Cluster labeling
In natural language processing and information retrieval, cluster labeling is the problem of picking descriptive, human-readable labels for the clusters produced by a document clustering algorithm; standard clustering algorithms do not typically produce any such labels. Cluster labeling algorithms examine the contents of the documents per cluster to find a labeling that summarize the topic of each cluster and distinguish the clusters from each other.
Differential cluster labeling
Differential cluster labeling labels a cluster by comparing term distributions across clusters, using techniques also used for feature selection in document classification, such as mutual information and chi-squared feature selection. Terms having very low frequency are not the best in representing the whole cluster and can be omitted in labeling a cluster. By omitting those rare terms and using a differential test, one can achieve the best results with differential cluster labeling.[1]
Pointwise mutual information
In the fields of probability theory and information theory, mutual information measures the degree of dependence of two random variables. The mutual information of two variables X and Y is defined as:
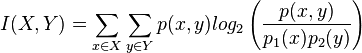
where p(x, y) is the joint probability distribution of the two variables, p1(x) is the probability distribution of X, and p2(y) is the probability distribution of Y.
In the case of cluster labeling, the variable X is associated with membership in a cluster, and the variable Y is associated with the presence of a term.[2] Both variables can have values of 0 or 1, so the equation can be rewritten as follows:
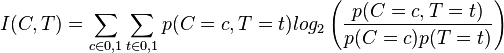
In this case, p(C = 1) represents the probability that a randomly selected document is a member of a particular cluster, and p(C = 0) represents the probability that it isn't. Similarly, p(T = 1) represents the probability that a randomly selected document contains a given term, and p(T = 0) represents the probability that it doesn't. The joint probability distribution function p(C, T) represents the probability that two events occur simultaneously. For example, p(0, 0) is the probability that a document isn't a member of cluster c and doesn't contain term t; p(0, 1) is the probability that a document isn't a member of cluster c and does contain term t; and so on.
Chi-Squared Selection
The Pearson's chi-squared test can be used to calculate the probability that the occurrence of an event matches the initial expectations. In particular, it can be used to determine whether two events, A and B, are statistically independent. The value of the chi-squared statistic is:
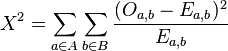
where Oa,b is the observed frequency of a and b co-occurring, and Ea,b is the expected frequency of co-occurrence.
In the case of cluster labeling, the variable A is associated with membership in a cluster, and the variable B is associated with the presence of a term. Both variables can have values of 0 or 1, so the equation can be rewritten as follows:
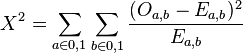
For example, O1,0 is the observed number of documents that are in a particular cluster but don't contain a certain term, and E1,0 is the expected number of documents that are in a particular cluster but don't contain a certain term. Our initial assumption is that the two events are independent, so the expected probabilities of co-occurrence can be calculated by multiplying individual probabilities:[3]
E1,0 = N * P(C = 1) * P(T = 0)
where N is the total number of documents in the collection.
Cluster-Internal Labeling
Cluster-internal labeling selects labels that only depend on the contents of the cluster of interest. No comparison is made with the other clusters. Cluster-internal labeling can use a variety of methods, such as finding terms that occur frequently in the centroid or finding the document that lies closest to the centroid.
Centroid Labels
A frequently used model in the field of information retrieval is the vector space model, which represents documents as vectors. The entries in the vector correspond to terms in the vocabulary. Binary vectors have a value of 1 if the term is present within a particular document and 0 if it is absent. Many vectors make use of weights that reflect the importance of a term in a document, and/or the importance of the term in a document collection. For a particular cluster of documents, we can calculate the centroid by finding the arithmetic mean of all the document vectors. If an entry in the centroid vector has a high value, then the corresponding term occurs frequently within the cluster. These terms can be used as a label for the cluster. One downside to using centroid labeling is that it can pick up words like "place" and "word" that have a high frequency in written text, but have little relevance to the contents of the particular cluster.
Contextualized centroid labels
A simple, cost-effective way of overcoming the above limitation is to embed the centroid terms with the highest weight in a graph structure that provides a context for their interpretation and selection. [4]
In this approach, a term-term co-occurrence matrix referred as 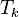 is first built for each cluster
is first built for each cluster  . Each cell represents the number of times term
. Each cell represents the number of times term  co-occurs with term
co-occurs with term 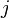 within a certain window of text (a sentence, a paragraph, etc.)
In a second stage, a similarity matrix
within a certain window of text (a sentence, a paragraph, etc.)
In a second stage, a similarity matrix 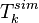 is obtained by multiplying with its transpose. We have
is obtained by multiplying with its transpose. We have 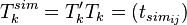 . Being the dot product of two normalized vectors
. Being the dot product of two normalized vectors 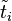 and
and 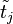 ,
, 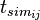 denotes the cosine similarity between terms and . The so obtained can then be used as the weighted adjacency matrix of a term similarity graph. The centroid terms are part of this graph, and they thus can be interpreted and scored by inspecting the terms that surround them in the graph.
denotes the cosine similarity between terms and . The so obtained can then be used as the weighted adjacency matrix of a term similarity graph. The centroid terms are part of this graph, and they thus can be interpreted and scored by inspecting the terms that surround them in the graph.
Title labels
An alternative to centroid labeling is title labeling. Here, we find the document within the cluster that has the smallest Euclidean distance to the centroid, and use its title as a label for the cluster. One advantage to using document titles is that they provide additional information that would not be present in a list of terms. However, they also have the potential to mislead the user, since one document might not be representative of the entire cluster.
External knowledge labels
Cluster labeling can be done indirectly using external knowledge such as pre-categorized knowledge such as the one of Wikipedia.[5] In such methods, a set of important cluster text features are first extracted from the cluster documents. These features then can be used to retrieve the (weighted) K-nearest categorized documents from which candidates for cluster labels can be extracted. The final step involves the ranking of such candidates. Suitable methods are such that are based on a voting or a fusion process which is determined using the set of categorized documents and the original cluster features.
External links
References
- ↑ Manning, Christopher D., Prabhakar Raghavan, and Hinrich Schutze. Introduction to Information Retrieval. Cambridge: Cambridge UP, 2008. Cluster Labeling. Stanford Natural Language Processing Group. Web. 25 Nov. 2009. <http://nlp.stanford.edu/IR-book/html/htmledition/cluster-labeling-1.html>.
- ↑ Manning, Christopher D., Prabhakar Raghavan, and Hinrich Schutze. Introduction to Information Retrieval. Cambridge: Cambridge UP, 2008. Mutual Information. Stanford Natural Language Processing Group. Web. 25 Nov. 2009. <http://nlp.stanford.edu/IR-book/html/htmledition/mutual-information-1.html>.
- ↑ Manning, Christopher D., Prabhakar Raghavan, and Hinrich Schutze. Introduction to Information Retrieval. Cambridge: Cambridge UP, 2008. Chi2 Feature Selection. Stanford Natural Language Processing Group. Web. 25 Nov. 2009. <http://nlp.stanford.edu/IR-book/html/htmledition/feature-selectionchi2-feature-selection-1.html>.
- ↑ Francois Role, Moahmed Nadif. Beyond cluster labeling: Semantic interpretation of clusters’ contents using a graph representation. Knowledge-Based Systems, Volume 56, January, 2014: 141-155
- ↑ David Carmel, Haggai Roitman, Naama Zwerdling. Enhancing cluster labeling using wikipedia. SIGIR 2009: 139-146