Design matrix
In statistics, a design matrix is a matrix of values of explanatory variables, often denoted by X, that is used in certain statistical models, e.g., the general linear model.[1][2][3] It can contain indicator variables (ones and zeros) that indicate group membership in an ANOVA, or it can contain values of continuous variables.
The design matrix contains data on the independent variables (also called explanatory variables) in statistical models which attempt to explain observed data on a response variable (often called a dependent variable) in terms of the explanatory variables. The theory relating to such models makes substantial use of matrix manipulations involving the design matrix: see for example linear regression. A notable feature of the concept of a design matrix is that it is able to represent a number of different experimental designs and statistical models, e.g., ANOVA, ANCOVA, and linear regression.
Definition
In a regression model, written in matrix-vector form as
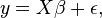
the matrix X is the design matrix, while y is the vector of observations on the dependent variable, 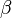 is a vector of response coefficients (one for each explanatory variable) and
is a vector of response coefficients (one for each explanatory variable) and  is a vector containing the values of the model's error term for the various observations. In the design matrix, each column is a vector of observations on one of the explanatory variables.
is a vector containing the values of the model's error term for the various observations. In the design matrix, each column is a vector of observations on one of the explanatory variables.
Examples
Simple Regression
This section gives an example of simple linear regression—that is, regression with only a single explanatory variable—with seven observations. The seven data points are {yi, xi}, for i = 1, 2, …, 7. The simple linear regression model is
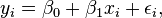
where 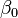 is the y-intercept and
is the y-intercept and 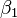 is the slope of the regression line. This model can be represented in matrix form as
is the slope of the regression line. This model can be represented in matrix form as
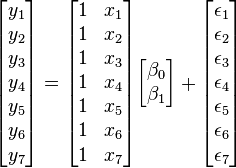
where the first column of ones in the design matrix allows estimation of the y-intercept while the second column contains the x-values associated with the corresponding y-values.
Multiple Regression
This section contains an example of multiple regression with two covariates (explanatory variables): w and x.
Again suppose that the data consist of seven observations, and that for each observed value to be predicted (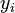 ), values wi and xi of the two covariates are also observed. The model to be considered is
), values wi and xi of the two covariates are also observed. The model to be considered is
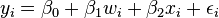
This model can be written in matrix terms as

Here the 7×3 matrix on the right side is the design matrix.
One-way ANOVA (Cell Means Model)
This section contains an example with a one-way analysis of variance (ANOVA) with three groups and seven observations. The given data set has the first three observations belonging to the first group, the following two observations belonging to the second group and the final two observations belonging to the third group. If the model to be fit is just the mean of each group, then the model is

which can be written
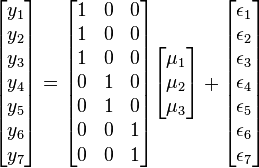
It should be emphasized that in this model  represents the mean of the
represents the mean of the  th group.
th group.
One-way ANOVA (offset from reference group)
The ANOVA model could be equivalently written as each group parameter 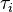 being an offset from some overall reference. Typically this reference point is taken to be one of the groups under consideration. This makes sense in the context of comparing multiple treatment groups to a control group and the control group is considered the "reference". In this example, group 1 was chosen to be the reference group. As such the model to be fit is
being an offset from some overall reference. Typically this reference point is taken to be one of the groups under consideration. This makes sense in the context of comparing multiple treatment groups to a control group and the control group is considered the "reference". In this example, group 1 was chosen to be the reference group. As such the model to be fit is

with the constraint that 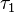 is zero.
is zero.
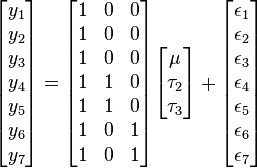
In this model 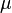 is the mean of the reference group and is the difference from group to the reference group. is not included in the matrix because its difference from the reference group (itself) is necessarily zero.
is the mean of the reference group and is the difference from group to the reference group. is not included in the matrix because its difference from the reference group (itself) is necessarily zero.
See also
References
- ↑ Everitt, B. S. (2002). Cambridge Dictionary of Statistics (2nd ed.). Cambridge, UK: Cambridge University Press. ISBN 0-521-81099-X.
- ↑ Box, G. E. P.; Tiao, G. C. (1992) [1973]. Bayesian Inference in Statistical Analysis. New York: John Wiley and Sons. ISBN 0-471-57428-7. (Section 8.1.1)
- ↑ Timm, Neil H. (2007). Applied Multivariate Analysis. Springer Science & Business Media. p. 107.