Classification Tree Method
The Classification Tree Method is a method for test design,[1] as it is used in different areas of software development.[2] It got developed by Grimm and Grochtmann in 1993.[3] Classification Trees in terms of the Classification Tree Method must not be confused with decision trees.
The classification tree method consists of two major steps:[4][5]
- Identification of test relevant aspects (so called classifications) and their corresponding values (called classes) as well as
- Combination of different classes from all classifications into test cases.
The identification of test relevant aspects usually follows the (functional) specification (e.g. requirements, use cases …) of the system under test. These aspects form the input and output data space of the test object.
The second step of test design then follows the principles of combinatorial test design.[4]
While the method can be applied using a pen and a paper, the usual way involves the usage of the Classification Tree Editor, a software tool implementing the classification tree method.[6]
Application
Prerequisites for applying the classification tree method (CTM) is the selection (or definition) of a system under test. The CTM is a black-box testing method and supports any type of system under test. This includes (but is not limited to) hardware systems, integrated hardware-software systems, plain software systems, including embedded software, user interfaces, operating systems, parsers, and others (or subsystems of mentioned systems).
With a selected system under test, the first step of the classification tree method is the identification of test relevant aspects.[4] Any system under test can be described by a set of classifications, holding both input and output parameters. (Input parameters can also include environments states, pre-conditions and other, rather uncommon parameters).[2] Each classification can have any number of disjoint classes, describing the occurrence of the parameter. The selection of classes typically follows the principle of equivalence partitioning for abstract test cases and boundary-value analysis for concrete test cases.[5] Together, all classifications form the classification tree. For semantic purpose, classifications can be grouped into compositions.
The maximum number of test cases is the Cartesian product of all classes of all classifications in the tree, quickly resulting in large numbers for realistic test problems. The minimum number of test cases is the number of classes in the classification with the most containing classes.
In the second step, test cases are composed by selecting exactly one class from every classification of the classification tree. The selection of test cases originally[3] was a manual task to be performed by the test engineer.
Example
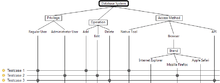
For a database system, test design has to be performed. Applying the classification tree method, the identification of test relevant aspects gives the classifications: User Privilege, Operation and Access Method. For the User Privileges, two classes can be identified: Regular User and Administrator User. There are three Operations: Add, Edit and Delete. For the Access Method, again three classes are identified: Native Tool, Web Browser, API. The Web Browser class is further refined with the test aspect Brand, three possible classes are included here: Internet Explorer, Mozilla Firefox, and Apple Safari.
The first step of the classification tree method now is complete. Of course, there are further possible test aspects to include, e.g. access speed of the connection, number of database records present in the database, etc. Using the graphical representation in terms of a tree, the selected aspects and their corresponding values can quickly be reviewed.
For the statistics, there are 30 possible test cases in total (2 privileges * 3 operations * 5 access methods). For minimum coverage, 5 test cases are sufficient, as there are 5 access methods (and access method is the classification with the highest number of disjoint classes).
In the second step, three test cases have been manually selected:
- A regular user adds a new data set to the database using the native tool.
- An administrator user edits an existing data set using the Firefox browser.
- A regular user deletes a data set from the database using the API.
Enhancements
Background
The CTM introduced the following advantages[2] over the Category Partition Method[7] (CPM) by Olstrad and Balcer:
- Notation: CPM only had a textual notation, whereas CTM uses a graphical, tree-shaped representation.
- Refinements Selecting one representative might have an influence on the occurrence of other representatives.
- CPM only offers restrictions to handle this scenario.
- CTM allows modeling of hierarchical refinements in the classification tree, also called implicit dependencies.
- Tool support: The tool presented by Ostrand and Balcer only supported test case generation, but not the partitioning itself.
- Grochtmann and Wegener presented their tool, the Classification Tree Editor (CTE) which supports both partitioning as well as test case generation.[6]

Classification Tree Method for Embedded Systems
The classification tree method first was intended for the design and specification of abstract test cases. With the classification tree method for embedded systems,[8] test implementation can also be performed. Several additional features are integrated with the method:
- In addition to atomic test cases, test sequences containing several test steps can be specified.
