with Sanskrit Nagari script from Kashmir corresponding to 24 Tibetan sounds and innovating new symbols for 6 local sounds.[21] Other closely related scripts such as Siddham Matrka was in use in Indonesia, Vietnam, Japan and other parts of East Asia by between 7th- to 10th-century.[22][23] Sharada remained in parallel use in Kashmir. An early version of Devanagari is visible in the Kutila inscription of Bareilly dated to Vikram Samvat 1049 (i.e. 992 CE), which demonstrates the emergence of the horizontal bar to group letters belonging to a word.[1] One of the oldest surviving Sanskrit text from early post-Maurya period available consists of 1,413 Nagari pages of a commentary by Patanjali, with a composition date of about 150 BCE, the surviving copy transcribed about 14th century CE.[24]
Nāgarī is the Sanskrit feminine of Nāgara "relating or belonging to a town or city, urban". It is a phrasing with lipi ("script") as nāgarī lipi "script relating to a city", or "spoken in city".[25]
The use of the name devanāgarī is relatively recent, and the older term nāgarī is still common.[18] The rapid spread of the term devanāgarī may be related to the almost exclusive use of this script to publish Sanskrit texts in print since the 1870s.[18]
Principle
As a Brahmic abugida, the fundamental principle of Devanagari is that each letter represents a consonant, which carries an inherent schwa vowel. This is usually written in Latin as a, though it is represented as [ə] in the International Phonetic Alphabet.[26] The letter क is read ka, the two letters कन are kana, the three कनय are kanaya, etc. Other vowels, or the absence of vowels, require modification of these consonants or their own letters:

- A final consonant is marked with the diacritic ्, called the virāma in Sanskrit, halant in Hindi, and occasionally a "killer stroke" in English. This cancels the inherent vowel, so that from क्नय knaya is derived क्नय् knay. The halant is often used for consonant clusters when typesetting conjunct ligatures is not feasible.
- Consonant clusters are written with ligatures (saṃyuktākṣara "conjuncts"). For example, the three consonants क्, न्, and य्, (k, n, y), when written consecutively without virāma form कनय, as shown above. Alternatively, they may be joined as clusters to form क्नय knaya, कन्य kanya, or क्न्य knya. This system was originally created for use with the Middle Indo-Aryan languages, which have a very limited number of clusters (the only clusters allowed are geminate consonants and clusters involving homorganic nasal stops). When applied to Sanskrit, however, it added a great deal of complexity to the script, due to the large variety of clusters in this language (up to five consonants, e.g. rtsny). Much of this complexity is required at least on occasion in the modern Indo-Aryan languages, due to the large number of clusters allowed and especially due to borrowings from Sanskrit.
- Vowels other than the inherent a are written with diacritics (termed matras). For example, using क ka, the following forms can be derived: के ke, कु ku, की kī, का kā, etc.
- For vowels as an independent syllable (in writing, unattached to a preceding consonant), either at the beginning of a word or (in Hindi) after another vowel, there are full-letter forms. For example, while the vowel ū is written with the diacritic ू in कू kū, it has its own letter ऊ in ऊक ūka and (in Hindi but not Sanskrit) कऊ kaū.
Such a letter or ligature, with its diacritics, is called an akṣara "syllable". For example, कनय kanaya is written with what are counted as three akshara, whereas क्न्य knya and कु ku are each written with one.
When handwriting, letters are usually written without the distinctive horizontal bar, which is added only once the word is completed.[27]
Letters
The letter order of Devanagari, like nearly all Brahmic scripts, is based on phonetic principles that consider both the manner and place of articulation of the consonants and vowels they represent. This arrangement is usually referred to as the varṇamālā "garland of letters".[28] The format of Devanagari for Sanskrit serves as the prototype for its application, with minor variations or additions, to other languages.[29]
Vowels
The vowels and their arrangement are:[30]
| Independent form | Romanised | As diacritic with प | Independent form | Romanised | As diacritic with प | ||
|---|---|---|---|---|---|---|---|
| kaṇṭhya (Guttural) |
अ | a | प | आ | ā | पा | |
| tālavya (Palatal) |
इ | i | पि | ई | ī | पी | |
| oṣṭhya (Labial) |
उ | u | पु | ऊ | ū | पू | |
| mūrdhanya (Retroflex) |
ऋ | ṛ | पृ | ॠ | ṝ | पॄ | |
| dantya (Dental) |
ऌ | ḷ | पॢ | ॡ | ḹ | पॣ | |
| kaṇṭhatālavya (Palatoguttural) |
ए | e | पे | ऐ | ai | पै | |
| kaṇṭhoṣṭhya (Labioguttural) |
ओ | o | पो | औ | au | पौ | |
| अं | aṃ | पं | अः | aḥ | पः |
- Arranged with the vowels are two consonantal diacritics, the final nasal anusvāra ं ṃ and the final fricative visarga ः ḥ (called अं aṃ and अः aḥ). Masica (1991:146) notes of the anusvāra in Sanskrit that "there is some controversy as to whether it represents a homorganic nasal stop [...], a nasalised vowel, a nasalised semivowel, or all these according to context". The visarga represents post-vocalic voiceless glottal fricative [h], in Sanskrit an allophone of s, or less commonly r, usually in word-final position. Some traditions of recitation append an echo of the vowel after the breath:[31] इः [ihi]. Masica (1991:146) considers the visarga along with letters ङ ṅa and ञ ña for the "largely predictable" velar and palatal nasals to be examples of "phonetic overkill in the system".
- Another diacritic is the candrabindu/anunāsika ँ अँ. Salomon (2003:76–77) describes it as a "more emphatic form" of the anusvāra, "sometimes [...] used to mark a true [vowel] nasalization". In a New Indo-Aryan language such as Hindi the distinction is formal: the candrabindu indicates vowel nasalisation[32] while the anusvār indicates a homorganic nasal preceding another consonant:[33] e.g. हँसी [ɦə̃si] "laughter", गंगा [ɡəŋɡɑ] "the Ganges". When an akshara has a vowel diacritic above the top line, that leaves no room for the candra ("moon") stroke candrabindu, which is dispensed with in favour of the lone dot:[34] हूँ [ɦũ] "am", but हैं [ɦɛ̃] "are". Some writers and typesetters dispense with the "moon" stroke altogether, using only the dot in all situations.[35]
- The avagraha ऽ अऽ (usually transliterated with an apostrophe) is a Sanskrit punctuation mark for the elision of a vowel in sandhi: एकोऽयम् eko'yam ( ← ekas + ayam) "this one". An original long vowel lost to coalescence is sometimes marked with a double avagraha: सदाऽऽत्मा sadā'tmā ( ← sadā + ātmā) "always, the self".[36] In Hindi, Snell (2000:77) states that its "main function is to show that a vowel is sustained in a cry or a shout": आईऽऽऽ! āīīī!. In Madhyadeshi Languages like Bhojpuri, Awadhi, Maithili, etc. which have "quite a number of verbal forms [that] end in that inherent vowel",[37] the avagraha is used to mark the non-elision of word-final inherent a, which otherwise is a modern orthographic convention: बइठऽ baiṭha "sit" versus *बइठ baiṭh
- The syllabic consonants ṝ, ḷ, and ḹ are specific to Sanskrit and not included in the varṇamālā of other languages. The sound represented by ṛ has also been lost in the modern languages, and its pronunciation now ranges from [ɾɪ] (Hindi) to [ɾu] (Marathi).
- ḹ is not an actual phoneme of Sanskrit, but rather a graphic convention included among the vowels in order to maintain the symmetry of short–long pairs of letters.[29]
- There are non-regular formations of रु ru and रू rū.
