Pearson's chi-squared test
Pearson's chi-squared test (χ2) is a statistical test applied to sets of categorical data to evaluate how likely it is that any observed difference between the sets arose by chance. It is suitable for unpaired data from large samples.[1] It is the most widely used of many chi-squared tests (e.g., Yates, likelihood ratio, portmanteau test in time series, etc.) – statistical procedures whose results are evaluated by reference to the chi-squared distribution. Its properties were first investigated by Karl Pearson in 1900.[2] In contexts where it is important to improve a distinction between the test statistic and its distribution, names similar to Pearson χ-squared test or statistic are used.
It tests a null hypothesis stating that the frequency distribution of certain events observed in a sample is consistent with a particular theoretical distribution. The events considered must be mutually exclusive and have total probability 1. A common case for this is where the events each cover an outcome of a categorical variable. A simple example is the hypothesis that an ordinary six-sided die is "fair" (i. e., all six outcomes are equally likely to occur).
Definition
Pearson's chi-squared test is used to assess two types of comparison: tests of goodness of fit and tests of independence.
- A test of goodness of fit establishes whether or not an observed frequency distribution differs from a theoretical distribution.
- A test of independence assesses whether unpaired observations on two variables, expressed in a contingency table, are independent of each other (e.g. polling responses from people of different nationalities to see if one's nationality is related to the response).
The procedure of the test includes the following steps:
- Calculate the chi-squared test statistic,
 , which resembles a normalized sum of squared deviations between observed and theoretical frequencies (see below).
, which resembles a normalized sum of squared deviations between observed and theoretical frequencies (see below). - Determine the degrees of freedom, df, of that statistic, which is essentially the number of categories reduced by the number of parameters of the fitted distribution.
- Select a desired level of confidence (significance level, p-value or alpha level) for the result of the test.
- Compare to the critical value from the chi-squared distribution with df degrees of freedom and the selected confidence level (one-sided since the test is only one direction, i.e. is the test value greater than the critical value?), which in many cases gives a good approximation of the distribution of .
- Accept or reject the null hypothesis that the observed frequency distribution is different from the theoretical distribution based on whether the test statistic exceeds the critical value of . If the test statistic exceeds the critical value of , the null hypothesis (
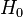 = there is no difference between the distributions) can be rejected with the selected level of confidence and the alternative hypothesis (
= there is no difference between the distributions) can be rejected with the selected level of confidence and the alternative hypothesis (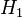 = there is a difference between the distributions) can be accepted with the selected level of confidence.
= there is a difference between the distributions) can be accepted with the selected level of confidence.
Test for fit of a distribution
Discrete uniform distribution
In this case 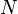 observations are divided among
observations are divided among  cells. A simple application is to test the hypothesis that, in the general population, values would occur in each cell with equal frequency. The "theoretical frequency" for any cell (under the null hypothesis of a discrete uniform distribution) is thus calculated as
cells. A simple application is to test the hypothesis that, in the general population, values would occur in each cell with equal frequency. The "theoretical frequency" for any cell (under the null hypothesis of a discrete uniform distribution) is thus calculated as
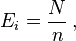
and the reduction in the degrees of freedom is  , notionally because the observed frequencies
, notionally because the observed frequencies 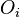 are constrained to sum to .
are constrained to sum to .
Other distributions
When testing whether observations are random variables whose distribution belongs to a given family of distributions, the "theoretical frequencies" are calculated using a distribution from that family fitted in some standard way. The reduction in the degrees of freedom is calculated as 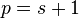 , where
, where  is the number of co-variates used in fitting the distribution. For instance, when checking a three-co-variate Weibull distribution,
is the number of co-variates used in fitting the distribution. For instance, when checking a three-co-variate Weibull distribution, 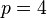 , and when checking a normal distribution (where the parameters are mean and standard deviation),
, and when checking a normal distribution (where the parameters are mean and standard deviation), 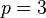 . Thus, there will be
. Thus, there will be 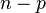 degrees of freedom, where is the number of categories.
degrees of freedom, where is the number of categories.
It should be noted that the degrees of freedom are not based on the number of observations as with a Student's t or F-distribution. For example, if testing for a fair, six-sided die, there would be five degrees of freedom because there are six categories/parameters (each number). The number of times the die is rolled does not influence the number of degrees of freedom.
