Count–min sketch
In computing, the count–min sketch (CM sketch) is a probabilistic data structure that serves as a frequency table of events in a stream of data. It uses hash functions to map events to frequencies, but unlike a hash table uses only sub-linear space, at the expense of overcounting some events due to collisions. The count–min sketch was invented in 2003 by Graham Cormode and S. Muthu Muthukrishnan[1] and described by them in a 2005 paper.[2]
Count–min sketches are essentially the same data structure as the counting Bloom filters introduced in 1998 by Fan et al.[3] However, they are used differently and therefore sized differently: a count-min sketch typically has a sublinear number of cells, related to the desired approximation quality of the sketch, while a counting Bloom filter is more typically sized to match the number of elements in the set.
Data structure
The goal of the basic version of the count–min sketch is to consume a stream of events, one at a time, and count the frequency of the different types of events in the stream. At any time, the sketch can be queried for the frequency of a particular event type i (0 ≤ i ≤ n for some n), and will return an estimate of this frequency that is within a certain distance of the true frequency, with a certain probability.[lower-alpha 1]
The actual sketch data structure is a two-dimensional array of w columns and d rows. The parameters w and d are fixed when the sketch is created, and determine the time and space needs and the probability of error when the sketch is queried for a frequency or inner product. Associated with each of the d rows is a separate hash function; the hash functions must be pairwise independent. The parameters w and d can be chosen by setting w = ⌈e/ε⌉ and d = ⌈ln 1/δ⌉, where the error in answering a query is within a factor of ε with probability δ.
When a new event of type i arrives we update as follows: for each row j of the table, apply the corresponding hash function to obtain a column index k = hj(i). Then increment the value in row j, column k by one.
Several types of queries are possible on the stream.
- The simplest is the point query, which asks for the count of an event type i. The estimated count is given by the least value in the table for i, namely
![\hat a_i=\min_j \mathrm{count}[j, h_j(i)]](../I/m/0e3e67fd24027adfbe1429a4b6c83fef.png) , where
, where 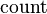 is the table.
is the table.
This estimate has the guarantee that  with probability
with probability  , where ai is the true frequency with which i occurred in the stream.
, where ai is the true frequency with which i occurred in the stream.
- An inner product query asks for the inner product between the histograms represented by two count–min sketches,
 and
and  .
.
Small modifications to the data structure can be used to sketch other different stream statistics.
Bias
One potential problem with count-min sketches is that they are biased estimators of the true frequency of events: they may overestimate, but never underestimate the true count in a point query. At least two suggested improvements to the sketch operations have been proposed to tackle this problem.[4]
The count-mean-min sketch subtracts an estimate of the bias when doing a query, but is otherwise the same structure as a count-min sketch. The estimated count is then the median (rather than the minimum) of
![\mathrm{count}[j, h_j(i)] - \frac{N - \mathrm{count}[j, h_j(i)]}{w - 1}](../I/m/961a9eb77365a0c5388ebddd7ea60644.png)
for all rows j, where N is the stream size, the number of items seen by the sketch.[5] Since this estimate is still biased upward and can be worse than the regular count–min estimate, Goyal et al. recommend taking the minimum of both estimates.[4]
Conservative updating changes the update, but not the query algorithms. To count c instances of event type i, one first computes an estimate , then updates ![\mathrm{count}[j, h_j(i)] \leftarrow \max\{\mathrm{count}[j, h_j(i)], \hat{a_i} + c\}](../I/m/fb2399001f72fc3db224fe0d9dcc63de.png) for each row j.
for each row j.
See also
Notes
- ↑ The following discussion assumes that only "positive" events occur, i.e., the frequency of the various types cannot decrease over time. Modifications of the following algorithms exist for the more general case where frequencies are allowed to decrease.
References
- ↑ Cormode, Graham (2009). "Count-min sketch" (PDF). Encyclopedia of Database Systems. Springer. pp. 511–516.
- ↑ Cormode, Graham; S. Muthukrishnan (2005). "An Improved Data Stream Summary: The Count-Min Sketch and its Applications" (PDF). J. Algorithms 55: 29–38.
- ↑ Fan, Li; Cao, Pei; Almeida, Jussara; Broder, Andrei (2000), "Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol", IEEE/ACM Transactions on Networking 8 (3): 281–293, doi:10.1109/90.851975. A preliminary version appeared at SIGCOMM '98.
- 1 2 Goyal, Amit; Daumé, Hal III; Cormode, Graham (2012). Sketch algorithms for estimating point queries in NLP. Proc. EMNLP/CoNLL.
- ↑ Deng, Fan; Rafiei, Davood (2007), New estimation algorithms for streaming data: Count-min can do more, CiteSeerX: 10
.1 .1 .552 .1283
Further reading
- Dwork, Cynthia; Naor, Moni; Pitassi, Toniann; Rothblum, Guy N.; Yekhanin, Sergey (2010). Pan-private streaming algorithms. Proc. ICS. CiteSeerX: 10
.1 ..1 .165 .5923 - Schechter, Stuart; Herley, Cormac; Mitzenmacher, Michael (2010). Popularity is everything: A new approach to protecting passwords from statistical-guessing attacks. USENIX Workshop on Hot Topics in Security. CiteSeerX: 10
.1 ..1 .170 .9356