Consonants
The table below shows the consonant letters (in combination with inherent vowel a) and their arrangement. To the right of the Devanagari letter it shows the scientific transcription (IAST), and the phonetic value (IPA).[38]
| sparśa (Plosive) |
anunāsika (Nasal) |
antastha (Approximant) |
ūṣma/saṃghaṣhrī (Fricative) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Voicing → | aghoṣa | ghoṣa | aghoṣa | ghoṣa | ||||||||||||
| Aspiration → | alpaprāṇa | mahāprāṇa | alpaprāṇa | mahāprāṇa | alpaprāṇa | mahāprāṇa | ||||||||||
| kaṇṭhya (Guttural) |
क | ka /k/ |
ख | kha /kʰ/ |
ग | ga /ɡ/ |
घ | gha /ɡʱ/ |
ङ | ṅa /ŋ/ |
ह | ha /ɦ/ | ||||
| tālavya (Palatal) |
च | ca /c, t͡ʃ/ |
छ | cha /cʰ, t͡ʃʰ/ |
ज | ja /ɟ, d͡ʒ/ |
झ | jha /ɟʱ, d͡ʒʱ/ |
ञ | ña /ɲ/ |
य | ya /j/ |
श | śa /ɕ, ʃ/ |
||
| mūrdhanya (Retroflex) |
ट | ṭa /ʈ/ |
ठ | ṭha /ʈʰ/ |
ड | ḍa /ɖ/ |
ढ | ḍha /ɖʱ/ |
ण | ṇa /ɳ/ |
र | ra /ɲ/ |
ष | ca /ʂ/ | ||
| dantya (Dental) |
त | ta /t̪/ |
थ | tha /t̪ʰ/ |
द | da /d̪/ |
ध | dha /d̪ʱ/ |
न | na /n/ |
ल | la /l/ |
स | sa /ɳ/ | ||
| oṣṭhya (Labial) |
प | pa /p/ |
फ | pha /pʰ/ |
ब | ba /b/ |
भ | bha /bʱ/ |
म | ṭa /m/ |
व | va /w, ʋ/ |
||||
- Rounding this out where applicable is ळ ḷa /Retroflex lateral flap / (also /ɭ̆/ in IPA), the intervocalic lateral flap allophone of the voiced retroflex stop in Vedic Sanskrit, which is a phoneme in languages such as Marathi, Konkani, and Rajasthani.[39]
- Beyond the Sanskritic set, new shapes have rarely been formulated. Masica (1991:146) offers the following, "In any case, according to some, all possible sounds had already been described and provided for in this system, as Sanskrit was the original and perfect language. Hence it was difficult to provide for or even to conceive other sounds, unknown to the phoneticians of Sanskrit". Where foreign borrowings and internal developments did inevitably accrue and arise in New Indo-Aryan languages, they have been ignored in writing, or dealt through means such as diacritics and ligatures (ignored in recitation).
- The most prolific diacritic has been the subscript dot (nuqtā) ़. Hindi uses it for the Persian, Arabic and English sounds क़ qa /qä/, ख़ xa /xä/, ग़ ġa /ɣä/, ज़ za /zä/, श़ or झ़ zha /ʒä/, and फ़ fa /fä/, and for the allophonic developments ड़ ṛa /ɽä/ and ढ़ ṛha /ɽʱä/. (Although ऴ ḷha /ɭʱä/ could also exist there is no use of it in Hindi.)
- Sindhi's and Saraiki's implosives are accommodated with a line attached below: ॻ [ɠə], ॼ [ʄə], ॾ [ɗə], ॿ [ɓə].
- Aspirated sonorants may be represented as conjuncts/ligatures with ह ha: म्ह mha, न्ह nha, ण्ह ṇha, व्ह vha, ल्ह lha, ळ्ह ḷha, र्ह rha.
- Masica (1991:147) notes Marwari as using ॸ for ḍa [ɗə] (while ड represents [ɽə]).
For a list of the 297 (33×9) possible Sanskrit consonant-(short) vowel phonemes, see Āryabhaṭa numeration.
Schwa syncope in consonants
In many Indo-Aryan languages, the schwa ('ə') implicit in each consonant of the script is "obligatorily deleted" at the end of words and in certain other contexts,[40] unlike in Marathi or Sanskrit. This phenomenon has been termed the "schwa syncope rule" or the "schwa deletion rule" of Hindi.[40][41] One formalisation of this rule has been summarised as ə → ∅ | VC_CV. In other words, when a schwa-succeeded consonant is followed by a vowel-succeeded consonant, the schwa inherent in the first consonant is deleted.[41][42] However, this formalisation is inexact and incomplete (it sometimes deletes a schwa when it should not and, at other times, it fails to delete it when it should) and can cause errors. Schwa deletion is computationally important because it is essential to building text-to-speech software for Hindi.[42][43]
As a result of schwa syncope, the Hindi pronunciation of many words differs from that expected from a literal Sanskrit-style rendering of Devanagari. For instance, राम is rām (not rāma), रचना is racnā (not racanā), वेद is vēd (not vēda) and नमकीन is namkīn (not namakīna).[42][43] The name of the script itself is pronounced devnāgrī (not devanāgarī).[44]
Correct schwa deletion is also critical because, in some cases, the same Devanagari letter sequence is pronounced two different ways in Hindi depending on context, and failure to delete the appropriate schwas can change the sense of the word.[45] For instance, the letter sequence 'रक' is pronounced differently in हरकत (harkat, meaning movement or activity) and सरकना (saraknā, meaning to slide). Similarly, the sequence धड़कने in दिल धड़कने लगा (the heart started beating) and in दिल की धड़कनें (beats of the heart) is identical prior to the nasalisation in the second usage. Yet, it is pronounced dhaṛaknē in the first and dhaṛkanē in the second.[45] While native speakers correctly pronounce the sequences differently in different contexts, non-native speakers and voice-synthesis software can make them "sound very unnatural", making it "extremely difficult for the listener" to grasp the intended meaning.[45]
Allophony of 'v' and 'w' in Hindi
[v] (the voiced labiodental fricative) and [w] (the voiced labio-velar approximant) are both allophones of the single phoneme represented by the letter 'व' in Hindi Devanagari. More specifically, they are conditional allophones, i.e. rules apply on whether 'व' is pronounced as [v] or [w] depending on context. Native Hindi speakers pronounce 'व' as [v] in vrat (व्रत, fast) and [w] in pakvān (पकवान, food dish), perceiving them as a single phoneme and without being aware of the allophone distinctions they are systematically making.[46] However, this specific allophony can become obvious when speakers switch languages. Non-native speakers of Hindi might pronounce 'व' in 'व्रत' as [w], i.e. as wrat instead of the more correct vrat. This results in a minor intelligibility problem because wrat can easily be confused for aurat, which means woman, instead of the intended fast (abstaining from food), in Hindi.[46]
Conjuncts
- You will be able to see the ligatures only if your system has a Unicode font installed that includes the required ligature glyphs (such as one of the TDIL[47] fonts, see "external links" below).
As mentioned, successive consonants lacking a vowel in between them may physically join together as a conjunct or ligature. Conjuncts are used mostly with loan words. Native words typically use the basic consonant and native speakers know to suppress the vowel. For example, the native Hindi word karnā is written करना (ka-ra-nā).[48] The government of these clusters ranges from widely to narrowly applicable rules, with special exceptions within. While standardised for the most part, there are certain variations in clustering, of which the Unicode used on this page is just one scheme. The following are a number of rules:
- 24 out of the 36 consonants contain a vertical right stroke (ख, घ, ण etc.). As first or middle fragments/members of a cluster, they lose that stroke. e.g. त + व = त्व tva, ण + ढ = ण्ढ ṇḍha, स + थ = स्थ stha. In Unicode, these consonants without their vertical stems are called half forms.[49] श ś(a) appears as a different, simple ribbon-shaped fragment preceding व va, न na, च ca, ल la, and र ra, causing these second members to be shifted down and reduced in size. Thus श्व śva, श्न śna, श्च śca श्ल śla, and श्र śra.
