Co-citation Proximity Analysis
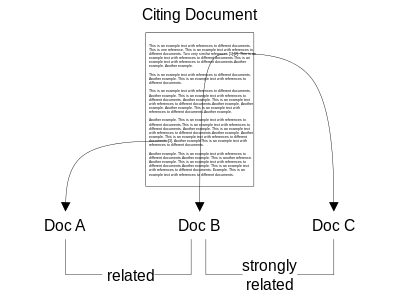
Co-citation Proximity Analysis or CPA is a document similarity measure that uses citation analysis to assess semantic similarity between documents at both the global document level as well as at individual section-level.[1][2] The similarity measure builds on the co-citation analysis approach, but differs in that it exploits the information implied in the placement of citations within the full-texts of documents.
Co-citation Proximity Analysis was conceived by Gipp in 2006 [3] and the description of the document similarity measure was later published by Gipp and Beel in 2009.[1] The similarity measure rests on the assumption that within a document’s full-text, the documents cited in close proximity to each other tend to be more strongly related than those documents cited farther apart. The figure to the right illustrates the concept. The CPA approach to document similarity assumes the documents B and C to be more strongly related than the documents B and A, because the citations to B and C occur within the same sentence, whereas the citations to B and A are separated by several paragraphs.
The advantage of the CPA approach compared to other citation and co-citation analysis approaches is an improvement in precision. Other widely used citation analysis approaches, such as Bibliographic Coupling, Co-Citation or the Amsler measure, do not take into account the location or proximity of citations within documents. The CPA approach allows a more granular automatic classification of documents and can also be used to identify not only related documents, but the specific sections within texts that are most related.
Method of Calculation
The CPA similarity measure calculates a Citation Proximity Index (CPI) for each set of documents cited by an examined document.[1] Cited documents are assigned a weight of  , where n stands for the number of levels between citations. Beginning at the lowest level, levels may be defined as citation groups, sentences, paragraphs, chapters, and finally the entire document or even journal.
, where n stands for the number of levels between citations. Beginning at the lowest level, levels may be defined as citation groups, sentences, paragraphs, chapters, and finally the entire document or even journal.
There are several variations of the CPA algorithm.
- Basic-CPA – fundamental concept of CPA as described above
- Extended-CPA – considers the tree structure and order of citations within citation groups
- Multidimensional-CPA – uses additional information such as the impact factor
- Hybrid-CPA – combines the CPI with other similarity measures, for example text-based measures. This boosts performance especially for documents with insufficient citation information.
Performance
The CPA similarity measure builds upon the co-citation document similarity approach with the distinctive addition of citation proximity analysis, therefore the CPA approach gathers a more granular picture on document relatedness. CPA has been found to outperform co-citation analysis, especially when documents contain extensive bibliographies and if documents have not been referenced frequently (i.e. have a low co-citation score).[1] Liu and Chen found that sentence-level co-citations are potentially more efficient markers for use in co-citation analysis in comparison to the loosely coupled article-level only co-citations, since sentence-level co-citations tend to preserve the essential structure of the traditional co-citation network and also form a much smaller subset of all co-citation instances [4]
See also
- CITREC, an evaluation framework for citation-based similarity measures such as Bibliographic coupling, Co-citation, Co-citation Proximity Analysis and others.[5]
References
- ↑ 1.0 1.1 1.2 1.3 Bela Gipp and Joeran Beel, 2009 "Citation Proximity Analysis (CPA) – A new approach for identifying related work based on Co-Citation Analysis" in Birger Larsen and Jacqueline Leta, editors, Proceedings of the 12th International Conference on Scientometrics and Informetrics (ISSI’09), volume 2, pages 571–575, Rio de Janeiro (Brazil), July 2009.
- ↑ Bela Gipp and Joeran Beel. "Method and system for detecting a similarity of documents". Patent Application, Oct 27, 2011. 2011/0264672 A1.
- ↑ Bela Gipp, 2006. "Doctoral Proposal: (Co-)Citation Proximity Analysis – A Measure to Identify Related Work"
- ↑ Shengbo Liu and Chaomei Chen, 2001 "The Effects of Co-citation Proximity on Co-citation Analysis", The 13th Conference of the International Society for Scientometrics and Informetrics (ISSI), July 4–7, 2011 Durban, South Africa.
- ↑ Bela Gipp, Norman Meuschke & Mario Lipinski, 2015. "CITREC: An Evaluation Framework for Citation-Based Similarity Measures based on TREC Genomics and PubMed Central" in Proceedings of the iConference 2015, Newport Beach, California, 2015.
Further reading
Bela Gipp and Joeran Beel. Identifying Related Documents For Research Paper Recommender By CPA And COA. In S. I. Ao, C. Douglas, W. S. Grundfest, and J. Burgstone, editors, Proceedings of the world congress on engineering and computer science 2009, volume 1 of Lecture Notes in Engineering and Computer Science, pages 636-639, Berkeley (USA), oct 2009. International Association of Engineers (IAENG), Newswood Limited. Available at http://sciplore.org/pub/
Bela Gipp. Measuring Document Relatedness by Citation Proximity Analysis and Citation Order Analysis. In M. Lalmas, J. Jose, A. Rauber, F. Sebastiani, and I. Frommholz, editors, Proceedings of the 14th European conference on digital libraries (ecdl’10): research and advanced technology for digital libraries, volume 6273 of Lecture Notes of Computer Science (LNCS). Springer, sep 2010. Available at http://sciplore.org/pub/