Calculating the test-statistic

| Upper-tail critical values of chi-square distribution [3] | |||||
|---|---|---|---|---|---|
| Degrees of freedom |
Probability less than the critical value | ||||
| 0.90 | 0.95 | 0.975 | 0.99 | 0.999 | |
| 1 | 2.706 | 3.841 | 5.024 | 6.635 | 10.828 |
| 2 | 4.605 | 5.991 | 7.378 | 9.210 | 13.816 |
| 3 | 6.251 | 7.815 | 9.348 | 11.345 | 16.266 |
| 4 | 7.779 | 9.488 | 11.143 | 13.277 | 18.467 |
| 5 | 9.236 | 11.070 | 12.833 | 15.086 | 20.515 |
| 6 | 10.645 | 12.592 | 14.449 | 16.812 | 22.458 |
| 7 | 12.017 | 14.067 | 16.013 | 18.475 | 24.322 |
| 8 | 13.362 | 15.507 | 17.535 | 20.090 | 26.125 |
| 9 | 14.684 | 16.919 | 19.023 | 21.666 | 27.877 |
| 10 | 15.987 | 18.307 | 20.483 | 23.209 | 29.588 |
| 11 | 17.275 | 19.675 | 21.920 | 24.725 | 31.264 |
| 12 | 18.549 | 21.026 | 23.337 | 26.217 | 32.910 |
| 13 | 19.812 | 22.362 | 24.736 | 27.688 | 34.528 |
| 14 | 21.064 | 23.685 | 26.119 | 29.141 | 36.123 |
| 15 | 22.307 | 24.996 | 27.488 | 30.578 | 37.697 |
| 16 | 23.542 | 26.296 | 28.845 | 32.000 | 39.252 |
| 17 | 24.769 | 27.587 | 30.191 | 33.409 | 40.790 |
| 18 | 25.989 | 28.869 | 31.526 | 34.805 | 42.312 |
| 19 | 27.204 | 30.144 | 32.852 | 36.191 | 43.820 |
| 20 | 28.412 | 31.410 | 34.170 | 37.566 | 45.315 |
| 21 | 29.615 | 32.671 | 35.479 | 38.932 | 46.797 |
| 22 | 30.813 | 33.924 | 36.781 | 40.289 | 48.268 |
| 23 | 32.007 | 35.172 | 38.076 | 41.638 | 49.728 |
| 24 | 33.196 | 36.415 | 39.364 | 42.980 | 51.179 |
| 25 | 34.382 | 37.652 | 40.646 | 44.314 | 52.620 |
| 26 | 35.563 | 38.885 | 41.923 | 45.642 | 54.052 |
| 27 | 36.741 | 40.113 | 43.195 | 46.963 | 55.476 |
| 28 | 37.916 | 41.337 | 44.461 | 48.278 | 56.892 |
| 29 | 39.087 | 42.557 | 45.722 | 49.588 | 58.301 |
| 30 | 40.256 | 43.773 | 46.979 | 50.892 | 59.703 |
| 31 | 41.422 | 44.985 | 48.232 | 52.191 | 61.098 |
| 32 | 42.585 | 46.194 | 49.480 | 53.486 | 62.487 |
| 33 | 43.745 | 47.400 | 50.725 | 54.776 | 63.870 |
| 34 | 44.903 | 48.602 | 51.966 | 56.061 | 65.247 |
| 35 | 46.059 | 49.802 | 53.203 | 57.342 | 66.619 |
| 36 | 47.212 | 50.998 | 54.437 | 58.619 | 67.985 |
| 37 | 48.363 | 52.192 | 55.668 | 59.893 | 69.347 |
| 38 | 49.513 | 53.384 | 56.896 | 61.162 | 70.703 |
| 39 | 50.660 | 54.572 | 58.120 | 62.428 | 72.055 |
| 40 | 51.805 | 55.758 | 59.342 | 63.691 | 73.402 |
| 41 | 52.949 | 56.942 | 60.561 | 64.950 | 74.745 |
| 42 | 54.090 | 58.124 | 61.777 | 66.206 | 76.084 |
| 43 | 55.230 | 59.304 | 62.990 | 67.459 | 77.419 |
| 44 | 56.369 | 60.481 | 64.201 | 68.710 | 78.750 |
| 45 | 57.505 | 61.656 | 65.410 | 69.957 | 80.077 |
| 46 | 58.641 | 62.830 | 66.617 | 71.201 | 81.400 |
| 47 | 59.774 | 64.001 | 67.821 | 72.443 | 82.720 |
| 48 | 60.907 | 65.171 | 69.023 | 73.683 | 84.037 |
| 49 | 62.038 | 66.339 | 70.222 | 74.919 | 85.351 |
| 50 | 63.167 | 67.505 | 71.420 | 76.154 | 86.661 |
| 51 | 64.295 | 68.669 | 72.616 | 77.386 | 87.968 |
| 52 | 65.422 | 69.832 | 73.810 | 78.616 | 89.272 |
| 53 | 66.548 | 70.993 | 75.002 | 79.843 | 90.573 |
| 54 | 67.673 | 72.153 | 76.192 | 81.069 | 91.872 |
| 55 | 68.796 | 73.311 | 77.380 | 82.292 | 93.168 |