- र r(a) as a first member takes the form of a curved upward dash above the final character or its ā-diacritic. e.g. र्व rva, र्वा rvā, र्स्प rspa, र्स्पा rspā. As a final member with ट ठ ड ढ ङ छ it is two lines below the character, pointed downwards and apart. Thus ट्र ठ्र ड्र ढ्र ङ्र छ्र. Elsewhere as a final member it is a diagonal stroke extending leftwards and down. e.g. क्र ग्र भ्र. त ta is shifted up to make त्र tra.
- As first members, remaining characters lacking vertical strokes such as द d(a) and ह h(a) may have their second member, reduced in size and lacking its horizontal stroke, placed underneath. क k(a), छ ch(a), and फ ph(a) shorten their right hooks and join them directly to the following member.
- The conjuncts for kṣ and jñ are not clearly derived from the letters making up their components. The conjunct for kṣ is क्ष (क् + ष) and for jñ it is ज्ञ (ज् + ञ).
The table below shows all the 1296 viable symbols for the biconsonantal clusters formed by collating the 36 fundamental symbols of Sanskrit as listed in Masica (1991:161–162). Scroll your cursor over the conjuncts to reveal their romanizations (in ISO 15919[50]) and IPA transcriptions. Note that not all these conjuncts appear in genuine words.
Biconsonantal conjuncts
| क | ख | ग | घ | ङ | च | छ | ज | झ | ञ | ट | ठ | ड | ढ | ण | त | थ | द | ध | न | प | फ | ब | भ | म | य | र | ल | व | श | ष | स | ह | ळ | क्ष | ज्ञ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| क | क्क | क्ख | क्ग | क्घ | क्ङ | क्च | क्छ | क्ज | क्झ | क्ञ | क्ट | क्ठ | क्ड | क्ढ | क्ण | क्त | क्थ | क्द | क्ध | क्न | क्प | क्फ | क्ब | क्भ | क्म | क्य | क्र | क्ल | क्व | क्श | क्ष | क्स | क्ह | क्ळ | क्क्ष | क्ज्ञ |
| ख | ख्क | ख्ख | ख्ग | ख्घ | ख्ङ | ख्च | ख्छ | ख्ज | ख्झ | ख्ञ | ख्ट | ख्ठ | ख्ड | ख्ढ | ख्ण | ख्त | ख्थ | ख्द | ख्ध | ख्न | ख्प | ख्फ | ख्ब | ख्भ | ख्म | ख्य | ख्र | ख्ल | ख्व | ख्श | ख्ष | ख्स | ख्ह | ख्ळ | ख्क्ष | ख्ज्ञ |
| ग | ग्क | ग्ख | ग्ग | ग्घ | ग्ङ | ग्च | ग्छ | ग्ज | ग्झ | ग्ञ | ग्ट | ग्ठ | ग्ड | ग्ढ | ग्ण | ग्त | ग्थ | ग्द | ग्ध | ग्न | ग्प | ग्फ | ग्ब | ग्भ | ग्म | ग्य | ग्र | ग्ल | ग्व | ग्श | ग्ष | ग्स | ग्ह | ग्ळ | ग्क्ष | ग्ज्ञ |
| घ | घ्क | घ्ख | घ्ग | घ्घ | घ्ङ | घ्च | घ्छ | घ्ज | घ्झ | घ्ञ | घ्ट | घ्ठ | घ्ड | घ्ढ | घ्ण | घ्त | घ्थ | घ्द | घ्ध | घ्न | घ्प | घ्फ | घ्ब | घ्भ | घ्म | घ्य | घ्र | घ्ल | घ्व | घ्श | घ्ष | घ्स | घ्ह | घ्ळ | घ्क्ष | घ्ज्ञ |
| ङ | ङ्क | ङ्ख | ङ्ग | ङ्घ | ङ्ङ | ङ्च | ङ्छ | ङ्ज | ङ्झ | ङ्ञ | ङ्ट | ङ्ठ | ङ्ड | ङ्ढ | ङ्ण | ङ्त | ङ्थ | ङ्द | ङ्ध | ङ्न | ङ्प | ङ्फ | ङ्ब | ङ्भ | ङ्म | ङ्य | ङ्र | ङ्ल | ङ्व | ङ्श | ङ्ष | ङ्स | ङ्ह | ङ्ळ | ङ्क्ष | ङ्ज्ञ |
| च | च्क | च्ख | च्ग | च्घ | च्ङ | च्च | च्छ | च्ज | च्झ | च्ञ | च्ट | च्ठ | च्ड | च्ढ | च्ण | च्त | च्थ | च्द | च्ध | च्न | च्प | च्फ | च्ब | च्भ | च्म | च्य | च्र | च्ल | च्व | च्श | च्ष | च्स | च्ह | च्ळ | च्क्ष | च्ज्ञ |
| छ | छ्क | छ्ख | छ्ग | छ्घ | छ्ङ | छ्च | छ्छ | छ्ज | छ्झ | छ्ञ | छ्ट | छ्ठ | छ्ड | छ्ढ | छ्ण | छ्त | छ्थ | छ्द | छ्ध | छ्न | छ्प | छ्फ | छ्ब | छ्भ | छ्म | छ्य | छ्र | छ्ल | छ्व | छ्श | छ्ष | छ्स | छ्ह | छ्ळ | छ्क्ष | छ्ज्ञ |
| ज | ज्क | ज्ख | ज्ग | ज्घ | ज्ङ | ज्च | ज्छ | ज्ज | ज्झ | ज्ञ | ज्ट | ज्ठ | ज्ड | ज्ढ | ज्ण | ज्त | ज्थ | ज्द | ज्ध | ज्न | ज्प | ज्फ | ज्ब | ज्भ | ज्म | ज्य | ज्र | ज्ल | ज्व | ज्श | ज्ष | ज्स | ज्ह | ज्ळ | ज्क्ष | ज्ज्ञ |
| झ | झ्क | झ्ख | झ्ग | झ्घ | झ्ङ | झ्च | झ्छ | झ्ज | झ्झ | झ्ञ | झ्ट | झ्ठ | झ्ड | झ्ढ | झ्ण | झ्त | झ्थ | झ्द | झ्ध | झ्न | झ्प | झ्फ | झ्ब | झ्भ | झ्म | झ्य | झ्र | झ्ल | झ्व | झ्श | झ्ष | झ्स | झ्ह | झ्ळ | झ्क्ष | झ्ज्ञ |
| ञ | ञ्क | ञ्ख | ञ्ग | ञ्घ | ञ्ङ | ञ्च | ञ्छ | ञ्ज | ञ्झ | ञ्ञ | ञ्ट | ञ्ठ | ञ्ड | ञ्ढ | ञ्ण | ञ्त | ञ्थ | ञ्द | ञ्ध | ञ्न | ञ्प | ञ्फ | ञ्ब | ञ्भ | ञ्म | ञ्य | ञ्र | ञ्ल | ञ्व | ञ्श | ञ्ष | ञ्स | ञ्ह | ञ्ळ | ञ्क्ष | ञ्ज्ञ |
| ट | ट्क | ट्ख | ट्ग | ट्घ | ट्ङ | ट्च | ट्छ | ट्ज | ट्झ | ट्ञ | ट्ट | ट्ठ | ट्ड | ट्ढ | ट्ण | ट्त | ट्थ | ट्द | ट्ध | ट्न | ट्प | ट्फ | ट्ब | ट्भ | ट्म | ट्य | ट्र | ट्ल | ट्व | ट्श | ट्ष | ट्स | ट्ह | ट्ळ | ट्क्ष | ट्ज्ञ |
| ठ | ठ्क | ठ्ख | ठ्ग | ठ्घ | ठ्ङ | ठ्च | ठ्छ | ठ्ज | ठ्झ | ठ्ञ | ठ्ट | ठ्ठ | ठ्ड | ठ्ढ | ठ्ण | ठ्त | ठ्थ | ठ्द | ठ्ध | ठ्न | ठ्प | ठ्फ | ठ्ब | ठ्भ | ठ्म | ठ्य | ठ्र | ठ्ल | ठ्व | ठ्श | ठ्ष | ठ्स | ठ्ह | ठ्ळ | ठ्क्ष | ठ्ज्ञ |
| ड | ड्क | ड्ख | ड्ग | ड्घ | ड्ङ | ड्च | ड्छ | ड्ज | ड्झ | ड्ञ | ड्ट | ड्ठ | ड्ड | ड्ढ | ड्ण | ड्त | ड्थ | ड्द | ड्ध | ड्न | ड्प | ड्फ | ड्ब | ड्भ | ड्म | ड्य | ड्र | ड्ल | ड्व | ड्श | ड्ष | ड्स | ड्ह | ड्ळ | ड्क्ष | ड्ज्ञ |
| ढ | ढ्क | ढ्ख | ढ्ग | ढ्घ | ढ्ङ | ढ्च | ढ्छ | ढ्ज | ढ्झ | ढ्ञ | ढ्ट | ढ्ठ | ढ्ड | ढ्ढ | ढ्ण | ढ्त | ढ्थ | ढ्द | ढ्ध | ढ्न | ढ्प | ढ्फ | ढ्ब | ढ्भ | ढ्म | ढ्य | ढ्र | ढ्ल | ढ्व | ढ्श | ढ्ष | ढ्स | ढ्ह | ढ्ळ | ढ्क्ष | ढ्ज्ञ |
