Contingency table
In statistics, a contingency table is a type of table in a matrix format that displays the (multivariate) frequency distribution of the variables. They are heavily used in survey research, business intelligence, engineering and scientific research. They provide a basic picture of the interrelation between two variables and can help find interactions between them. The term contingency table was first used by Karl Pearson in "On the Theory of Contingency and Its Relation to Association and Normal Correlation",[1] part of the Drapers' Company Research Memoirs Biometric Series I published in 1904.
A crucial problem of multivariate statistics is finding (direct-)dependence structure underlying the variables contained in high-dimensional contingency tables. If some of the conditional independences are revealed, then even the storage of the data can be done in a smarter way (see Lauritzen (2002)). In order to do this one can use information theory concepts, which gain the information only from the distribution of probability, which can be expressed easily from the contingency table by the relative frequencies.
Example
Suppose that we have two variables, sex (male or female) and handedness (right- or left-handed). Further suppose that 100 individuals are randomly sampled from a very large population as part of a study of sex differences in handedness. A contingency table can be created to display the numbers of individuals who are male and right-handed, male and left-handed, female and right-handed, and female and left-handed. Such a contingency table is shown below.
Handedness Gender | Right-handed | Left-handed | Total |
|---|---|---|---|
| Male | 43 | 9 | 52 |
| Female | 44 | 4 | 48 |
| Total | 87 | 13 | 100 |
The numbers of the males, females, and right- and left-handed individuals are called marginal totals. The grand total, i.e., the total number of individuals represented in the contingency table, is the number in the bottom right corner.
The table allows us to see at a glance that the proportion of men who are right-handed is about the same as the proportion of women who are right-handed although the proportions are not identical. The significance of the difference between the two proportions can be assessed with a variety of statistical tests including Pearson's chi-squared test, the G-test, Fisher's exact test, and Barnard's test, provided the entries in the table represent individuals randomly sampled from the population about which we want to draw a conclusion. If the proportions of individuals in the different columns vary significantly between rows (or vice versa), we say that there is a contingency between the two variables. In other words, the two variables are not independent. If there is no contingency, we say that the two variables are independent.
The example above is the simplest kind of contingency table, a table in which each variable has only two levels; this is called a 2 × 2 contingency table. In principle, any number of rows and columns may be used. There may also be more than two variables, but higher order contingency tables are difficult to represent on paper. The relation between ordinal variables, or between ordinal and categorical variables, may also be represented in contingency tables, although such a practice is rare.
Standard contents of a contingency table
- Multiple columns (historically, they were designed to use up all the white space of a printed page). Where each column refers to a specific sub-group in the population (e.g., men), the columns are sometimes referred to as banner points or cuts (and the rows are sometimes referred to as stubs).
- Significance tests. Typically, either column comparisons, which test for differences between columns and display these results using letters, or, cell comparisons, which use color or arrows to identify a cell in a table that stands out in some way (as in the example above).
- Nets or netts which are sub-totals.
- One or more of: percentages, row percentages, column percentages, indexes or averages.
- Unweighted sample sizes (i.e., counts).
Measures of association
The degree of association between the two variables can be assessed by a number of coefficients: the simplest is the phi coefficient defined by
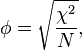
where χ2 is derived from Pearson's chi-squared test, and N is the grand total of observations. φ varies from 0 (corresponding to no association between the variables) to 1 or −1 (complete association or complete inverse association). This coefficient can only be calculated for frequency data represented in 2 × 2 tables. φ can reach a minimum value −1.00 and a maximum value of 1.00 only when every marginal proportion is equal to .50 (and two diagonal cells are empty). Otherwise, the phi coefficient cannot reach those minimal and maximal values.[2]
Alternatives include the tetrachoric correlation coefficient (also only applicable to 2 × 2 tables), the contingency coefficient C, and Cramér's V.
C suffers from the disadvantage that it does not reach a maximum of 1 or the minimum of −1; the highest it can reach in a 2 × 2 table is 0.707; the maximum it can reach in a 4 × 4 table is 0.870. It can reach values closer to 1 in contingency tables with more categories. It should, therefore, not be used to compare associations among tables with different numbers of categories.[3] Moreover, it does not apply to asymmetrical tables (those where the numbers of row and columns are not equal).
