Clustering coefficient
In graph theory, a clustering coefficient is a measure of the degree to which nodes in a graph tend to cluster together. Evidence suggests that in most real-world networks, and in particular social networks, nodes tend to create tightly knit groups characterised by a relatively high density of ties; this likelihood tends to be greater than the average probability of a tie randomly established between two nodes (Holland and Leinhardt, 1971;[1] Watts and Strogatz, 1998[2]).
Two versions of this measure exist: the global and the local. The global version was designed to give an overall indication of the clustering in the network, whereas the local gives an indication of the embeddedness of single nodes.
Global clustering coefficient
The global clustering coefficient is based on triplets of nodes. A triplet consists of three nodes that are connected by either two (open triplet) or three (closed triplet) undirected ties. A triangle consists of three closed triplets, one centred on each of the nodes. The global clustering coefficient is the number of closed triplets (or 3 x triangles) over the total number of triplets (both open and closed). The first attempt to measure it was made by Luce and Perry (1949).[3] This measure gives an indication of the clustering in the whole network (global), and can be applied to both undirected and directed networks (often called transitivity, see Wasserman and Faust, 1994, page 243[4]).
The global clustering coefficient is defined as:
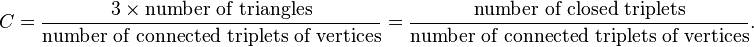
In this formula, a connected triplet is defined to be a connected subgraph consisting of three vertices and two edges. Thus, each triangle forms three connected triplets, explaining the factor of three in the formula. A generalisation to weighted networks was proposed by Opsahl and Panzarasa (2009),[5] and a redefinition to two-mode networks (both binary and weighted) by Opsahl (2009).[6]
Local clustering coefficient

The local clustering coefficient of a vertex (node) in a graph quantifies how close its neighbors are to being a clique (complete graph). Duncan J. Watts and Steven Strogatz introduced the measure in 1998 to determine whether a graph is a small-world network.
A graph  formally consists of a set of vertices
formally consists of a set of vertices 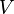 and a set of edges
and a set of edges 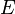 between them. An edge
between them. An edge  connects vertex
connects vertex  with vertex
with vertex  .
.
The neighbourhood  for a vertex is defined as its immediately connected neighbours as follows:
for a vertex is defined as its immediately connected neighbours as follows:
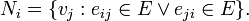
We define  as the number of vertices,
as the number of vertices, 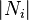 , in the neighbourhood, , of a vertex.
, in the neighbourhood, , of a vertex.
The local clustering coefficient 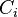 for a vertex is then given by the proportion of links between the vertices within its neighbourhood divided by the number of links that could possibly exist between them. For a directed graph, is distinct from
for a vertex is then given by the proportion of links between the vertices within its neighbourhood divided by the number of links that could possibly exist between them. For a directed graph, is distinct from 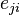 , and therefore for each neighbourhood there are
, and therefore for each neighbourhood there are 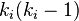 links that could exist among the vertices within the neighbourhood ( is the number of neighbors of a vertex). Thus, the local clustering coefficient for directed graphs is given as [2]
links that could exist among the vertices within the neighbourhood ( is the number of neighbors of a vertex). Thus, the local clustering coefficient for directed graphs is given as [2]
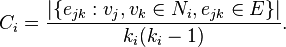
An undirected graph has the property that and are considered identical. Therefore, if a vertex has neighbours, 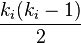 edges could exist among the vertices within the neighbourhood. Thus, the local clustering coefficient for undirected graphs can be defined as
edges could exist among the vertices within the neighbourhood. Thus, the local clustering coefficient for undirected graphs can be defined as
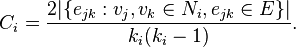
Let 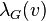 be the number of triangles on
be the number of triangles on 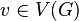 for undirected graph
for undirected graph  . That is, is the number of subgraphs of with 3 edges and 3 vertices, one of which is
. That is, is the number of subgraphs of with 3 edges and 3 vertices, one of which is 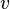 . Let
. Let 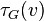 be the number of triples on
be the number of triples on 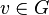 . That is, is the number of subgraphs (not necessarily induced) with 2 edges and 3 vertices, one of which is and such that is incident to both edges. Then we can also define the clustering coefficient as
. That is, is the number of subgraphs (not necessarily induced) with 2 edges and 3 vertices, one of which is and such that is incident to both edges. Then we can also define the clustering coefficient as
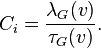
It is simple to show that the two preceding definitions are the same, since
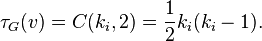
These measures are 1 if every neighbour connected to is also connected to every other vertex within the neighbourhood, and 0 if no vertex that is connected to connects to any other vertex that is connected to .