| ण | ण्क | ण्ख | ण्ग | ण्घ | ण्ङ | ण्च | ण्छ | ण्ज | ण्झ | ण्ञ | ण्ट | ण्ठ | ण्ड | ण्ढ | ण्ण | ण्त | ण्थ | ण्द | ण्ध | ण्न | ण्प | ण्फ | ण्ब | ण्भ | ण्म | ण्य | ण्र | ण्ल | ण्व | ण्श | ण्ष | ण्स | ण्ह | ण्ळ | ण्क्ष | ण्ज्ञ |
| त | त्क | त्ख | त्ग | त्घ | त्ङ | त्च | त्छ | त्ज | त्झ | त्ञ | त्ट | त्ठ | त्ड | त्ढ | त्ण | त्त | त्थ | त्द | त्ध | त्न | त्प | त्फ | त्ब | त्भ | त्म | त्य | त्र | त्ल | त्व | त्श | त्ष | त्स | त्ह | त्ळ | त्क्ष | त्ज्ञ |
| थ | थ्क | थ्ख | थ्ग | थ्घ | थ्ङ | थ्च | थ्छ | थ्ज | थ्झ | थ्ञ | थ्ट | थ्ठ | थ्ड | थ्ढ | थ्ण | थ्त | थ्थ | थ्द | थ्ध | थ्न | थ्प | थ्फ | थ्ब | थ्भ | थ्म | थ्य | थ्र | थ्ल | थ्व | थ्श | थ्ष | थ्स | थ्ह | थ्ळ | थ्क्ष | थ्ज्ञ |
| द | द्क | द्ख | द्ग | द्घ | द्ङ | द्च | द्छ | द्ज | द्झ | द्ञ | द्ट | द्ठ | द्ड | द्ढ | द्ण | द्त | द्थ | द्द | द्ध | द्न | द्प | द्फ | द्ब | द्भ | द्म | द्य | द्र | द्ल | द्व | द्श | द्ष | द्स | द्ह | द्ळ | द्क्ष | द्ज्ञ |
| ध | ध्क | ध्ख | ध्ग | ध्घ | ध्ङ | ध्च | ध्छ | ध्ज | ध्झ | ध्ञ | ध्ट | ध्ठ | ध्ड | ध्ढ | ध्ण | ध्त | ध्थ | ध्द | ध्ध | ध्न | ध्प | ध्फ | ध्ब | ध्भ | ध्म | ध्य | ध्र | ध्ल | ध्व | ध्श | ध्ष | ध्स | ध्ह | ध्ळ | ध्क्ष | ध्ज्ञ |
| न | न्क | न्ख | न्ग | न्घ | न्ङ | न्च | न्छ | न्ज | न्झ | न्ञ | न्ट | न्ठ | न्ड | न्ढ | न्ण | न्त | न्थ | न्द | न्ध | न्न | न्प | न्फ | न्ब | न्भ | न्म | न्य | न्र | न्ल | न्व | न्श | न्ष | न्स | न्ह | न्ळ | न्क्ष | न्ज्ञ |
| प | प्क | प्ख | प्ग | प्घ | प्ङ | प्च | प्छ | प्ज | प्झ | प्ञ | प्ट | प्ठ | प्ड | प्ढ | प्ण | प्त | प्थ | प्द | प्ध | प्न | प्प | प्फ | प्ब | प्भ | प्म | प्य | प्र | प्ल | प्व | प्श | प्ष | प्स | प्ह | प्ळ | प्क्ष | प्ज्ञ |
| फ | फ्क | फ्ख | फ्ग | फ्घ | फ्ङ | फ्च | फ्छ | फ्ज | फ्झ | फ्ञ | फ्ट | फ्ठ | फ्ड | फ्ढ | फ्ण | फ्त | फ्थ | फ्द | फ्ध | फ्न | फ्प | फ्फ | फ्ब | फ्भ | फ्म | फ्य | फ्र | फ्ल | फ्व | फ्श | फ्ष | फ्स | फ्ह | फ्ळ | फ्क्ष | फ्ज्ञ |
| ब | ब्क | ब्ख | ब्ग | ब्घ | ब्ङ | ब्च | ब्छ | ब्ज | ब्झ | ब्ञ | ब्ट | ब्ठ | ब्ड | ब्ढ | ब्ण | ब्त | ब्थ | ब्द | ब्ध | ब्न | ब्प | ब्फ | ब्ब | ब्भ | ब्म | ब्य | ब्र | ब्ल | ब्व | ब्श | ब्ष | ब्स | ब्ह | ब्ळ | ब्क्ष | ब्ज्ञ |
| भ | भ्क | भ्ख | भ्ग | भ्घ | भ्ङ | भ्च | भ्छ | भ्ज | भ्झ | भ्ञ | भ्ट | भ्ठ | भ्ड | भ्ढ | भ्ण | भ्त | भ्थ | भ्द | भ्ध | भ्न | भ्प | भ्फ | भ्ब | भ्भ | भ्म | भ्य | भ्र | भ्ल | भ्व | भ्श | भ्ष | भ्स | भ्ह | भ्ळ | भ्क्ष | भ्ज्ञ |
| म | म्क | म्ख | म्ग | म्घ | म्ङ | म्च | म्छ | म्ज | म्झ | म्ञ | म्ट | म्ठ | म्ड | म्ढ | म्ण | म्त | म्थ | म्द | म्ध | म्न | म्प | म्फ | म्ब | म्भ | म्म | म्य | म्र | म्ल | म्व | म्श | म्ष | म्स | म्ह | म्ळ | म्क्ष | म्ज्ञ |
| य | य्क | य्ख | य्ग | य्घ | य्ङ | य्च | य्छ | य्ज | य्झ | य्ञ | य्ट | य्ठ | य्ड | य्ढ | य्ण | य्त | य्थ | य्द | य्ध | य्न | य्प | य्फ | य्ब | य्भ | य्म | य्य | य्र | य्ल | य्व | य्श | य्ष | य्स | य्ह | य्ळ | य्क्ष | य्ज्ञ |
| र | र्क | र्ख | र्ग | र्घ | र्ङ | र्च | र्छ | र्ज | र्झ | र्ञ | र्ट | र्ठ | र्ड | र्ढ | र्ण | र्त | र्थ | र्द | र्ध | र्न | र्प | र्फ | र्ब | र्भ | र्म | र्य | र्र | र्ल | र्व | र्श | र्ष | र्स | र्ह | र्ळ | र्क्ष | र्ज्ञ |
| ल | ल्क | ल्ख | ल्ग | ल्घ | ल्ङ | ल्च | ल्छ | ल्ज | ल्झ | ल्ञ | ल्ट | ल्ठ | ल्ड | ल्ढ | ल्ण | ल्त | ल्थ | ल्द | ल्ध | ल्न | ल्प | ल्फ | ल्ब | ल्भ | ल्म | ल्य | ल्र | ल्ल | ल्व | ल्श | ल्ष | ल्स | ल्ह | ल्ळ | ल्क्ष | ल्ज्ञ |
| व | व्क | व्ख | व्ग | व्घ | व्ङ | व्च | व्छ | व्ज | व्झ | व्ञ | व्ट | व्ठ | व्ड | व्ढ | व्ण | व्त | व्थ | व्द | व्ध | व्न | व्प | व्फ | व्ब | व्भ | व्म | व्य | व्र | व्ल | व्व | व्श | व्ष | व्स | व्ह | व्ळ | व्क्ष | व्ज्ञ |
| श | श्क | श्ख | श्ग | श्घ | श्ङ | श्च | श्छ | श्ज | श्झ | श्ञ | श्ट | श्ठ | श्ड | श्ढ | श्ण | श्त | श्थ | श्द | श्ध | श्न | श्प | श्फ | श्ब | श्भ | श्म | श्य | श्र | श्ल | श्व | श्श | श्ष | श्स | श्ह | श्ळ | श्क्ष | श्ज्ञ |
| ष | ष्क | ष्ख | ष्ग | ष्घ | ष्ङ | ष्च | ष्छ | ष्ज | ष्झ | ष्ञ | ष्ट | ष्ठ | ष्ड | ष्ढ | ष्ण | ष्त | ष्थ | ष्द | ष्ध | ष्न | ष्प | ष्फ | ष्ब | ष्भ | ष्म | ष्य | ष्र | ष्ल | ष्व | ष्श | ष्ष | ष्स | ष्ह | ष्ळ | ष्क्ष | ष्ज्ञ |
| स | स्क | स्ख | स्ग | स्घ | स्ङ | स्च | स्छ | स्ज | स्झ | स्ञ | स्ट | स्ठ | स्ड | स्ढ | स्ण | स्त | स्थ | स्द | स्ध | स्न | स्प | स्फ | स्ब | स्भ | स्म | स्य | स्र | स्ल | स्व | स्श | स्ष | स्स | स्ह | स्ळ | स्क्ष | स्ज्ञ |
| ह | ह्क | ह्ख | ह्ग | ह्घ | ह्ङ | ह्च | ह्छ | ह्ज | ह्झ | ह्ञ | ह्ट | ह्ठ | ह्ड | ह्ढ | ह्ण | ह्त | ह्थ | ह्द | ह्ध | ह्न | ह्प | ह्फ | ह्ब | ह्भ | ह्म | ह्य | ह्र | ह्ल | ह्व | ह्श | ह्ष | ह्स | ह्ह | ह्ळ | ह्क्ष | ह्ज्ञ |
| ळ | ळ्क | ळ्ख | ळ्ग | ळ्घ | ळ्ङ | ळ्च | ळ्छ | ळ्ज | ळ्झ | ळ्ञ | ळ्ट | ळ्ठ | ळ्ड | ळ्ढ | ळ्ण | ळ्त | ळ्थ | ळ्द | ळ्ध | ळ्न | ळ्प | ळ्फ | ळ्ब | ळ्भ | ळ्म | ळ्य | ळ्र | ळ्ल | ळ्व | ळ्श | ळ्ष | ळ्स | ळ्ह | ळ्ळ | ळ्क्ष | ळ्ज्ञ |
Accent marks