- A concrete timing (e.g. in Seconds, Minutes ...) can be specified for each test step.
- Signal transitions (e.g. linear, spline, sine ...) between selected classes of different test steps can be specified.
- A distinction between event and state can be modelled, represented by different visual marks in a test.
The module and unit testing tool Tessy relies on this extension.
Dependency Rules and Automated Test Case Generation
One way of modelling constraints is using the refinement mechanism in the classification tree method. This, however, does not allow for modelling constraints between classes of different classifications. Lehmann and Wegener introduced Dependency Rules based on Boolean expressions with their incarnation of the CTE.[9] Further features include the automated generation of test suites using combinatorial test design (e.g. all-pairs testing).
Prioritized Test Case Generation
Recent enhancements to the classification tree method include the prioritized test case generation: It is possible to assign weights to the elements of the classification tree in terms of occurrence and error probability or risk. These weights are then used during test case generation to prioritize test cases.[10][11] Statistical testing is also available (e.g. for wear and fatigue tests) by interpreting the element weights as a discrete probability distribution.
Test Sequence Generation
With the addition of valid transitions between individual classes of a classification, classifications can be interpreted as a state machine, and therefore the whole classification tree as a Statechart. This defines an allowed order of class usages in test steps and allows to automatically create test sequences.[12] Different coverage levels are available, such as state coverage, transitions coverage and coverage of state pairs and transition pairs.
Numerical Constraints
In addition to Boolean dependency rules referring to classes of the classification tree, Numerical Constraints allow to specify formulas with classifications as variables, which will evaluate to the selected class in a test case.[13]
Classification Tree Editor
The Classification Tree Editor (CTE) is a software tool for test design that implements the classification tree method.[14][15][16][17]
Over the time, several editions of the CTE tool have appeared, written in several (by that time popular) programming languages and developed by several companies.
CTE 1
The original version of CTE was developed at Daimler-Benz Industrial Research[6][16] facilities in Berlin. It appeared in 1993 and was written in Pascal. It was only available on Unix systems.
CTE 2
In 1997 a major re-implementation was performed, leading to CTE 2. Development again was at Daimler-Benz Industrial Research. It was written in C and available for win32 systems.
CTE 2 was later licensed to Razorcat for inclusion with the module and unit testing tool Tessy. The classification tree editor for embedded systems[8][15] also based upon this edition.
CTE XL
In 2000, Lehmann and Wegener introduced Dependency Rules with their incarnation of the CTE, the CTE XL (eXtended Logics).[9][14][17][18] Further features include the automated generation of test suites using combinatorial test design (e.g. all-pairs testing).[19]
Development was performed by DaimlerChrysler. CTE XL was written in Java and was supported on win32 systems. CTE XL was available for download free of charge.
In 2008, Berner&Mattner acquired all rights on CTE XL and continued development till CTE XL 1.9.4.
CTE XL Professional
Starting in 2010, CTE XL Professional was developed by Berner&Mattner.[10] A complete re-implementation was done, again using Java but this time Eclipse-based. CTE XL Professional was available on win32 and win64 systems.
New developments included:
- Prioritized test case generation: It is possible to assign weights to the elements of the classification tree in terms of occurrence and error probability or risk. These weights are then used during test case generation to prioritize test cases.[10][20] Risk-based and statistical testing is also available.
- Test Sequence Generation[12] using Multi-Agent Systems
- Numerical Constraints[13]
TESTONA
In 2014, Berner&Mattner started releasing its classification tree editor under the brand name TESTONA.
A free edition of TESTONA is still available for download free of charge, however, with reduced functionality.
