Covariance matrix


In probability theory and statistics, a covariance matrix (also known as dispersion matrix or variance–covariance matrix) is a matrix whose element in the i, j position is the covariance between the i th and j th elements of a random vector (that is, of a vector of random variables). Each element of the vector is a scalar random variable, either with a finite number of observed empirical values or with a finite or infinite number of potential values specified by a theoretical joint probability distribution of all the random variables.
Intuitively, the covariance matrix generalizes the notion of variance to multiple dimensions. As an example, the variation in a collection of random points in two-dimensional space cannot be characterized fully by a single number, nor would the variances in the x and y directions contain all of the necessary information; a 2×2 matrix would be necessary to fully characterize the two-dimensional variation.
Because the covariance of the i th random variable with itself is simply that random variable's variance, each element on the principal diagonal of the covariance matrix is the variance of one of the random variables. Because the covariance of the i th random variable with the j th one is the same thing as the covariance of the j th random variable with the i th one, every covariance matrix is symmetric. In addition, every covariance matrix is positive semi-definite.
Definition
Throughout this article, boldfaced unsubscripted X and Y are used to refer to random vectors, and unboldfaced subscripted Xi and Yi are used to refer to random scalars.
If the entries in the column vector
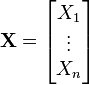
are random variables, each with finite variance, then the covariance matrix Σ is the matrix whose (i, j) entry is the covariance
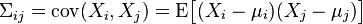
where
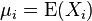
is the expected value of the ith entry in the vector X. In other words,
![\Sigma
= \begin{bmatrix}
\mathrm{E}[(X_1 - \mu_1)(X_1 - \mu_1)] & \mathrm{E}[(X_1 - \mu_1)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_1 - \mu_1)(X_n - \mu_n)] \\ \\
\mathrm{E}[(X_2 - \mu_2)(X_1 - \mu_1)] & \mathrm{E}[(X_2 - \mu_2)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_2 - \mu_2)(X_n - \mu_n)] \\ \\
\vdots & \vdots & \ddots & \vdots \\ \\
\mathrm{E}[(X_n - \mu_n)(X_1 - \mu_1)] & \mathrm{E}[(X_n - \mu_n)(X_2 - \mu_2)] & \cdots & \mathrm{E}[(X_n - \mu_n)(X_n - \mu_n)]
\end{bmatrix}.](../I/m/58572fa5b05e778f5a5eff9ec1b3ddb6.png)
The inverse of this matrix, 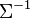 is the inverse covariance matrix, also known as the concentration matrix or precision matrix;[1] see precision (statistics). The elements of the precision matrix have an interpretation in terms of partial correlations and partial variances.
is the inverse covariance matrix, also known as the concentration matrix or precision matrix;[1] see precision (statistics). The elements of the precision matrix have an interpretation in terms of partial correlations and partial variances.
Generalization of the variance
The definition above is equivalent to the matrix equality
This form can be seen as a generalization of the scalar-valued variance to higher dimensions. Recall that for a scalar-valued random variable X
![\sigma^2 = \mathrm{var}(X)
= \mathrm{E}[(X-\mathrm{E}(X))^2] = \mathrm{E}[(X-\mathrm{E}(X))\cdot(X-\mathrm{E}(X))].\,](../I/m/6b790c0ee7f3b205075c68ce048aa9a4.png)
Indeed, the entries on the diagonal of the covariance matrix 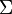 are the variances of each element of the vector
are the variances of each element of the vector  .
.
Correlation matrix
A quantity closely related to the covariance matrix is the correlation matrix, the matrix of Pearson product-moment correlation coefficients between each of the random variables in the random vector , which can be written
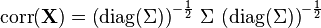
where 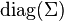 is the matrix of the diagonal elements of (i.e., a diagonal matrix of the variances of
is the matrix of the diagonal elements of (i.e., a diagonal matrix of the variances of 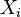 for
for  ).
).
Equivalently, the correlation matrix can be seen as the covariance matrix of the standardized random variables 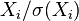 for .
for .
Each element on the principal diagonal of a correlation matrix is the correlation of a random variable with itself, which always equals 1. Each off-diagonal element is between 1 and –1 inclusive.
