Data-flow analysis
Data-flow analysis is a technique for gathering information about the possible set of values calculated at various points in a computer program. A program's control flow graph (CFG) is used to determine those parts of a program to which a particular value assigned to a variable might propagate. The information gathered is often used by compilers when optimizing a program. A canonical example of a data-flow analysis is reaching definitions.
A simple way to perform data-flow analysis of programs is to set up data-flow equations for each node of the control flow graph and solve them by repeatedly calculating the output from the input locally at each node until the whole system stabilizes, i.e., it reaches a fixpoint. This general approach was developed by Gary Kildall while teaching at the Naval Postgraduate School.[1]
Basic principles
It is the process of collecting information about the way the variables are used, defined in the program. Data-flow analysis attempts to obtain particular information at each point in a procedure. Usually, it is enough to obtain this information at the boundaries of basic blocks, since from that it is easy to compute the information at points in the basic block. In forward flow analysis, the exit state of a block is a function of the block's entry state. This function is the composition of the effects of the statements in the block. The entry state of a block is a function of the exit states of its predecessors. This yields a set of data-flow equations:
For each block b:


In this,  is the transfer function of the block
is the transfer function of the block 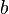 . It works on the entry state
. It works on the entry state  , yielding the exit state
, yielding the exit state 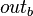 . The join operation
. The join operation  combines the exit states of the predecessors
combines the exit states of the predecessors  of , yielding the entry state of .
of , yielding the entry state of .
After solving this set of equations, the entry and/or exit states of the blocks can be used to derive properties of the program at the block boundaries. The transfer function of each statement separately can be applied to get information at a point inside a basic block.
Each particular type of data-flow analysis has its own specific transfer function and join operation. Some data-flow problems require backward flow analysis. This follows the same plan, except that the transfer function is applied to the exit state yielding the entry state, and the join operation works on the entry states of the successors to yield the exit state.
The entry point (in forward flow) plays an important role: Since it has no predecessors, its entry state is well defined at the start of the analysis. For instance, the set of local variables with known values is empty. If the control flow graph does not contain cycles (there were no explicit or implicit loops in the procedure) solving the equations is straightforward. The control flow graph can then be topologically sorted; running in the order of this sort, the entry states can be computed at the start of each block, since all predecessors of that block have already been processed, so their exit states are available. If the control flow graph does contain cycles, a more advanced algorithm is required.
An iterative algorithm
The most common way of solving the data-flow equations is by using an iterative algorithm. It starts with an approximation of the in-state of each block. The out-states are then computed by applying the transfer functions on the in-states. From these, the in-states are updated by applying the join operations. The latter two steps are repeated until we reach the so-called fixpoint: the situation in which the in-states (and the out-states in consequence) do not change.
A basic algorithm for solving data-flow equations is the round-robin iterative algorithm:
- for i ← 1 to N
- initialize node i
- while (sets are still changing)
- for i ← 1 to N
- recompute sets at node i
- for i ← 1 to N
Convergence
To be usable, the iterative approach should actually reach a fixpoint. This can be guaranteed by imposing constraints on the combination of the value domain of the states, the transfer functions and the join operation.
The value domain should be a partial order with finite height (i.e., there are no infinite ascending chains 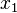 <
< 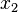 < ...). The combination of the transfer function and the join operation should be monotonic with respect to this partial order. Monotonicity ensures that on each iteration the value will either stay the same or will grow larger, while finite height ensures that it cannot grow indefinitely. Thus we will ultimately reach a situation where T(x) = x for all x, which is the fixpoint.
< ...). The combination of the transfer function and the join operation should be monotonic with respect to this partial order. Monotonicity ensures that on each iteration the value will either stay the same or will grow larger, while finite height ensures that it cannot grow indefinitely. Thus we will ultimately reach a situation where T(x) = x for all x, which is the fixpoint.
The work list approach
It is easy to improve on the algorithm above by noticing that the in-state of a block will not change if the out-states of its predecessors don't change. Therefore, we introduce a work list: a list of blocks that still need to be processed. Whenever the out-state of a block changes, we add its successors to the work list. In each iteration, a block is removed from the work list. Its out-state is computed. If the out-state changed, the block's successors are added to the work list. For efficiency, a block should not be in the work list more than once.