Versions
| Version | Date | Comment | Written in | OS |
|---|---|---|---|---|
| CTE 1.0 | 1993 | Original Version,[6][16] limited to 1000 test cases (fix!) | Pascal | Unix |
| CTE 2.0 | 1998 | Windows Version,[15] unlimited number of test cases | C | Unix, win32 |
| CTE XL 1.0 | 2000 | Dependency Rules, Test Case Generation[9][14][17] | Java | win32 |
| CTE XL 1.6 | 2006 | Last Version by Daimler-Benz[18] | Java | win32 |
| CTE XL 1.8 | 2008 | Development by Berner&Mattner | Java | win32 |
| CTE XL 1.9 | 2009 | Last Java-only Version | Java | win32 |
| CTE XL Professional 2.1 | 2011-02-21 | First Eclipse-based Version, Prioritized Test Case Generation,[10] Deterministic Test Case Generation, Requirements-Tracing with DOORS | Java, Eclipse | win32 |
| CTE XL Professional 2.3 | 2011-08-02 | QualityCenter integration, Requirements Coverage Analysis and Traceability Matrix, API | Java | win32 |
| CTE XL Professional 2.5 | 2011-11-11 | Test Result Anotation, MindMap import | Java | win32, win64 |
| CTE XL Professional 2.7 | 2012-01-30 | Bug fix release | Java | win32, win64 |
| CTE XL Professional 2.9 | 2012-06-08 | Implicit Mark Mode, Default classes, Command Line Interface | Java | win32, win64 |
| CTE XL Professional 3.1 | 2012-10-19 | Test Post-Evaluation (e.g. for Root Cause Analysis), Test Sequence Generation,[12] Numerical Constraints[13] | Java | win32, win64 |
| CTE XL Professional 3.3 | 2013-05-28 | Test Coverage Analysis, Variant Management (e.g. as part of Product Family Engineering), Equivalence Class Testing | Java, Eclipse 3.7 | win32, win64 |
| CTE XL Professional 3.5 | 2013-12-18 | Bounday Value Analysis Wizard, Import of AUTOSAR and MATLAB models | Java 7, Eclipse 3.8 | win32, win64 |
| TESTONA 4.1 | 2014-09-22 | Bug fix release | Java 7, Eclipse 3.8 | win32, win64 |
Advantages
- Graphical representation of test relevant aspects[2]
- Method for both identification of relevant test aspects and their combination into test cases[4]
Limitations
- When test design with the classification tree method is performed without proper test decomposition, classification trees can get large and cumbersome.
- New users tend to include too many (esp. irrelevant) test aspects resulting in too many test cases.
- There is no algorithm or strict guidance for selection of test relevant aspects.[21]
References
- ↑ Bath, Graham; McKay, Judy (2008). The software test engineer's handbook : a study guide for the ISTQB test analyst and technical test analyst advanced level certificates (1st ed.). Santa Barbara, CA: Rocky Nook. ISBN 9781933952246.
- 1 2 3 4 Hass, Anne Mette Jonassen (2008). Guide to advanced software testing. Boston: Artech House. pp. 179–186. ISBN 1596932864.
- 1 2 Grochtmann, Matthias; Grimm, Klaus (1993). "Classification Trees for Partition Testing". Software Testing, Verification & Reliability 3 (2): 63–82. doi:10.1002/stvr.4370030203.
- 1 2 3 4 Kuhn, D. Richard; Kacker, Raghu N.; Lei, Yu (2013). Introduction to combinatorial testing. Crc Pr Inc. pp. 76–81. ISBN 1466552298.
- 1 2 Henry, Pierre (2008). The testing network an integral approach to test activities in large software projects. Berlin: Springer. p. 87. ISBN 978-3-540-78504-0.
- 1 2 3 4 Grochtmann, Matthias; Wegener, Joachim (1995). "Test Case Design Using Classification Trees and the Classification-Tree Editor CTE" (PDF). Proceedings of the 8th International Software Quality Week(QW '95), San Francisco, USA.
- ↑ Ostrand, T. J.; Balcer, M. J. (1988). "The category-partition method for specifying and generating functional tests". Communications of the ACM 31 (6): 676–686. doi:10.1145/62959.62964.