The pitch accent of Vedic Sanskrit is written with various symbols depending on shakha. In the Rigveda, anudātta is written with a bar below the line (◌॒), svarita with a stroke above the line (◌॑) while udātta is unmarked.
Punctuation
The end of a sentence or half-verse may be marked with a dot known as a pūrṇa virām or a vertical line danda: ।. The end of a full verse may be marked with two vertical lines: ॥. A comma, or alpa virām, is used to denote a natural pause in speech.[51][52] Other punctuation marks such as colon, semi-colon, exclamation mark, dash and question mark currently in use in Devanagari script match those in European languages.[53]
Old forms
The following letter variants are also in use, particularly in older texts.[54]
| Standard form | Variant form |
|---|---|
| | |
| | |
| | |
| | |
Numerals
| ० | १ | २ | ३ | ४ | ५ | ६ | ७ | ८ | ९ |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Fonts
A variety of fonts are in use for Devanagari. These include, but are not limited to, Akshar,[55] Annapurna,[56] Arial,[57] CDAC-Gist Surekh,[58] CDAC-Gist Yogesh,[59] Chanda,[60] Gargi,[61] Gurumaa,[62] Jaipur,[63] Jana,[64] Kalimati,[65] Kanjirowa,[66] Mangal,[67] Raghu,[68] Sanskrit Ashram,[69] Santipur OT,[60] Thyaka,[70] and Uttara.[60]
The form of Devanagari fonts vary with function. According to Harvard College for Sanskrit studies, "Uttara [companion to Chanda] is the best in terms of ligatures but, because it is designed for Vedic as well, requires so much vertical space that it is not well suited for the "user interface font" (though an excellent choice for the "original field" font). Santipur OT is a beautiful font reflecting a very early [medieval era] typesetting style for Devanagari. Sanskrit 2003[71] is a good all-around font and has more ligatures than most fonts, though students will probably find the spacing of the CDAC-Gist Surekh[58] font makes for quicker comprehension and reading."[60]
Transliteration
There are several methods of Romanisation or transliteration from Devanagari to the Roman script.[72]
Hunterian system
The Hunterian system is the "national system of romanisation in India" and the one officially adopted by the Government of India.[73][74][75]
ISO 15919
A standard transliteration convention was codified in the ISO 15919 standard of 2001. It uses diacritics to map the much larger set of Brahmic graphemes to the Latin script. The Devanagari-specific portion is nearly identical to the academic standard for Sanskrit, IAST.[76]
IAST
The International Alphabet of Sanskrit Transliteration (IAST) is the academic standard for the romanisation of Sanskrit. IAST is the de facto standard used in printed publications, like books, magazines, and electronic texts with Unicode fonts. It is based on a standard established by the Congress of Orientalists at Athens in 1912. The ISO 15919 standard of 2001 codified the transliteration convention to include an expanded standard for sister scripts of Devanagari.[76]
The National Library at Kolkata romanisation, intended for the romanisation of all Indic scripts, is an extension of IAST.
Harvard-Kyoto
Compared to IAST, Harvard-Kyoto looks much simpler. It does not contain all the diacritic marks that IAST contains. It was designed to simplify the task of putting large amount of Sanskrit textual material into machine readable form, and the inventors stated that it reduces the effort needed in transliteration of Sanskrit texts on the keyboard.[77] This makes typing in Harvard-Kyoto much easier than IAST. Harvard-Kyoto uses capital letters that can be difficult to read in the middle of words.
ITRANS
ITRANS is a lossless transliteration scheme of Devanagari into ASCII that is widely used on Usenet. It is an extension of the Harvard-Kyoto scheme. In ITRANS, the word devanāgarī is written "devanaagarii" or "devanAgarI". ITRANS is associated with an application of the same name that enables typesetting in Indic scripts. The user inputs in Roman letters and the ITRANS pre-processor translates the Roman letters into Devanagari (or other Indic languages). The latest version of ITRANS is version 5.30 released in July, 2001. It is similar to Velthius system and was created by Avinash Chopde to help print various Indic scripts with personal computers.[77]
Velthuis
Main article: Velthuis
The disadvantage of the above ASCII schemes is case-sensitivity, implying that transliterated names may not be capitalized. This difficulty is avoided with the system developed in 1996 by Frans Velthuis for TeX, loosely based on IAST, in which case is irrelevant.
