Chord (peer-to-peer)
In computing, Chord is a protocol and algorithm for a peer-to-peer distributed hash table. A distributed hash table stores key-value pairs by assigning keys to different computers (known as "nodes"); a node will store the values for all the keys for which it is responsible. Chord specifies how keys are assigned to nodes, and how a node can discover the value for a given key by first locating the node responsible for that key.
Chord is one of the four original distributed hash table protocols, along with CAN, Tapestry, and Pastry. It was introduced in 2001 by Ion Stoica, Robert Morris, David Karger, Frans Kaashoek, and Hari Balakrishnan, and was developed at MIT.[1]
Overview

Nodes and keys are assigned an  -bit identifier using consistent hashing. The SHA-1 algorithm is the base hashing function for consistent hashing. Consistent hashing is integral to the robustness and performance of Chord because both keys and nodes (in fact, their IP addresses) are uniformly distributed in the same identifier space with a negligible possibility of collision. Thus, it also allows nodes to join and leave the network without disruption. In the protocol, the term node is used to refer to both a node itself and its identifier (ID) without ambiguity. So is the term key.
-bit identifier using consistent hashing. The SHA-1 algorithm is the base hashing function for consistent hashing. Consistent hashing is integral to the robustness and performance of Chord because both keys and nodes (in fact, their IP addresses) are uniformly distributed in the same identifier space with a negligible possibility of collision. Thus, it also allows nodes to join and leave the network without disruption. In the protocol, the term node is used to refer to both a node itself and its identifier (ID) without ambiguity. So is the term key.
Using the Chord lookup protocol, nodes and keys are arranged in an identifier circle that has at most  nodes, ranging from
nodes, ranging from  to
to  . ( should be large enough to avoid collision.)
. ( should be large enough to avoid collision.)
Each node has a successor and a predecessor. The successor to a node is the next node in the identifier circle in a clockwise direction. The predecessor is counter-clockwise. If there is a node for each possible ID, the successor of node 0 is node 1, and the predecessor of node 0 is node ; however, normally there are "holes" in the sequence. For example, the successor of node 153 may be node 167 (and nodes from 154 to 166 do not exist); in this case, the predecessor of node 167 will be node 153.
The concept of successor can be used for keys as well. The successor node of a key  is the first node whose ID equals to or follows in the identifier circle, denoted by
is the first node whose ID equals to or follows in the identifier circle, denoted by  . Every key is assigned to (stored at) its successor node, so looking up a key is to query .
. Every key is assigned to (stored at) its successor node, so looking up a key is to query .
Since the successor (or predecessor) of a node may disappear from the network (because of failure or departure), each node records a whole segment of the circle adjacent to it, i.e., the  nodes preceding it and the nodes following it. This list results in a high probability that a node is able to correctly locate its successor or predecessor, even if the network in question suffers from a high failure rate.
nodes preceding it and the nodes following it. This list results in a high probability that a node is able to correctly locate its successor or predecessor, even if the network in question suffers from a high failure rate.
Protocol details

Basic query
The core usage of the Chord protocol is to query a key from a client (generally a node as well), i.e. to find . The basic approach is to pass the query to a node's successor, if it cannot find the key locally. This will lead to a  query time.
query time.
Finger table
To avoid the linear search above, Chord implements a faster search method by requiring each node to keep a finger table containing up to entries. The  entry of node
entry of node  will contain
will contain 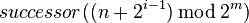 . The first entry of finger table is actually the node's immediate successor (and therefore an extra successor field is not needed). Every time a node wants to look up a key , it will pass the query to the closest successor or predecessor (depending on the finger table) of in its finger table (the "largest" one on the circle whose ID is smaller than ), until a node finds out the key is stored in its immediate successor.
. The first entry of finger table is actually the node's immediate successor (and therefore an extra successor field is not needed). Every time a node wants to look up a key , it will pass the query to the closest successor or predecessor (depending on the finger table) of in its finger table (the "largest" one on the circle whose ID is smaller than ), until a node finds out the key is stored in its immediate successor.
With such a finger table, the number of nodes that must be contacted to find a successor in an N-node network is  . (See proof below.)
. (See proof below.)
Node join
Whenever a new node joins, three invariants should be maintained (the first two ensure correctness and the last one keeps querying fast):
- Each node's successor points to its immediate successor correctly.
- Each key is stored in .
- Each node's finger table should be correct.
To satisfy these invariants, a predecessor field is maintained for each node. As the successor is the first entry of the finger table, we do not need to maintain this field any more. The following tasks should be done for a newly joined node :
- Initialize node (the predecessor and the finger table).
- Notify other nodes to update their predecessors and finger tables.
- The new node takes over its responsible keys from its successor.
The predecessor of can be easily obtained from the predecessor of  (in the previous circle). As for its finger table, there are various initialization methods. The simplest one is to execute find successor queries for all entries, resulting in
(in the previous circle). As for its finger table, there are various initialization methods. The simplest one is to execute find successor queries for all entries, resulting in  initialization time. A better method is to check whether entry in the finger table is still correct for the
initialization time. A better method is to check whether entry in the finger table is still correct for the  entry. This will lead to
entry. This will lead to  . The best method is to initialize the finger table from its immediate neighbours and make some updates, which is .
. The best method is to initialize the finger table from its immediate neighbours and make some updates, which is .
Stabilization
To ensure correct lookups, all successor pointers must be up to date. => stabilization protocol running periodically in the background. Updates finger tables and successor pointers. Stabilization protocol: Stabilize(): n asks its successor for its predecessor p and decides whether p should be n‘s successor instead (this is the case if p recently joined the system). Notify(): notifies n‘s successor of its existence, so it can change its predecessor to n Fix_fingers(): updates finger tables
Potential uses
- Cooperative Mirroring: A load balancing mechanism by a local network hosting information available to computers outside of the local network. This scheme could allow developers to balance the load between many computers instead of a central server to ensure availability of their product.
- Time-shared storage: In a network, once a computer joins the network its available data is distributed throughout the network for retrieval when that computer disconnects from the network. As well as other computers' data is sent to the computer in question for offline retrieval when they are no longer connected to the network. Mainly for nodes without the ability to connect full-time to the network.
- Distributed Indices: Retrieval of files over the network within a searchable database. e.g. P2P file transfer clients.
- Large scale combinatorial searches: Keys being candidate solutions to a problem and each key mapping to the node, or computer, that is responsible for evaluating them as a solution or not. e.g. Code Breaking
Proof sketches