The algorithm is started by putting information generating blocks in the work list. It terminates when the work list is empty.
The order matters
The efficiency of iteratively solving data-flow equations is influenced by the order at which local nodes are visited.[2] Furthermore, it depends, whether the data-flow equations are used for forward or backward data-flow analysis over the CFG. Intuitively, in a forward flow problem, it would be fastest if all predecessors of a block have been processed before the block itself, since then the iteration will use the latest information. In the absence of loops it is possible to order the blocks in such a way that the correct out-states are computed by processing each block only once.
In the following, a few iteration orders for solving data-flow equations are discussed (a related concept to iteration order of a CFG is tree traversal of a tree).
- Random order - This iteration order is not aware whether the data-flow equations solve a forward or backward data-flow problem. Therefore, the performance is relatively poor compared to specialized iteration orders.
- Postorder - This is a typical iteration order for backward data-flow problems. In postorder iteration, a node is visited after all its successor nodes have been visited. Typically, the postorder iteration is implemented with the depth-first strategy.
- Reverse postorder - This is a typical iteration order for forward data-flow problems. In reverse-postorder iteration, a node is visited before any of its successor nodes has been visited, except when the successor is reached by a back edge. (Note that this is not the same as preorder.)
Initialization
The initial value of the in-states is important to obtain correct and accurate results. If the results are used for compiler optimizations, they should provide conservative information, i.e. when applying the information, the program should not change semantics. The iteration of the fixpoint algorithm will take the values in the direction of the maximum element. Initializing all blocks with the maximum element is therefore not useful. At least one block starts in a state with a value less than the maximum. The details depend on the data-flow problem. If the minimum element represents totally conservative information, the results can be used safely even during the data-flow iteration. If it represents the most accurate information, fixpoint should be reached before the results can be applied.
Examples
The following are examples of properties of computer programs that can be calculated by data-flow analysis. Note that the properties calculated by data-flow analysis are typically only approximations of the real properties. This is because data-flow analysis operates on the syntactical structure of the CFG without simulating the exact control flow of the program. However, to be still useful in practice, a data-flow analysis algorithm is typically designed to calculate an upper respectively lower approximation of the real program properties.
Forward Analysis
The reaching definition analysis calculates for each program point the set of definitions that may potentially reach this program point.
1 if b==4 then
2 a = 5;
3 else
4 a = 3;
5 endif
6
7 if a < 4 then
8 ...
|
The reaching definition of variable |
Backward Analysis
The live variable analysis calculates for each program point the variables that may be potentially read afterwards before their next write update. The result is typically used by dead code elimination to remove statements that assign to a variable whose value is not used afterwards.
The out-state of a block is the set of variables that are live at the end of the block. Its in-state is the set of variable that is live at the start of it. The out-state is the union of the in-states of the blocks successors. The transfer function of a statement is applied by making the variables that are written dead, then making the variables that are read live.
Initial Code:
b1: a = 3;
b = 5;
d = 4;
x = 100;
if a > b then
b2: c = a + b;
d = 2;
b3: endif
c = 4;
return b * d + c;
|
Backward Analysis:
// in: {}
b1: a = 3;
b = 5;
d = 4;
x = 100; //x is never being used later thus not in the out set {a,b,d}
if a > b then
// out: {a,b,d} //union of all (in) successors of b1 => b2: {a,b}, and b3:{b,d}
// in: {a,b}
b2: c = a + b;
d = 2;
// out: {b,d}
// in: {b,d}
b3: endif
c = 4;
return b * d + c;
// out:{}
|
The in-state of b3 only contains b and d, since c has been written. The out-state of b1 is the union of the in-states of b2 and b3. The definition of c in b2 can be removed, since c is not live immediately after the statement.
Solving the data-flow equations starts with initializing all in-states and out-states to the empty set. The work list is initialized by inserting the exit point (b3) in the work list (typical for backward flow). Its computed in-state differs from the previous one, so its predecessors b1 and b2 are inserted and the process continues. The progress is summarized in the table below.
| processing | out-state | old in-state | new in-state | work list |
|---|---|---|---|---|
| b3 | {} | {} | {b,d} | (b1,b2) |
| b1 | {b,d} | {} | {} | (b2) |
| b2 | {b,d} | {} | {a,b} | (b1) |
| b1 | {a,b,d} | {} | {} | () |
Note that b1 was entered in the list before b2, which forced processing b1 twice (b1 was re-entered as predecessor of b2). Inserting b2 before b1 would have allowed earlier completion.