ALA-LC Romanisation
ALA-LC[78] romanisation is a transliteration scheme approved by the Library of Congress and the American Library Association, and widely used in North American libraries. Transliteration tables are based on languages, so there is a table for Hindi,[79] one for Sanskrit and Prakrit,[80] etc.
WX
WX is a Roman transliteration scheme for Indian languages, widely used among the natural language processing community in India. It originated at IIT Kanpur for computational processing of Indian languages. The salient features of this transliteration scheme are as follows.
- Every consonant and every vowel has a single mapping into Roman. Hence it is a prefix code, advantageous from computation point of view.
- Lower-case letters are used for unaspirated consonants and short vowels, while capital letters are used for aspirated consonants and long vowels. While the retroflex stops are mapped to 't, T, d, D, N', the dentals are mapped to 'w, W, x, X, n'. Hence the name 'WX', a reminder of this idiosyncratic mapping.
Encodings
ISCII
ISCII is an 8-bit encoding. The lower 128 codepoints are plain ASCII, the upper 128 codepoints are ISCII-specific.
It has been designed for representing not only Devanagari but also various other Indic scripts as well as a Latin-based script with diacritic marks used for transliteration of the Indic scripts.
ISCII has largely been superseded by Unicode, which has, however, attempted to preserve the ISCII layout for its Indic language blocks.
Unicode
The Unicode Standard defines three blocks for Devanagari: Devanagari (U+0900–U+097F), Devanagari Extended (U+A8E0–U+A8FF), and Vedic Extensions (U+1CD0–U+1CFF).
| Devanagari[1] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+090x | ऀ | ँ | ं | ः | ऄ | अ | आ | इ | ई | उ | ऊ | ऋ | ऌ | ऍ | ऎ | ए |
| U+091x | ऐ | ऑ | ऒ | ओ | औ | क | ख | ग | घ | ङ | च | छ | ज | झ | ञ | ट |
| U+092x | ठ | ड | ढ | ण | त | थ | द | ध | न | ऩ | प | फ | ब | भ | म | य |
| U+093x | र | ऱ | ल | ळ | ऴ | व | श | ष | स | ह | ऺ | ऻ | ़ | ऽ | ा | ि |
| U+094x | ी | ु | ू | ृ | ॄ | ॅ | ॆ | े | ै | ॉ | ॊ | ो | ौ | ् | ॎ | ॏ |
| U+095x | ॐ | ॑ | ॒ | ॓ | ॔ | ॕ | ॖ | ॗ | क़ | ख़ | ग़ | ज़ | ड़ | ढ़ | फ़ | य़ |
| U+096x | ॠ | ॡ | ॢ | ॣ | । | ॥ | ० | १ | २ | ३ | ४ | ५ | ६ | ७ | ८ | ९ |
| U+097x | ॰ | ॱ | ॲ | ॳ | ॴ | ॵ | ॶ | ॷ | ॸ | ॹ | ॺ | ॻ | ॼ | ॽ | ॾ | ॿ |
Notes
| ||||||||||||||||
| Devanagari Extended[1][2] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+A8Ex | ꣠ | ꣡ | ꣢ | ꣣ | ꣤ | ꣥ | ꣦ | ꣧ | ꣨ | ꣩ | ꣪ | ꣫ | ꣬ | ꣭ | ꣮ | ꣯ |
| U+A8Fx | ꣰ | ꣱ | ꣲ | ꣳ | ꣴ | ꣵ | ꣶ | ꣷ | ꣸ | ꣹ | ꣺ | ꣻ | ꣼ | ꣽ | ||
| Notes | ||||||||||||||||
| Vedic Extensions[1][2] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+1CDx | ᳐ | ᳑ | ᳒ | ᳓ | ᳔ | ᳕ | ᳖ | ᳗ | ᳘ | ᳙ | ᳚ | ᳛ | ᳜ | ᳝ | ᳞ | ᳟ |
| U+1CEx | ᳠ | ᳡ | ᳢ | ᳣ | ᳤ | ᳥ | ᳦ | ᳧ | ᳨ | ᳩ | ᳪ | ᳫ | ᳬ | ᳭ | ᳮ | ᳯ |
| U+1CFx | ᳰ | ᳱ | ᳲ | ᳳ | ᳴ | ᳵ | ᳶ | ᳸ | ᳹ | |||||||
| Notes | ||||||||||||||||
Devanagari keyboard layouts
- For a list of Devanagari input tools and fonts, please see Help:Multilingual support (Indic).
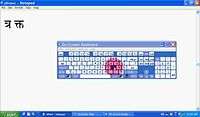
InScript is the standard keyboard layout for Devanagari. It is inbuilt in all modern major operating systems. Microsoft Windows supports the InScript layout (using the Mangal font), which can be used to input unicode Devanagari characters. InScript is also available in some touchscreen mobile phones.
InScript layout

A Devanagari INSCRIPT bilingual keyboard.
Typewriter
This layout was used on manual typewriters when computers were not available or were uncommon. For backward compatibility some typing tools like Indic IME still provide this layout.

Phonetic
Such tools work on phonetic transliteration. The user writes in Roman and the IME automatically converts it into Devanagari. Some popular phonetic typing tools are BarahaIME and Google IME.
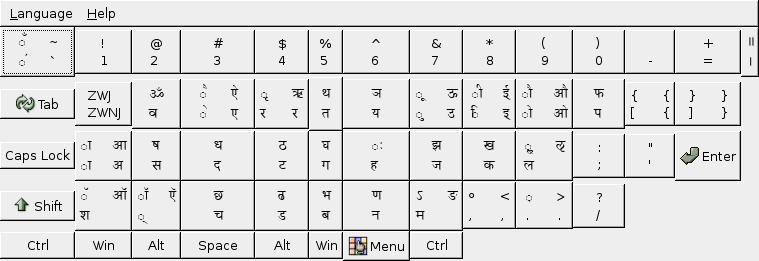
The Mac OS X operating system includes two different keyboard layouts for Devanagari: one is much like INSCRIPT/KDE Linux, the other is a phonetic layout called "Devanagari QWERTY".
Any one of Unicode fonts input system is fine for Indic language Wikipedia and other wikiprojects, including Hindi, Bhojpuri, Marathi, Nepali Wikipedia. Some people use inscript. Majority uses either Google phonetic transliteration or input facility Universal Language Selector provided on Wikipedia.On Indic language wikiprojects Phonetic facility provided initially was java-based later supported by Narayam extension for phonetic input facility. Currently Indic language Wiki projects are supported by Universal Language Selector (ULS), that offers both phonetic keyboard (Aksharantaran,Marathi:अक्षरांतरण, Hindi:लिप्यंतरण, बोलनागरी ) and InScript keyboard (Marathi:मराठी लिपी).
The Ubuntu Linux operating system supports several keyboard layouts for Devanagari, including Harvard-Kyoto, WX notation, Bolanagari and phonetic.
See also
- Clip font
- Devanagari transliteration
- Devanagari Braille
- ISCII
- Nagari Pracharini Sabha
- Nepali
- Schwa deletion in Indo-Aryan languages
References
- Footnotes
- 1 2 Isaac Taylor (1883), History of the Alphabet: Aryan Alphabets, Part 2, Kegan Paul, Trench & Co, p. 333, ISBN 978-0-7661-5847-4,
... In the Kutila this develops into a short horizontal bar, which, in the Devanagari, becomes a continuous horizontal line ... three cardinal inscriptions of this epoch, namely, the Kutila or Bareli inscription of 992, the Chalukya or Kistna inscription of 945, and a Kawi inscription of 919 ... the Kutila inscription is of great importance in Indian epigraphy, not only from its precise date, but from its offering a definite early form of the standard Indian alphabet, the Devanagari ...