With high probability, Chord contacts nodes to find a successor in an 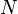 -node network.
-node network.
Suppose node wishes to find the successor of key . Let 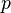 be the predecessor of . We wish to find an upper bound for the number of steps it takes for a message to be routed from to . Node will examine its finger table and route the request to the closest predecessor of that it has. Call this node
be the predecessor of . We wish to find an upper bound for the number of steps it takes for a message to be routed from to . Node will examine its finger table and route the request to the closest predecessor of that it has. Call this node 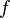 . If is the entry 's finger table, then both and are at distances between
. If is the entry 's finger table, then both and are at distances between  and
and  from along the identifier circle. Hence, the distance between and along this circle is at most . Thus the distance from to is less than the distance from to : the new distance to is at most half the initial distance.
from along the identifier circle. Hence, the distance between and along this circle is at most . Thus the distance from to is less than the distance from to : the new distance to is at most half the initial distance.
This process of halving the remaining distance repeats itself, so after  steps, the distance remaining to is at most
steps, the distance remaining to is at most  ; in particular, after
; in particular, after  steps, the remaining distance is at most
steps, the remaining distance is at most  . Because nodes are distributed uniformly at random along the identifier circle, the expected number of nodes falling within an interval of this length is 1, and with high probability, there are fewer than such nodes. Because the message always advances by at least one node, it takes at most steps for a message to traverse this remaining distance. The total expected routing time is thus .
. Because nodes are distributed uniformly at random along the identifier circle, the expected number of nodes falling within an interval of this length is 1, and with high probability, there are fewer than such nodes. Because the message always advances by at least one node, it takes at most steps for a message to traverse this remaining distance. The total expected routing time is thus .
If Chord keeps track of  predecessors/successors, then with high probability, if each node has probability of 1/4 of failing, find_successor (see below) and find_predecessor (see below) will return the correct nodes
predecessors/successors, then with high probability, if each node has probability of 1/4 of failing, find_successor (see below) and find_predecessor (see below) will return the correct nodes
Simply, the probability that all nodes fail is  , which is a low probability; so with high probability at least one of them is alive and the node will have the correct pointer.
, which is a low probability; so with high probability at least one of them is alive and the node will have the correct pointer.
Pseudocode
- Definitions for pseudocode
- finger[k]
- first node that succeeds

- successor
- the next node from the node in question on the identifier ring
- predecessor
- the previous node from the node in question on the identifier ring
The pseudocode to find the successor node of an id is given below:
// ask node n to find the successor of id
n.find_successor(id)
//Yes, that should be a closing square bracket to match the opening parenthesis.
//It is a half closed interval.
if (id ∈ (n, successor] )
return successor;
else
// forward the query around the circle
n0 = closest_preceding_node(id);
return n0.find_successor(id);
// search the local table for the highest predecessor of id
n.closest_preceding_node(id)
for i = m downto 1
if (finger[i]∈(n,id))
return finger[i];
return n;
The pseudocode to stabilize the chord ring/circle after node joins and departures is as follows:
// create a new Chord ring. n.create() predecessor = nil; successor = n;
// join a Chord ring containing node n'. n.join(n') predecessor = nil; successor = n'.find_successor(n);
// called periodically. n asks the successor
// about its predecessor, verifies if n's immediate
// successor is consistent, and tells the successor about n
n.stabilize()
x = successor.predecessor;
if (x∈(n, successor))
successor = x;
successor.notify(n);
// n' thinks it might be our predecessor.
n.notify(n')
if (predecessor is nil or n'∈(predecessor, n))
predecessor = n';
// called periodically. refreshes finger table entries.
// next stores the index of the finger to fix
n.fix_fingers()
next = next + 1;
if (next > m)
next = 1;
finger[next] = find_successor(n+ );
);
// called periodically. checks whether predecessor has failed.
n.check_predecessor()
if (predecessor has failed)
predecessor = nil;
See also
- Kademlia
- Koorde
- OverSim - the overlay simulation framework
- SimGrid - a toolkit for the simulation of distributed applications -
References
- ↑ Stoica, I.; Morris, R.; Karger, D.; Kaashoek, M. F.; Balakrishnan, H. (2001). "Chord: A scalable peer-to-peer lookup service for internet applications" (PDF). ACM SIGCOMM Computer Communication Review 31 (4): 149. doi:10.1145/964723.383071.
Stoica, I.; Morris, R.; Liben-Nowell, D.; Karger, D.; Kaashoek, M. F.; Dabek, F.; and Balakrishnan, H.. "Chord: A scalable peer-to-peer lookup service for internet applications" IEEE Transactions on Networking 11, February 2003. http://pdos.csail.mit.edu/papers/ton:chord/paper-ton.pdf
External links
- The Chord Project
- Open Chord - An Open Source Java Implementation
- Chordless - Another Open Source Java Implementation
- jDHTUQ- An open source java implementation. API to generalize the implementation of peer-to-peer DHT systems. Contains GUI in mode data structure