The formulae for the C and V coefficients are:
-
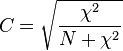 and
and
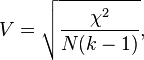
k being the number of rows or the number of columns, whichever is less.
C can be adjusted so it reaches a maximum of 1 when there is complete association in a table of any number of rows and columns by dividing C by 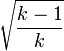 (recall that C only applies to tables in which the number of rows is equal to the number of columns and therefore equal to k).
(recall that C only applies to tables in which the number of rows is equal to the number of columns and therefore equal to k).
The tetrachoric correlation coefficient assumes that the variable underlying each dichotomous measure is normally distributed.[4] The tetrachoric correlation coefficient provides "a convenient measure of [the Pearson product-moment] correlation when graduated measurements have been reduced to two categories."[5] The tetrachoric correlation should not be confused with the Pearson product-moment correlation coefficient computed by assigning, say, values 0 and 1 to represent the two levels of each variable (which is mathematically equivalent to the phi coefficient). An extension of the tetrachoric correlation to tables involving variables with more than two levels is the polychoric correlation coefficient.
The lambda coefficient is a measure of the strength of association of the cross tabulations when the variables are measured at the nominal level. Values range from 0 (no association) to 1 (the theoretical maximum possible association). Asymmetric lambda measures the percentage improvement in predicting the dependent variable. Symmetric lambda measures the percentage improvement when prediction is done in both directions.
The uncertainty coefficient is another measure for variables at the nominal level.
The values range from −1 (100% negative association, or perfect inversion) to +1 (100% positive association, or perfect agreement). A value of zero indicates the absence of association.
- Gamma test: No adjustment for either table size or ties.
- Kendall tau: Adjustment for ties.
See also
- Confusion matrix
- The pivot operation in spreadsheet software can be used to generate a contingency table from sampling data.
- TPL Tables is a tool for generating and printing cross tabs.
- The iterative proportional fitting procedure essentially manipulates contingency tables to match altered joint distributions or marginal sums.
- The multivariate statistics in special multivariate discrete probability distributions. Some procedures used in this context can be used in dealing with contingency tables.
References
- ↑ Karl Pearson, F.R.S. (1904). Mathematical contributions to the theory of evolution (PDF). Dulau and Co.
- ↑ Ferguson, G. A. (1966). Statistical analysis in psychology and education. New York: McGraw–Hill.
- ↑ Smith, S. C., & Albaum, G. S. (2004) Fundamentals of marketing research. Sage: Thousand Oaks, CA. p. 631
- ↑ Ferguson.
- ↑ Ferguson, p. 244
- Andersen, Erling B. 1980. Discrete Statistical Models with Social Science Applications. North Holland, 1980.
- Bishop, Y. M. M.; Fienberg, S. E.; Holland, P. W. (1975). Discrete Multivariate Analysis: Theory and Practice. MIT Press. ISBN 978-0-262-02113-5. MR 381130.
- Christensen, Ronald (1997). Log-linear models and logistic regression. Springer Texts in Statistics (Second ed.). New York: Springer-Verlag. pp. xvi+483. ISBN 0-387-98247-7. MR 1633357.
- Lauritzen, Steffen L. (2002 electronic (1979, 1982, 1989)). Lectures on Contingency Tables (PDF) (updated electronic version of the (University of Aalborg) 3rd (1989) ed.). Check date values in:
|date=(help) - Gokhale, D. V.; Kullback, Solomon (1978). The Information in Contingency Tables. Marcel Dekker. ISBN 0-824-76698-9.
External links
| Wikimedia Commons has media related to Contingency tables. |
- On-line analysis of contingency tables: calculator with examples
- Interactive cross tabulation, chi-squared independent test & tutorial
- Fisher and chi-squared calculator of 2 × 2 contingency table
- More Correlation Coefficients
- Nominal Association: Phi, Contingency Coefficient, Tschuprow's T, Cramer's V, Lambda, Uncertainty Coefficient
- Customer Insight com Cross Tabulation
- The POWERMUTT Project: IV. DISPLAYING CATEGORICAL DATA
- StATS: Steves Attempt to Teach Statistics Odds ratio versus relative risk (January 9, 2001)
- Epi Info Community Health Assessment Tutorial Lesson 5 Analysis: Creating Statistics
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||