Network average clustering coefficient
As an alternative to the global clustering coefficient, the overall level of clustering in a network is measured by Watts and Strogatz[2] as the average of the local clustering coefficients of all the vertices  :[7]
:[7]
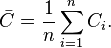
It is worth noting that this metric places more weight on the low degree nodes, while the transitivity ratio places more weight on the high degree nodes. In fact, a weighted average where each local clustering score is weighted by is identical to the global clustering coefficient.
A graph is considered small-world, if its average local clustering coefficient 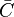 is significantly higher than a random graph constructed on the same vertex set, and if the graph has approximately the same mean-shortest path length as its corresponding random graph.
is significantly higher than a random graph constructed on the same vertex set, and if the graph has approximately the same mean-shortest path length as its corresponding random graph.
A generalisation to weighted networks was proposed by Barrat et al. (2004),[8] and a redefinition to bipartite graphs (also called two-mode networks) by Latapy et al. (2008)[9] and Opsahl (2009).[6]
This formula is not, by default, defined for graphs with isolated vertices; see Kaiser (2008)[10] and Barmpoutis et al.[11] The networks with the largest possible average clustering coefficient are found to have a modular structure, and at the same time, they have the smallest possible average distance among the different nodes.[11]
References
- ↑ P. W. Holland and S. Leinhardt (1971). "Transitivity in structural models of small groups". Comparative Group Studies 2: 107–124.
- 1 2 3 D. J. Watts and Steven Strogatz (June 1998). "Collective dynamics of 'small-world' networks". Nature 393 (6684): 440–442. Bibcode:1998Natur.393..440W. doi:10.1038/30918. PMID 9623998.
- ↑ R. D. Luce and A. D. Perry (1949). "A method of matrix analysis of group structure". Psychometrika 14 (1): 95–116. doi:10.1007/BF02289146. PMID 18152948.
- ↑ Stanley Wasserman, Kathrine Faust, 1994. Social Network Analysis: Methods and Applications. Cambridge: Cambridge University Press.
- ↑ Tore Opsahl and Pietro Panzarasa (2009). "Clustering in Weighted Networks". Social Networks 31 (2): 155–163. doi:10.1016/j.socnet.2009.02.002.
- 1 2 Tore Opsahl (2009). "Clustering in Two-mode Networks". Conference and Workshop on Two-Mode Social Analysis (Sept 30-Oct 2, 2009).
- ↑ Kemper, Andreas (2009). Valuation of Network Effects in Software Markets: A Complex Networks Approach. Springer. p. 142. ISBN 9783790823660.
- ↑ Barrat, A.; Barthelemy, M.; Pastor-Satorras, R.; Vespignani, A. (2004). "The architecture of complex weighted networks". Proceedings of the National Academy of Sciences 101 (11): 3747–3752. arXiv:cond-mat/0311416. Bibcode:2004PNAS..101.3747B. doi:10.1073/pnas.0400087101. PMC 374315. PMID 15007165.
- ↑ Latapy, M.; Magnien, C.; Del Vecchio, N. (2008). "Basic Notions for the Analysis of Large Two-mode Networks". Social Networks 30 (1): 31–48. doi:10.1016/j.socnet.2007.04.006.
- ↑ Kaiser, Marcus (2008). "Mean clustering coefficients: the role of isolated nodes and leafs on clustering measures for small-world networks". New Journal of Physics 10 (8): 083042. arXiv:0802.2512. Bibcode:2008NJPh...10h3042K. doi:10.1088/1367-2630/10/8/083042.
- 1 2 Barmpoutis, D.; Murray, R. M. (2010). "Networks with the Smallest Average Distance and the Largest Average Clustering". arXiv:1007.4031 [q-bio.MN].