- 1 2 Conrad, Mirko; Krupp, Alexander (1 October 2006). "An Extension of the Classification-Tree Method for Embedded Systems for the Description of Events". Electronic Notes in Theoretical Computer Science 164 (4): 3–11. doi:10.1016/j.entcs.2006.09.002.
- 1 2 3 Lehmann, Eckard; Wegener, Joachim (2000). "Test Case Design by Means of the CTE XL" (PDF). Proceedings of the 8th European International Conference on Software Testing, Analysis & Review (EuroSTAR 2000).
- 1 2 3 4 Kruse, Peter M.; Luniak, Magdalena (December 2010). "Automated Test Case Generation Using Classification Trees". Software Quality Professional 13 (1): 4–12.
- ↑ Franke M, Gerke D, Hans C. und andere. Method-Driven Test Case Generation for Functional System Verification. Proceedings ATOS. Delft. 2012. P.36-44.
- 1 2 3 Kruse, Peter M.; Wegener, Joachim (April 2012). "Test Sequence Generation from Classification Trees". Software Testing, Verification and Validation (ICST), 2012 IEEE Fifth International Conference on: 539–548. doi:10.1109/ICST.2012.139. ISBN 978-0-7695-4670-4.
- 1 2 3 Kruse, Peter M.; Bauer, Jürgen; Wegener, Joachim (April 2012). "Numerical Constraints for Combinatorial Interaction Testing". Software Testing, Verification and Validation (ICST), 2012 IEEE Fifth International Conference on: 758–763. doi:10.1109/ICST.2012.170. ISBN 978-0-7695-4670-4.
- 1 2 3 International, SAE (2004). Vehicle electronics to digital mobility : the next generation of convergence ; proceedings of the 2004 International Congress on Transportation Electronics, Convergence 2004, [Cobo Center, Detroit, Michigan, USA, October 18 - 20, 2004]. Warrendale, Pa.: Society of Automotive Engineers. pp. 305–306. ISBN 076801543X.
- 1 2 3 [edited by] Gomes, Luís; Fernandes, João M. (2010). Behavioral modeling for embedded systems and technologies applications for design and implementation. Hershey, PA: Information Science Reference. p. 386. ISBN 160566751X.
- 1 2 3 [edited by] Zander, Justyna; Schieferdecker, Ina; Mosterman, Pieter J. Model-based testing for embedded systems. Boca Raton: CRC Press. p. 10. ISBN 1439818452.
- 1 2 3 [edited by] Rech, Jörg; Bunse, Christian (2009). Model-driven software development integrating quality assurance. Hershey: Information Science Reference. p. 101. ISBN 1605660078.
- 1 2 Olejniczak, Robert (2008). Systematisierung des funktionalen Tests eingebetteter Software (PDF). Doctoral dissertation: Technical University Munich. pp. 61–63. Retrieved 10 October 2013.
- ↑ Cain, Andrew; Chen, Tsong Yueh; Grant, Doug; Poon, Pak-Lok; Tang, Sau-Fun; Tse, TH (2004). "An Automatic Test Data Generation System Based on the Integrated Classification-Tree Methodology" (PDF). First International Conference, SERA 2003, San Francisco, CA, USA, June 25–27, 2003, Selected Revised Papers: 225–238. doi:10.1007/978-3-540-24675-6_18. Retrieved 10 October 2013.
- ↑ Franke, M.; Gerke, D.; Hans, C; and others: Method-Driven Test Case Genera-tion for Functional System Verification, Air Transport and Operations Sym-posium 2012; p.354-365. Proceedings ATOS. Delft 2012.
- ↑ Chen, T.Y.; Poon, P.-L. (1996). "Classification-Hierarchy Table: a methodology for constructing the classification tree". Australian Software Engineering Conference, 1996., Proceedings of 1996: 93–104. doi:10.1109/ASWEC.1996.534127. ISBN 0-8186-7635-3.