Conflicting nomenclatures and notations
Nomenclatures differ. Some statisticians, following the probabilist William Feller, call the matrix the variance of the random vector 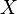 , because it is the natural generalization to higher dimensions of the 1-dimensional variance. Others call it the covariance matrix, because it is the matrix of covariances between the scalar components of the vector . Thus
, because it is the natural generalization to higher dimensions of the 1-dimensional variance. Others call it the covariance matrix, because it is the matrix of covariances between the scalar components of the vector . Thus
![\operatorname{var}(\mathbf{X})
=
\operatorname{cov}(\mathbf{X})
=
\mathrm{E}
\left[
(\mathbf{X} - \mathrm{E} [\mathbf{X}])
(\mathbf{X} - \mathrm{E} [\mathbf{X}])^{\rm T}
\right].](../I/m/fb026e930dd63e0ecda3e9ceb01cde09.png)
However, the notation for the cross-covariance between two vectors is standard:
![\operatorname{cov}(\mathbf{X},\mathbf{Y})
=
\mathrm{E}
\left[
(\mathbf{X} - \mathrm{E}[\mathbf{X}])
(\mathbf{Y} - \mathrm{E}[\mathbf{Y}])^{\rm T}
\right].](../I/m/87b20b2f2fb1418eeb77042f584d9213.png)
The var notation is found in William Feller's two-volume book An Introduction to Probability Theory and Its Applications,[2] but both forms are quite standard and there is no ambiguity between them.
The matrix is also often called the variance-covariance matrix since the diagonal terms are in fact variances.
Properties
For ![\Sigma=\mathrm{E} \left[ \left( \mathbf{X} - \mathrm{E}[\mathbf{X}] \right) \left( \mathbf{X} - \mathrm{E}[\mathbf{X}] \right)^{\rm T} \right]](../I/m/7d13b00c4100b3f76afc9a188466731d.png) and
and 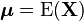 , where X is a random p-dimensional variable and Y a random q-dimensional variable, the following basic properties apply:[3]
, where X is a random p-dimensional variable and Y a random q-dimensional variable, the following basic properties apply:[3]
-
-
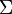 is positive-semidefinite and symmetric.
is positive-semidefinite and symmetric. -
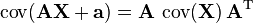
-
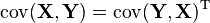
-
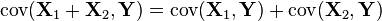
- If p = q, then
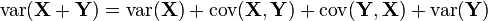
-
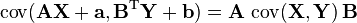
- If and
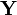 are independent or uncorrelated, then
are independent or uncorrelated, then 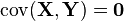
where 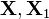 and
and 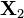 are random p×1 vectors, is a random q×1 vector,
are random p×1 vectors, is a random q×1 vector,  is a q×1 vector,
is a q×1 vector,  is a p×1 vector, and
is a p×1 vector, and 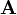 and
and 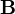 are q×p matrices of constants.
are q×p matrices of constants.
This covariance matrix is a useful tool in many different areas. From it a transformation matrix can be derived, called a whitening transformation, that allows one to completely decorrelate the data or, from a different point of view, to find an optimal basis for representing the data in a compact way (see Rayleigh quotient for a formal proof and additional properties of covariance matrices). This is called principal components analysis (PCA) and the Karhunen-Loève transform (KL-transform).
Block matrices
The joint mean 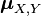 and joint covariance matrix
and joint covariance matrix 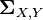 of
of 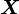 and
and 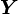 can be written in block form
can be written in block form
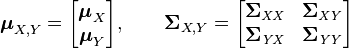
where 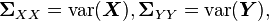 and
and 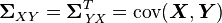 .
.
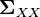 and
and 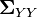 can be identified as the variance matrices of the marginal distributions for and respectively.
can be identified as the variance matrices of the marginal distributions for and respectively.
If and are jointly normally distributed,
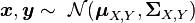 ,
,
then the conditional distribution for given is given by
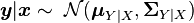 ,[4]
,[4]
defined by conditional mean
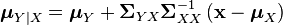
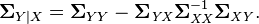
The matrix ΣYXΣXX−1 is known as the matrix of regression coefficients, while in linear algebra ΣY|X is the Schur complement of ΣXX in ΣX,Y
The matrix of regression coefficients may often be given in transpose form, ΣXX−1ΣXY, suitable for post-multiplying a row vector of explanatory variables xT rather than pre-multiplying a column vector x. In this form they correspond to the coefficients obtained by inverting the matrix of the normal equations of ordinary least squares (OLS).
As a linear operator
Applied to one vector, the covariance matrix maps a linear combination, c, of the random variables, X, onto a vector of covariances with those variables: 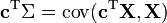 . Treated as a bilinear form, it yields the covariance between the two linear combinations:
. Treated as a bilinear form, it yields the covariance between the two linear combinations: 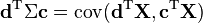 . The variance of a linear combination is then
. The variance of a linear combination is then 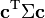 , its covariance with itself.
, its covariance with itself.
Similarly, the (pseudo-)inverse covariance matrix provides an inner product, 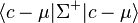 which induces the Mahalanobis distance, a measure of the "unlikelihood" of c.
which induces the Mahalanobis distance, a measure of the "unlikelihood" of c.
Which matrices are covariance matrices?