Initializing with the empty set is an optimistic initialization: all variables start out as dead. Note that the out-states cannot shrink from one iteration to the next, although the out-state can be smaller than the in-state. This can be seen from the fact that after the first iteration the out-state can only change by a change of the in-state. Since the in-state starts as the empty set, it can only grow in further iterations.
Other approaches
In 2002, Markus Mohnen described a new method of data-flow analysis that does not require the explicit construction of a data-flow graph,[3] instead relying on abstract interpretation of the program and keeping a working set of program counters. At each conditional branch, both targets are added to the working set. Each path is followed for as many instructions as possible (until end of program or until it has looped with no changes), and then removed from the set and the next program counter retrieved.
Bit vector problems
The examples above are problems in which the data-flow value is a set, e.g. the set of reaching definitions (Using a bit for a definition position in the program), or the set of live variables. These sets can be represented efficiently as bit vectors, in which each bit represents set membership of one particular element. Using this representation, the join and transfer functions can be implemented as bitwise logical operations. The join operation is typically union or intersection, implemented by bitwise logical or and logical and. The transfer function for each block can be decomposed in so-called gen and kill sets.
As an example, in live-variable analysis, the join operation is union. The kill set is the set of variables that are written in a block, whereas the gen set is the set of variables that are read without being written first. The data-flow equations become


In logical operations, this reads as
out(b) = 0 for s in succ(b) out(b) = out(b) or in(s) in(b) = (out(b) and not kill(b)) or gen(b)
Sensitivities
Data-flow analysis is inherently flow-sensitive. Data-flow analysis is typically path-insensitive, though it is possible to define data-flow equations that yield a path-sensitive analysis.
- A flow-sensitive analysis takes into account the order of statements in a program. For example, a flow-insensitive pointer alias analysis may determine "variables x and y may refer to the same location", while a flow-sensitive analysis may determine "after statement 20, variables x and y may refer to the same location".
- A path-sensitive analysis computes different pieces of analysis information dependent on the predicates at conditional branch instructions. For instance, if a branch contains a condition
x>0x<=0x>0 - A context-sensitive analysis is an interprocedural analysis that considers the calling context when analyzing the target of a function call. In particular, using context information one can jump back to the original call site, whereas without that information, the analysis information has to be propagated back to all possible call sites, potentially losing precision.
List of data-flow analyses
- Reaching definitions
- Liveness analysis
- Definite assignment analysis
- Available expression
- Constant propagation
See also
References
- ↑ Kildall, Gary (1973). "A Unified Approach to Global Program Optimization". Proceedings of the 1st Annual ACM SIGACT-SIGPLAN Symposium on Principles of Programming Languages: 194–206. doi:10.1145/512927.512945. Retrieved 2006-11-20.
- ↑ Keith D. Cooper, Timothy J. Harvey, Ken Kennedy. "Iterative data-flow analysis, revisited".
- ↑ Mohnen, Markus (2002). "A Graph-Free Approach to Data-Flow Analysis". Lecture Notes in Computer Science. Lecture Notes in Computer Science 2304: 185–213. doi:10.1007/3-540-45937-5_6. ISBN 978-3-540-43369-9. Retrieved 2008-12-02.
Further reading
- Cooper, Keith D. and Torczon, Linda. Engineering a Compiler. Morgan Kaufmann. 2005.
- Muchnick, Steven S. Advanced Compiler Design and Implementation. Morgan Kaufmann. 1997.
- Hecht, Matthew S. Flow Analysis of Computer Programs. Elsevier North-Holland Inc. 1977.
- Khedker, Uday P. Sanyal, Amitabha Karkare, Bageshri. Data Flow Analysis: Theory and Practice, CRC Press (Taylor and Francis Group). 2009.
- Flemming Nielson, Hanne Riis Nielson, Chris Hankin. Principles of Program Analysis. Springer. 2005.
| ||||||||||||||||||||||||||||||||||||||