| 56 | 69.919 | 74.468 | 78.567 | 83.513 | 94.461 |
| 57 | 71.040 | 75.624 | 79.752 | 84.733 | 95.751 |
| 58 | 72.160 | 76.778 | 80.936 | 85.950 | 97.039 |
| 59 | 73.279 | 77.931 | 82.117 | 87.166 | 98.324 |
| 60 | 74.397 | 79.082 | 83.298 | 88.379 | 99.607 |
| 61 | 75.514 | 80.232 | 84.476 | 89.591 | 100.888 |
| 62 | 76.630 | 81.381 | 85.654 | 90.802 | 102.166 |
| 63 | 77.745 | 82.529 | 86.830 | 92.010 | 103.442 |
| 64 | 78.860 | 83.675 | 88.004 | 93.217 | 104.716 |
| 65 | 79.973 | 84.821 | 89.177 | 94.422 | 105.988 |
| 66 | 81.085 | 85.965 | 90.349 | 95.626 | 107.258 |
| 67 | 82.197 | 87.108 | 91.519 | 96.828 | 108.526 |
| 68 | 83.308 | 88.250 | 92.689 | 98.028 | 109.791 |
| 69 | 84.418 | 89.391 | 93.856 | 99.228 | 111.055 |
| 70 | 85.527 | 90.531 | 95.023 | 100.425 | 112.317 |
| 71 | 86.635 | 91.670 | 96.189 | 101.621 | 113.577 |
| 72 | 87.743 | 92.808 | 97.353 | 102.816 | 114.835 |
| 73 | 88.850 | 93.945 | 98.516 | 104.010 | 116.092 |
| 74 | 89.956 | 95.081 | 99.678 | 105.202 | 117.346 |
| 75 | 91.061 | 96.217 | 100.839 | 106.393 | 118.599 |
| 76 | 92.166 | 97.351 | 101.999 | 107.583 | 119.850 |
| 77 | 93.270 | 98.484 | 103.158 | 108.771 | 121.100 |
| 78 | 94.374 | 99.617 | 104.316 | 109.958 | 122.348 |
| 79 | 95.476 | 100.749 | 105.473 | 111.144 | 123.594 |
| 80 | 96.578 | 101.879 | 106.629 | 112.329 | 124.839 |
| 81 | 97.680 | 103.010 | 107.783 | 113.512 | 126.083 |
| 82 | 98.780 | 104.139 | 108.937 | 114.695 | 127.324 |
| 83 | 99.880 | 105.267 | 110.090 | 115.876 | 128.565 |
| 84 | 100.980 | 106.395 | 111.242 | 117.057 | 129.804 |
| 85 | 102.079 | 107.522 | 112.393 | 118.236 | 131.041 |
| 86 | 103.177 | 108.648 | 113.544 | 119.414 | 132.277 |
| 87 | 104.275 | 109.773 | 114.693 | 120.591 | 133.512 |
| 88 | 105.372 | 110.898 | 115.841 | 121.767 | 134.746 |
| 89 | 106.469 | 112.022 | 116.989 | 122.942 | 135.978 |
| 90 | 107.565 | 113.145 | 118.136 | 124.116 | 137.208 |
| 91 | 108.661 | 114.268 | 119.282 | 125.289 | 138.438 |
| 92 | 109.756 | 115.390 | 120.427 | 126.462 | 139.666 |
| 93 | 110.850 | 116.511 | 121.571 | 127.633 | 140.893 |
| 94 | 111.944 | 117.632 | 122.715 | 128.803 | 142.119 |
| 95 | 113.038 | 118.752 | 123.858 | 129.973 | 143.344 |
| 96 | 114.131 | 119.871 | 125.000 | 131.141 | 144.567 |
| 97 | 115.223 | 120.990 | 126.141 | 132.309 | 145.789 |
| 98 | 116.315 | 122.108 | 127.282 | 133.476 | 147.010 |
| 99 | 117.407 | 123.225 | 128.422 | 134.642 | 148.230 |
| 100 | 118.498 | 124.342 | 129.561 | 135.807 | 149.449 |
The value of the test-statistic is
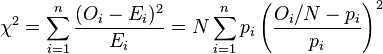
where
- = Pearson's cumulative test statistic, which asymptotically approaches a distribution.
- = the number of observations of type i.
- = total number of observations
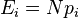 = the expected (theoretical) frequency of type i, asserted by the null hypothesis that the fraction of type i in the population is
= the expected (theoretical) frequency of type i, asserted by the null hypothesis that the fraction of type i in the population is 
- = the number of cells in the table.