From the identity just above, let be a 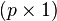 real-valued vector, then
real-valued vector, then
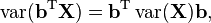
which must always be nonnegative since it is the variance of a real-valued random variable. From the symmetry of the covariance matrix's definition it follows that only a positive-semidefinite matrix can be a covariance matrix. Conversely, every symmetric positive semi-definite matrix is a covariance matrix. To see this, suppose M is a p×p positive-semidefinite matrix. From the finite-dimensional case of the spectral theorem, it follows that M has a nonnegative symmetric square root, that can be denoted by M1/2. Let be any p×1 column vector-valued random variable whose covariance matrix is the p×p identity matrix. Then
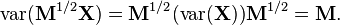
How to find a valid correlation matrix
In some applications (e.g., building data models from only partially observed data) one wants to find the "nearest" correlation matrix to a given symmetric matrix (e.g., of observed covariances). In 2002, Higham[5] formalized the notion of nearness using a weighted Frobenius norm and provided a method for computing the nearest correlation matrix.
Complex random vectors
The variance of a complex scalar-valued random variable with expected value μ is conventionally defined using complex conjugation:
![\operatorname{var}(z)
=
\operatorname{E}
\left[
(z-\mu)(z-\mu)^{*}
\right]](../I/m/aedf356d1e06c9057edbee3a8609c55c.png)
where the complex conjugate of a complex number 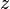 is denoted
is denoted 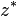 ; thus the variance of a complex number is a real number.
; thus the variance of a complex number is a real number.
If 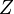 is a column-vector of complex-valued random variables, then the conjugate transpose is formed by both transposing and conjugating. In the following expression, the product of a vector with its conjugate transpose results in a square matrix, as its expectation:
is a column-vector of complex-valued random variables, then the conjugate transpose is formed by both transposing and conjugating. In the following expression, the product of a vector with its conjugate transpose results in a square matrix, as its expectation:
![\operatorname{E}
\left[
(Z-\mu)(Z-\mu)^\dagger
\right] ,](../I/m/5e185a012f91dfbc5480f0ad30fb5d8a.png)
where 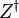 denotes the conjugate transpose, which is applicable to the scalar case since the transpose of a scalar is still a scalar. The matrix so obtained will be Hermitian positive-semidefinite,[6] with real numbers in the main diagonal and complex numbers off-diagonal.
denotes the conjugate transpose, which is applicable to the scalar case since the transpose of a scalar is still a scalar. The matrix so obtained will be Hermitian positive-semidefinite,[6] with real numbers in the main diagonal and complex numbers off-diagonal.
Estimation
If  and
and 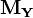 are centred data matrices of dimension n-by-p and n-by-q respectively, i.e. with n rows of observations of p and q columns of variables, from which the column means have been subtracted, then, if the column means were estimated from the data, sample correlation matrices
are centred data matrices of dimension n-by-p and n-by-q respectively, i.e. with n rows of observations of p and q columns of variables, from which the column means have been subtracted, then, if the column means were estimated from the data, sample correlation matrices 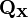 and
and 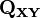 can be defined to be
can be defined to be
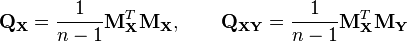
or, if the column means were known a-priori,
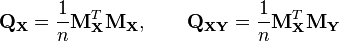
These empirical sample correlation matrices are the most straightforward and most often used estimators for the correlation matrices, but other estimators also exist, including regularised or shrinkage estimators, which may have better properties.
As a parameter of a distribution
If a vector of n possibly correlated random variables is jointly normally distributed, or more generally elliptically distributed, then its probability density function can be expressed in terms of the covariance matrix.
Applications
In financial economics
The covariance matrix plays a key role in financial economics, especially in portfolio theory and its mutual fund separation theorem and in the capital asset pricing model. The matrix of covariances among various assets' returns is used to determine, under certain assumptions, the relative amounts of different assets that investors should (in a normative analysis) or are predicted to (in a positive analysis) choose to hold in a context of diversification.
See also
- Covariance mapping
- Multivariate statistics
- Gramian matrix
- Eigenvalue decomposition
- Quadratic form (statistics)
References
- ↑ Wasserman, Larry (2004). All of Statistics: A Concise Course in Statistical Inference. ISBN 0-387-40272-1.
- ↑ William Feller (1971). An introduction to probability theory and its applications. Wiley. ISBN 978-0-471-25709-7. Retrieved 10 August 2012.
- ↑ Taboga, Marco (2010). "Lectures on probability theory and mathematical statistics".
- ↑ Eaton, Morris L. (1983). Multivariate Statistics: a Vector Space Approach. John Wiley and Sons. pp. 116–117. ISBN 0-471-02776-6.
- ↑ Higham, Nicholas J. (2002). "Computing the nearest correlation matrix—a problem from finance". IMA Journal of Numerical Analysis 22 (3): 329–343. doi:10.1093/imanum/22.3.329.
- ↑ Brookes, Mike. "The Matrix Reference Manual".
Further reading
- Hazewinkel, Michiel, ed. (2001), "Covariance matrix", Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4
- Weisstein, Eric W., "Covariance Matrix", MathWorld.
- van Kampen, N. G. (1981). Stochastic processes in physics and chemistry. New York: North-Holland. ISBN 0-444-86200-5.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||