Delta method
In statistics, the delta method is a result concerning the approximate probability distribution for a function of an asymptotically normal statistical estimator from knowledge of the limiting variance of that estimator.
Univariate delta method
While the delta method generalizes easily to a multivariate setting, careful motivation of the technique is more easily demonstrated in univariate terms. Roughly, if there is a sequence of random variables Xn satisfying
![{\sqrt{n}[X_n-\theta]\,\xrightarrow{D}\,\mathcal{N}(0,\sigma^2)},](../I/m/830e1fdb054a0513b3dbd67bb564e615.png)
where θ and σ2 are finite valued constants and  denotes convergence in distribution, then
denotes convergence in distribution, then
![{\sqrt{n}[g(X_n)-g(\theta)]\,\xrightarrow{D}\,\mathcal{N}(0,\sigma^2[g'(\theta)]^2)}](../I/m/6c2860be64f7ec6ebe3785ac1d8ece1c.png)
for any function g satisfying the property that g′(θ) exists and is non-zero valued.
Proof in the univariate case
Demonstration of this result is fairly straightforward under the assumption that g′(θ) is continuous. To begin, we use the mean value theorem:
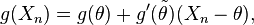
where 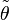 lies between Xn and θ.
Note that since
lies between Xn and θ.
Note that since 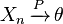 and
and 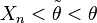 , it must be that
, it must be that 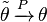 and since g′(θ) is continuous, applying the continuous mapping theorem yields
and since g′(θ) is continuous, applying the continuous mapping theorem yields
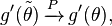
where 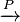 denotes convergence in probability.
denotes convergence in probability.
Rearranging the terms and multiplying by 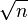 gives
gives
![\sqrt{n}[g(X_n)-g(\theta)]=g' \left (\tilde{\theta} \right )\sqrt{n}[X_n-\theta].](../I/m/af5cd82b17980e922db6863be4e3fc39.png)
Since
![{\sqrt{n}[X_n-\theta] \xrightarrow{D} \mathcal{N}(0,\sigma^2)}](../I/m/551cc3e671e261d46bcda1050ec35629.png)
by assumption, it follows immediately from appeal to Slutsky's Theorem that
![{\sqrt{n}[g(X_n)-g(\theta)] \xrightarrow{D} \mathcal{N}(0,\sigma^2[g'(\theta)]^2)}.](../I/m/68ecae947898d12e88ad9c99436bfa45.png)
This concludes the proof.
Proof with an explicit order of approximation
Alternatively, one can add one more step at the end, to obtain the order of approximation:
![\begin{align}
\sqrt{n}[g(X_n)-g(\theta)]&=g' \left (\tilde{\theta} \right )\sqrt{n}[X_n-\theta]=\sqrt{n}[X_n-\theta]\left[ g'(\tilde{\theta} )+g'(\theta)-g'(\theta)\right]\\
&=\sqrt{n}[X_n-\theta]\left[g'(\theta)\right]+\sqrt{n}[X_n-\theta]\left[ g'(\tilde{\theta} )-g'(\theta)\right]\\
&=\sqrt{n}[X_n-\theta]\left[g'(\theta)\right]+O_p(1)\cdot o_p(1)\\
&=\sqrt{n}[X_n-\theta]\left[g'(\theta)\right]+o_p(1)
\end{align}](../I/m/a3b1f7145e3dcdfb46f7b3f6d8072206.png)
This suggests that the error in the approximation converges to 0 in probability.
Multivariate delta method
By definition, a consistent estimator B converges in probability to its true value β, and often a central limit theorem can be applied to obtain asymptotic normality:
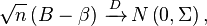
where n is the number of observations and Σ is a (symmetric positive semi-definite) covariance matrix. Suppose we want to estimate the variance of a function h of the estimator B. Keeping only the first two terms of the Taylor series, and using vector notation for the gradient, we can estimate h(B) as
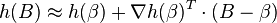
which implies the variance of h(B) is approximately
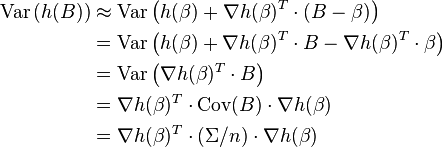
One can use the mean value theorem (for real-valued functions of many variables) to see that this does not rely on taking first order approximation.
The delta method therefore implies that
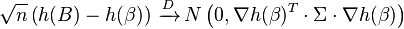
or in univariate terms,
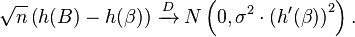
Example
Suppose Xn is Binomial with parameters ![p \in (0,1]](../I/m/01bb4552e95bc8efa5de99f945421a3b.png) and n. Since
and n. Since
![{\sqrt{n} \left[ \frac{X_n}{n}-p \right]\,\xrightarrow{D}\,N(0,p (1-p))},](../I/m/77702e901106201df589bf940794b4b0.png)
we can apply the Delta method with g(θ) = log(θ) to see
![{\sqrt{n} \left[ \log\left( \frac{X_n}{n}\right)-\log(p)\right] \,\xrightarrow{D}\,N(0,p (1-p) [1/p]^2)}](../I/m/2af8b93383f2d978abc101bcfcc05fe1.png)
Hence, the variance of 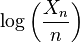 is approximately
is approximately
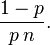
Note that since p>0, 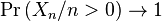 as
as  , so with probability one,
, so with probability one, 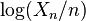 is finite for large n.
is finite for large n.
Moreover, if 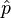 and
and  are estimates of different group rates from independent samples of sizes n and m respectively, then the logarithm of the estimated relative risk
are estimates of different group rates from independent samples of sizes n and m respectively, then the logarithm of the estimated relative risk 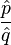 is approximately normally distributed with variance that can be estimated by
is approximately normally distributed with variance that can be estimated by
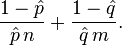
This is useful to construct a hypothesis test or to make a confidence interval for the relative risk.
Note
The delta method is often used in a form that is essentially identical to that above, but without the assumption that Xn or B is asymptotically normal. Often the only context is that the variance is "small". The results then just give approximations to the means and covariances of the transformed quantities. For example, the formulae presented in Klein (1953, p. 258) are:
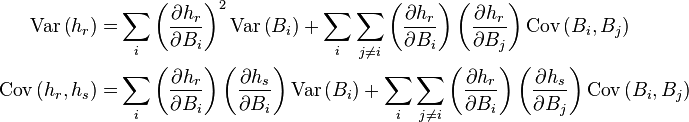
where hr is the rth element of h(B) and Biis the ith element of B. The only difference is that Klein stated these as identities, whereas they are actually approximations.
See also
- Taylor expansions for the moments of functions of random variables
- Variance-stabilizing transformation
References
- Casella, G. and Berger, R. L. (2002), Statistical Inference, 2nd ed.
- Cramér, H. (1946), Mathematical Methods of Statistics, p. 353.
- Davison, A. C. (2003), Statistical Models, pp. 33–35.
- Greene, W. H. (2003), Econometric Analysis, 5th ed., pp. 913f.
- Klein, L. R. (1953), A Textbook of Econometrics, p. 258.
- Oehlert, G. W. (1992), A Note on the Delta Method, The American Statistician, Vol. 46, No. 1, p. 27-29. http://www.jstor.org/stable/2684406
- Lecture notes
- More lecture notes
- Explanation from Stata software corporation