Data matrix (multivariate statistics)
In multivariate statistics, a data matrix is a matrix of data of dimension n-by-p, where n is the number of samples observed, and p is the number of variables (features) measured in all samples.[1][2]
In this representation different rows typically represent different repetitions of an experiment, while columns represent different types of data (say, the results from particular probes). For example, suppose an experiment is run where 10 people are pulled off the street and asked four questions. The data matrix M would be a 10×4 matrix (meaning 10 rows and 4 columns). The datum in row i and column j of this matrix would be the answer of the i th person to the j th question.
Related topics
This arrangement reflects the convention most commonly used to present the linear regression problem, as requiring the estimation of B in the equation
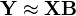
where Y is an n-by-q data matrix containing the observed dependent variables, X is the design matrix, an n-by-p data matrix containing the values of the explanatory variables, and B is a p-by-q matrix of unknown regression coefficients.
References
- ↑ Johnson, Richard A; Wichern, Dean W (2001). Applied Multivariate Statistical Analysis. Pearson. p. 111-112. ISBN 0131877151.
- ↑ "Basic Concepts for Multivariate Statistics p.2" (PDF). SAS Institute.