Compound probability distribution
In probability and statistics, a compound probability distribution is the probability distribution that results from assuming that a random variable is distributed according to some parametrized distribution, with the parameters of that distribution being assumed to be themselves random variables. The compound distribution is the result of marginalizing over the intermediate random variables that represent the parameters of the initial distribution.
An important type of compound distribution occurs when the parameter being marginalized over represents the number of random variables in a summation of random variables.
Definition
A compound probability distribution is the probability distribution that results from assuming that a random variable is distributed according to some parametrized distribution 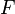 with an unknown parameter θ or parameter vector θ that is distributed according to some other distribution G with hyperparameter α, and then determining the distribution that results from marginalizing over G (i.e. integrating the unknown parameter(s) out). The resulting distribution H is said to be the distribution that results from compounding F with G.
Expressed mathematically for a scalar data point with scalar parameter and hyperparameter:
with an unknown parameter θ or parameter vector θ that is distributed according to some other distribution G with hyperparameter α, and then determining the distribution that results from marginalizing over G (i.e. integrating the unknown parameter(s) out). The resulting distribution H is said to be the distribution that results from compounding F with G.
Expressed mathematically for a scalar data point with scalar parameter and hyperparameter:
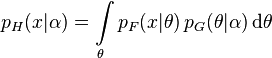
The same formula applies if some or all of the variables are vectors. Here is the case for a vector data point with vector parameters and hyperparameters:
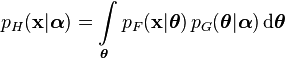
A compound distribution 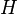 resembles in many ways the original distribution that generated it, but typically has greater variance, and often heavy tails as well. The support of is the same as the support of the , and often the shape is broadly similar as well. The parameters of include the parameters of
resembles in many ways the original distribution that generated it, but typically has greater variance, and often heavy tails as well. The support of is the same as the support of the , and often the shape is broadly similar as well. The parameters of include the parameters of  and any parameters of that are not marginalized out.
and any parameters of that are not marginalized out.
Examples
Compounding a normal distribution with variance distributed according to an inverse gamma distribution (or equivalently, with precision distributed as a gamma distribution) yields a non-standardized Student's t-distribution. This distribution has the same symmetrical shape as a normal distribution with the same central point, but has greater variance and heavy tails (in fact, specifically fat tails).
Compounding a binomial distribution with probability of success distributed according to a beta distribution yields a beta-binomial distribution. This distribution is
discrete just as the binomial distribution is, with support over integers between 0 and n (the number of trials in the base binomial distribution). There are three parameters, a parameter  (number of samples) from the binomial distribution and shape parameters
(number of samples) from the binomial distribution and shape parameters  and
and 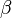 from the beta distribution. The shape is the same as a binomial distribution when and are high. (This makes sense because it indicates very high certainty that the prior probability is quite near a specific location. The limit, with all mass at a specific point, is the same as having no prior and just specifying the probability as a parameter, as in the plain, non-compounded binomial distribution.) When and are quite low, however, the shape becomes closer and closer to the shape of the beta distribution.
from the beta distribution. The shape is the same as a binomial distribution when and are high. (This makes sense because it indicates very high certainty that the prior probability is quite near a specific location. The limit, with all mass at a specific point, is the same as having no prior and just specifying the probability as a parameter, as in the plain, non-compounded binomial distribution.) When and are quite low, however, the shape becomes closer and closer to the shape of the beta distribution.
Other examples:
- Compounding a Gaussian distribution with mean distributed according to another Gaussian distribution yields a Gaussian distribution.
- Compounding a Gaussian distribution with mean distributed according to a shifted exponential distribution yields an exponentially modified Gaussian distribution
- Compounding a Gaussian distribution with variance distributed according to an exponential distribution whose rate parameter is itself distributed according to a gamma distribution yields a Normal-exponential-gamma distribution. (This involves two compounding stages.)
- Compounding a multinomial distribution with probability vector distributed according to a Dirichlet distribution yields a Dirichlet-multinomial distribution.
- Compounding a Poisson distribution with rate parameter distributed according to a gamma distribution yields a negative binomial distribution.[1]
- Compounding a Poisson distribution with a probability distributed according to a Bernoulli distribution or a 1-trial Binomial distribution yields a Zero-Inflated Poisson distribution.
- Compounding a gamma distribution with inverse scale parameter distributed according to another gamma distribution yields a three-parameter beta prime distribution.[2]
- Compounding an exponential distribution with parameter distributed according to an inverse gamma distribution yields a pareto distribution.
Application in Bayesian inference
In Bayesian inference, compound distributions arise when, in the notation above, F represents the distribution of future observations and G is the posterior distribution of the parameters of F, given the information in a set of observed data. This gives a posterior predictive distribution. Correspondingly, for the prior predictive distribution,F is the distribution of a new data point while G is the prior distribution of the parameters.
Another example is in collapsed Gibbs sampling, where "collapsing" a variable means marginalizing it out, and typically prior parameters are collapsed out.
In exponential families
Compound distributions derived from exponential family distributions often have a closed form. See the article on the posterior predictive distribution for more information.
Random number of terms in a summation
A related but slightly different concept of "compound" occurs when a random variable is constructed from a number of underling random variables, and where that number is itself a random variable. In one formulation of this, the compounding takes places over a distribution resulting from the convolution of N underlying distributions, in which N is itself treated as a random variable. The compound Poisson distribution results from considering a set of independent identically-distributed random variables distributed according to a given distribution and asking what the distribution of their sum is, if the number of variables is itself an unknown random variable 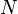 distributed according to a Poisson distribution and independent of the variables being summed. In this case the random variable N is marginalized out much like θ above is marginalized out.
distributed according to a Poisson distribution and independent of the variables being summed. In this case the random variable N is marginalized out much like θ above is marginalized out.
More general cases of this type have been considered. [3]
References
- ↑ Teich, M. C.; Diament, P. (1989). "Multiply stochastic representations for K distributions and their Poisson transforms". Journal of the Optical Society of America A: Optics, Image Science and Vision 6 (1): 80–91. doi:10.1364/JOSAA.6.000080.
- ↑ Dubey, S. D. (1970). "Compound gamma, beta and F distributions". Metrika 16: 27–31. doi:10.1007/BF02613934.
- ↑ Grubbström, Robert W.; Tang, Ou (2006). "The moments and central moments of a compound distribution". European Journal of Operational Research 170: 106–119. doi:10.1016/j.ejor.2004.06.012.