- 1 2 Gazetteer of the Bombay Presidency, p. 30, at Google Books, Rudradaman’s inscription from 1st through 4th century CE found in Gujarat, India, Stanford University Archives, pages 30-45
- ↑ Richard Salomon (2014), Indian Epigraphy, Oxford University Press, ISBN 978-0195356663, pages 33-47
- 1 2 Kathleen Kuiper (2010), The Culture of India, New York: The Rosen Publishing Group, ISBN 978-1615301492, page 83
- 1 2 George Cardona and Danesh Jain (2003), The Indo-Aryan Languages, Routledge, ISBN 978-0415772945, pages 72-74
- ↑ George Cardona and Danesh Jain (2003), The Indo-Aryan Languages, Routledge, ISBN 978-0415772945, pages 68-69
- 1 2 Richard Salomon (2014), Indian Epigraphy, Oxford University Press, ISBN 978-0195356663, pages 40-42
- ↑ Michael Willis (2001), Inscriptions from Udayagiri: locating domains of devotion, patronage and power in the eleventh century, South Asian Studies, 17(1), pages 41-53
- ↑ Brick with Sanskrit inscription in Nagari script, 1217 CE, found in Uttar Pradesh, India (British Museum)
- 1 2 3 4 George Cardona and Danesh Jain (2003), The Indo-Aryan Languages, Routledge, ISBN 978-0415772945, pages 75-77
- ↑ Wayan Ardika (2009), Form, Macht, Differenz: Motive und Felder ethnologischen Forschens (Editors: Elfriede Hermann et al.), Universitätsverlag Göttingen, ISBN 978-3940344809, pages 251-252; Quote: "Nagari script and Sanskrit language in the inscription at Blangjong suggests that Indian culture was already influencing Bali (Indonesia) by the 10th century AD."
- 1 2 3 4 Devanagari (Nagari), Script Features and Description, SIL International (2013), United States
- ↑ Hindi, Omniglot Encyclopedia of Writing Systems and Languages
- ↑ David Templin. "Devanagari script". omniglot.com. Retrieved 5 April 2015.
- ↑ George Cardona and Danesh Jain (2003), The Indo-Aryan Languages, Routledge, ISBN 978-0415772945, page 75
- ↑ Reinhold Grünendahl (2001), South Indian Scripts in Sanskrit Manuscripts and Prints, Otto Harrassowitz Verlag, ISBN 978-3447045049, pages xxii, 201-210
- ↑ Akira Nakanishi, Writing systems of the World, ISBN 978-0804816540, page 48
- 1 2 3 4 Steven Roger Fischer (2004), A history of writing, Reaktion Books, ISBN 978-1-86189-167-9,
... an early branch of this, as of the fourth century CE, was the Gupta script, Brahmi's first main daughter ... the Gupta alphabet became the ancestor of most Indic scripts (usually through later Devanagari) ... Nagari, of India's north-west, first appeared around 633 CE ... in the eleventh century, Nagari had become Devanagari, or 'heavenly Nagari', since it was now the main vehicle, out of several, for Sanskrit literature ...
- ↑ Krishna Chandra Sagar (1993), Foreign Influence on Ancient India, South Asia Books, ISBN 978-8172110284, page 137
- ↑ Richard Salomon (2014), Indian Epigraphy, Oxford University Press, ISBN 978-0195356663, page 71
- ↑ William Woodville Rockhill, Annual Report of the Board of Regents of the Smithsonian Institution, p. 671, at Google Books, United States National Museum, page 671
- ↑ David Quinter (2015), From Outcasts to Emperors: Shingon Ritsu and the Mañjuśrī Cult in Medieval Japan, Brill, ISBN 978-9004293397, pages 63-65 with discussion on Uṣṇīṣa Vijaya Dhāraṇī Sūtra
- ↑ Richard Salomon (2014), Indian Epigraphy, Oxford University Press, ISBN 978-0195356663, pages 157-160
- ↑ Michael Witzel (2006), in Between the Empires : Society in India 300 BCE to 400 CE (Editor: Patrick Olivelle), Oxford University Press, ISBN 978-0195305326, pages 477-480 with footnote 60;
Original manuscript, dates in Saka Samvat, and uncertainties associated with it: Mahabhasya of Patanjali, F Kielhorn - ↑ Monier Williams Online Dictionary, nagara, Cologne Sanskrit Digital Lexicon, Germany
- ↑ Salomon (2003:70)
- ↑ "Archives.conlang.info". Archives.conlang.info. 2004-12-07. Retrieved 2011-06-13.
- ↑ Salomon (2003:71)
- 1 2 Salomon (2003:75)
- ↑ Wikner (1996:13, 14)
- ↑ Wikner (1996:6)
- ↑ Snell (2000:44–45)
- ↑ Snell (2000:64)
- ↑ Snell (2000:45)
- ↑ Snell (2000:46)
- ↑ Salomon (2003:77)
- ↑ Verma (2003:501)
- ↑ Wikner (1996:73)
- ↑ Masica (1991:97)
- 1 2 Larry M. Hyman, Victoria Fromkin, Charles N. Li (1988), Language, speech, and mind, Part 2, Taylor & Francis, ISBN 0-415-00311-3,
... The implicit /a/ is not read when the symbol appears in word-final position or in certain other contexts where it is obligatorily deleted via the so-called schwa-deletion rule which plays a crucial role in Hindi word phonology ...
- 1 2 Tej K. Bhatia (1987), A history of the Hindi grammatical tradition: Hindi-Hindustani grammar, grammarians, history and problems, BRILL, ISBN 90-04-07924-6,
... Hindi literature fails as a reliable indicator of the actual pronunciation because it is written in the Devanagari script ... the schwa syncope rule which operates in Hindi ...
- 1 2 3 Monojit Choudhury, Anupam Basu and Sudeshna Sarkar (July 2004), "A Diachronic Approach for Schwa Deletion in Indo Aryan Languages" (PDF), Proceedings of the Workshop of the ACL Special Interest Group on Computational Phonology (SIGPHON) (Association for Computations Linguistics),
... schwa deletion is an important issue for grapheme-to-phoneme conversion of IAL, which in turn is required for a good Text-to-Speech synthesiser ...
- 1 2 Naim R. Tyson, Ila Nagar (2009), "Prosodic rules for schwa-deletion in Hindi text-to-speech synthesis" (PDF), International Journal of Speech Technology,
... Without the appropriate deletion of schwas, any speech output would sound unnatural. Since the orthographical representation of Devanagari gives little indication of deletion sites, modern TTS systems for Hindi implemented schwa deletion rules based on the segmental context where schwa appears ...
- ↑ Nazir Ali Jairazbhoy, The rāgs of North Indian music: their structure and evolution, Popular Prakashan, 1995, ISBN 978-81-7154-395-3,
... The Devnagri (Devanagari) script is syllabic and all consonants carry the inherent vowel a unless otherwise indicated. The principal difference between modern Hindi and the classical Sanskrit forms is the omission in Hindi ...
- 1 2 3 Monojit Choudhury and Anupam Basu (July 2004), "A Rule Based Schwa Deletion Algorithm for Hindi" (PDF), Proceedings of the International Conference On Knowledge-Based Computer Systems,
... Without any schwa deletion, not only the two words will sound very unnatural, but it will also be extremely difficult for the listener to distinguish between the two, the only difference being nasalisation of the e at the end of the former. However, a native speaker would pronounce the former as dha.D-kan-eM and the later as dha.Dak-ne, which are clearly distinguishable ...
- 1 2 Janet Pierrehumbert, Rami Nair, Volume Editor: Bernard Laks, Implications of Hindi Prosodic Structure (Current Trends in Phonology: Models and Methods), European Studies Research Institute, University of Salford Press, 1996, ISBN 978-1-901471-02-1,
... showed extremely regular patterns. As is not uncommon in a study of subphonemic detail, the objective data patterned much more cleanly than intuitive judgments ... [w] occurs when /व/ is in onglide position ... [v] occurs otherwise ...
