Analysis of parallel algorithms
This article discusses the analysis of parallel algorithms. Like in the analysis of "ordinary", sequential, algorithms, one is typically interested in asymptotic bounds on the resource consumption (mainly time spent computing), but the analysis is performed in the presence of multiple processor units that cooperate to perform computations. Thus, one can determine not only how many "steps" a computation takes, but also how much faster it becomes as the number of processors goes up.
Overview
Suppose computations are executed on a machine that has p processors. Let Tp denote the time that expires between the start of the computation and its end. Analysis of the computation's running time focuses on the following notions:
- The work of a computation executed by p processors is the total number of primitive operations that the processors perform.[1] Ignoring communication overhead from synchronizing the processors, this is equal to the time used to run the computation on a single processor, denoted T1.
- The span is the length of the longest series of operations that have to be performed sequentially due to data dependencies (the critical path). The span may also be called the critical path length or the depth of the computation.[2] Minimizing the span is important in designing parallel algorithms, because the span determines the shortest possible execution time.[3] Alternatively, the span can be defined as the time T∞ spent computing using an idealized machine with an infinite number of processors.[4]
- The cost of the computation is the quantity pTp. This expresses the total time spent, by all processors, in both computing and waiting.[1]
Several useful results follow from the definitions of work, span and cost:
- Work law. The cost is always at least the work: pTp ≥ T1. This follows from the fact that p processors can perform at most p operations in parallel.[1][4]
- Span law. A finite number p of processors cannot outperform an infinite number, so that Tp ≥ T∞.[4]
Using these definitions and laws, the following measures of performance can be given:
- Speedup is the gain in speed made by parallel execution compared to sequential execution: Sp = T1 ∕ Tp. When the speedup is Ω(n) for input size n (using big O notation), the speedup is linear, which is optimal in simple models of computation because the work law implies that T1 ∕ Tp ≤ p (super-linear speedup can occur in practice due to memory hierarchy effects). The situation T1 ∕ Tp = p is called perfect linear speedup.[4] An algorithm that exhibits linear speedup is said to be scalable.[1]
- Efficiency is the speedup per processor, Sp ∕ p.[1]
- Parallelism is the ratio T1 ∕ T∞. It represents the maximum possible speedup on any number of processors. By the span law, the parallelism bounds the speedup: if p > T1 ∕ T∞, then T1 ∕ Tp ≤ T1 ∕ T∞ < p.[4]
- The slackness is T1 ∕ (pT∞). A slackness less than one implies (by the span law) that perfect linear speedup is impossible on p processors.[4]
Execution on a limited number of processors
Analysis of parallel algorithms is usually carried out under the assumption that an unbounded number of processors is available. This is unrealistic, but not a problem, since any computation that can run in parallel on N processors can be executed on p < N processors by letting each processor execute multiple units of work. A result called Brent's law states that one can perform such a "simulation" in time Tp, bounded by[5]
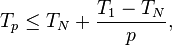
or, less precisely,[1]
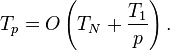
An alternative statement of the law bounds Tp above and below by
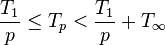 .
.
showing that the span (depth) T∞ and the work T1 together provide reasonable bounds on the computation time.[2]
References
- 1 2 3 4 5 6 Casanova, Henri; Legrand, Arnaud; Robert, Yves (2008). Parallel Algorithms. CRC Press. p. 10.
- 1 2 Blelloch, Guy (1996). "Programming Parallel Algorithms" (PDF). Communications of the ACM 39 (3): 85–97. doi:10.1145/227234.227246.
- ↑ Michael McCool; James Reinders; Arch Robison (2013). Structured Parallel Programming: Patterns for Efficient Computation. Elsevier. pp. 4–5.
- 1 2 3 4 5 6 Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2009) [1990]. Introduction to Algorithms (3rd ed.). MIT Press and McGraw-Hill. pp. 779–784. ISBN 0-262-03384-4.
- ↑ Gustafson, John L. (2011). "Brent's Theorem". Encyclopedia of Parallel Computing. pp. 182–185.
| ||||||||||||||||||||||||||||||||||||||||||||||