- ↑ "TDIL (Technology Development for Indian Languages) Font Download". TDIL. Retrieved 2014-01-03.
- ↑ Saloman, Richard (2007) “Typological Observations on the Indic Scripts” in The Indic Scripts: Paleographic and Linguistic Perspecticves D.K. Printworld Ltd., New Delhi. ISBN 812460406-1. p. 33.
- ↑ "The Unicode Standard, chapter 9, South Asian Scripts I" (PDF). The Unicode Standard, v. 6.0. Unicode, Inc. Retrieved Feb 12, 2012.
- ↑ The romanization shown is identical to IAST, except that ळ (which is not used in Sanskrit) has the ISO romanization ḷ, which in IAST is the dental vowel l.
- ↑ Unicode Consortium, The Unicode Standard, Version 3.0, Volume 1, ISBN 978-0201616330, Addison-Wesley, pages 221-223
- ↑ Transliteration from Hindi Script to Meetei Mayek Watham and Vimal (2013), IJETR, page 550
- ↑ Michael Shapiro (2014), The Devanagari Writing System in A Primer of Modern Standard Hindi, Motilal Banarsidass, ISBN 978-8120805088, page 26
- ↑ (Bahri 2004, p. (xiii))
- ↑ Akshar Unicode South Asia Language Resource, University of Chicago (2009)
- ↑ Annapurna SIL Unicode, SIL International (2013)
- ↑ Arial Unicode South Asia Language Resource, University of Chicago (2009)
- 1 2 CDAC-GIST Surekh Unicode South Asia Language Resource, University of Chicago (2009)
- ↑ CDAC-GIST Yogesh South Asia Language Resource, University of Chicago (2009)
- 1 2 3 4 Sanskrit Devanagari Fonts Harvard University (2010); see Chanda and Uttara ttf 2010 archive (Accessed: July 8, 2015)
- ↑ Gargi South Asia Language Resource, University of Chicago (2009)
- ↑ Gurumaa Unicode - a sans font KDE (2012)
- ↑ Jaipur South Asia Language Resource, University of Chicago (2009)
- ↑ Jana South Asia Language Resource, University of Chicago (2009)
- ↑ Kalimati South Asia Language Resource, University of Chicago (2009)
- ↑ Kanjirowa South Asia Language Resource, University of Chicago (2009)
- ↑ Mangal South Asia Language Resource, University of Chicago (2009)
- ↑ Raghu South Asia Language Resource, University of Chicago (2009)
- ↑ Sanskrit Ashram South Asia Language Resource, University of Chicago (2009)
- ↑ Thyaka South Asia Language Resource, University of Chicago (2009)
- ↑ Devanagari font Unicode Standard 8.0 (2015)
- ↑ Daya Nand Sharma, Transliteration into Roman and Devanagari of the languages of the Indian group, Survey of India, 1972,
... With the passage of time there has emerged a practically uniform system of transliteration of Devanagari and allied alphabets. Nevertheless, no single system of Romanisation has yet developed ...
- ↑ United Nations Group of Experts on Geographical Names, United Nations Department of Economic and Social Affairs, Technical reference manual for the standardisation of geographical names, United Nations Publications, 2007, ISBN 978-92-1-161500-5,
... ISO 15919 ... There is no evidence of the use of the system either in India or in international cartographic products ... The Hunterian system is the actually used national system of romanisation in India ...
- ↑ United Nations Department of Economic and Social Affairs, United Nations Regional Cartographic Conference for Asia and the Far East, Volume 2, United Nations, 1955,
... In India the Hunterian system is used, whereby every sound in the local language is uniformly represented by a certain letter in the Roman alphabet ...
- ↑ National Library (India), Indian scientific & technical publications, exhibition 1960: a bibliography, Council of Scientific & Industrial Research, Government of India, 1960,
... The Hunterian system of transliteration, which has international acceptance, has been used ...
- 1 2 Devanagari IAST conventions Script Source (2009), SIL International, United States
- 1 2 Transliteration of Devanāgarī D. Wujastyk (1996)
- ↑ "LOC.gov". LOC.gov. Retrieved 2011-06-13.
- ↑ "0001.eps" (PDF). Retrieved 2011-06-13.
- ↑ "LOC.gov" (PDF). Retrieved 2011-06-13.
- General references
- Masica, Colin (1991), The Indo-Aryan Languages, Cambridge: Cambridge University Press, ISBN 978-0-521-29944-2.
- Snell, Rupert (2000), Teach Yourself Beginner's Hindi Script, Hodder & Stoughton, ISBN 978-0-07-141984-0.
- Salomon, Richard (2003), "Writing Systems of the Indo-Aryan Languages", in Cardona, George; Jain, Dhanesh, The Indo-Aryan Languages, Routledge, pp. 67–103, ISBN 978-0-415-77294-5.
- Verma, Sheela (2003), "Magahi", in Cardona, George; Jain, Dhanesh, The Indo-Aryan Languages, Routledge, pp. 498–514, ISBN 978-0-415-77294-5.
- Wikner, Charles (1996), A Practical Sanskrit Introductory.
Census and catalogues of manuscripts in Devanagari
Thousands of manuscripts of ancient and medieval era Sanskrit texts in Devanagari have been discovered since the 19th century. Major catalogs and census include:
- A Catalogue of Sanskrit Manuscripts in Private Libraries at Google Books, Medical Hall Press, Princeton University Archive
- A Descriptive Catalogue of the Sanskrit Manuscripts at Google Books, Vol 1: Upanishads, Friedrich Otto Schrader (Compiler), University of Michigan Library Archives
- A preliminary list of the Sanskrit and Prakrit manuscripts, Vedas, Sastras, Sutras, Schools of Hindu Philosophies, Arts, Design, Music and other fields, Friedrich Otto Schrader (Compiler), (Devanagiri manuscripts are identified by Character code De.)
- Catalogue of the Sanskrit Manuscripts, Part 1: Vedic Manuscripts, Harvard University Archives (mostly Devanagari)
- Catalogue of the Sanskrit Manuscripts, Part 4: Manuscripts of Hindu schools of Philosophy and Tantra, Harvard University Archives (mostly Devanagari)
- Catalogue of the Sanskrit Manuscripts, Part 5: Manuscripts of Medicine, Astronomy and Mathematics, Architecture and Technical Science Literature, Julius Eggeling (Compiler), Harvard University Archives (mostly Devanagari)
- Catalogue of the Sanskrit Manuscripts at Google Books, Part 6: Poetic, Epic and Purana Literature, Harvard University Archives (mostly Devanagari)
- David Pingree (1970-1981), Census of the Exact Sciences in Sanskrit: Volumes 1 through 5, American Philosophical Society, Manuscripts in various Indic scripts including Devanagari
External links
| Wikibooks has a book on the topic of: Devanagari |
| Wikimedia Commons has media related to Devanagari stroke order, |
- Unicode Chart for Devanagari
- Hindi/Devanagari Script Tutor
- Devnagari Unicode Legacy Font Converters
- Digital Nagari fonts, University of Chicago
- Devanagari in different fonts, Wazu, Japan (Alternate collection: Luc Devroye's comprehensive Indic Fonts, McGill University)
- Brick with Sanskrit inscription in Nagari script, 1217 CE, found in Uttar Pradesh, India (British Museum)
- Gazetteer of the Bombay Presidency, p. 30, at Google Books, Rudradaman’s inscription in Sanskrit Nagari script from 1st through 4th century CE (coins and epigraphy), found in Gujarat, India, pages 30–45
- Numerals and Text in Devanagari, 9th century temple in Gwalior Madhya Pradesh, India, Current Science
- On the Name Devanāgarī, Walter H. Maurer (1976), Journal of the American Oriental Society, Vol. 96, No. 1, pages 101-104