The chi-squared statistic can then be used to calculate a p-value by comparing the value of the statistic to a chi-squared distribution. The number of degrees of freedom is equal to the number of cells , minus the reduction in degrees of freedom, 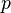 .
.
The result about the numbers of degrees of freedom is valid when the original data are multinomial and hence the estimated parameters are efficient for minimizing the chi-squared statistic. More generally however, when maximum likelihood estimation does not coincide with minimum chi-squared estimation, the distribution will lie somewhere between a chi-squared distribution with 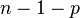 and
and  degrees of freedom (See for instance Chernoff and Lehmann, 1954).
degrees of freedom (See for instance Chernoff and Lehmann, 1954).
Bayesian method
In Bayesian statistics, one would instead use a Dirichlet distribution as conjugate prior. If one took a uniform prior, then the maximum likelihood estimate for the population probability is the observed probability, and one may compute a credible region around this or another estimate.
Test of independence
In this case, an "observation" consists of the values of two outcomes and the null hypothesis is that the occurrence of these outcomes is statistically independent. Each observation is allocated to one cell of a two-dimensional array of cells (called a contingency table) according to the values of the two outcomes. If there are r rows and c columns in the table, the "theoretical frequency" for a cell, given the hypothesis of independence, is
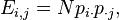
where is the total sample size (the sum of all cells in the table), and
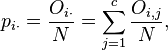
is the fraction of observations of type i ignoring the column attribute (fraction of row totals), and
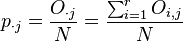
is the fraction of observations of type j ignoring the row attribute (fraction of column totals). The term "frequencies" refers to absolute numbers rather than already normalised values.
The value of the test-statistic is
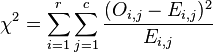
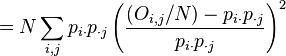
Note that is 0 if and only if 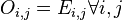 , i.e. only if the expected and true number of observations are equal in all cells.
, i.e. only if the expected and true number of observations are equal in all cells.
Fitting the model of "independence" reduces the number of degrees of freedom by p = r + c − 1. The number of degrees of freedom is equal to the number of cells rc, minus the reduction in degrees of freedom, p, which reduces to (r − 1)(c − 1).
For the test of independence, also known as the test of homogeneity, a chi-squared probability of less than or equal to 0.05 (or the chi-squared statistic being at or larger than the 0.05 critical point) is commonly interpreted by applied workers as justification for rejecting the null hypothesis that the row variable is independent of the column variable.[4] The alternative hypothesis corresponds to the variables having an association or relationship where the structure of this relationship is not specified.
Assumptions
The chi-squared test, when used with the standard approximation that a chi-squared distribution is applicable, has the following assumptions:
- Simple random sample – The sample data is a random sampling from a fixed distribution or population where every collection of members of the population of the given sample size has an equal probability of selection. Variants of the test have been developed for complex samples, such as where the data is weighted. Other forms can be used such as purposive sampling.[5]
- Sample size (whole table) – A sample with a sufficiently large size is assumed. If a chi squared test is conducted on a sample with a smaller size, then the chi squared test will yield an inaccurate inference. The researcher, by using chi squared test on small samples, might end up committing a Type II error.
- Expected cell count – Adequate expected cell counts. Some require 5 or more, and others require 10 or more. A common rule is 5 or more in all cells of a 2-by-2 table, and 5 or more in 80% of cells in larger tables, but no cells with zero expected count. When this assumption is not met, Yates's Correction is applied.
- Independence – The observations are always assumed to be independent of each other. This means chi-squared cannot be used to test correlated data (like matched pairs or panel data). In those cases you might want to turn to McNemar's test.
A test that relies on different assumptions is Fisher's exact test; if its assumption of fixed marginal distributions is met it is substantially more accurate in obtaining a significance level, especially with few observations. In the vast majority of applications this assumption will not be met, and Fisher's exact test will be over conservative and not have correct coverage.[6]
Derivation
The null distribution of the Pearson statistic with j rows and k columns is approximated by the chi-squared distribution with (k − 1)(j − 1) degrees of freedom.[7]
This approximation arises as the true distribution, under the null hypothesis, if the expected value is given by a multinomial distribution. For large sample sizes, the central limit theorem says this distribution tends toward a certain multivariate normal distribution.
Two cells
In the special case where there are only two cells in the table, the expected values follow a binomial distribution,
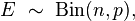
where
- p = probability, under the null hypothesis,
- n = number of observations in the sample.
In the above example the hypothesised probability of a male observation is 0.5, with 100 samples. Thus we expect to observe 50 males.
If n is sufficiently large, the above binomial distribution may be approximated by a Gaussian (normal) distribution and thus the Pearson test statistic approximates a chi-squared distribution,
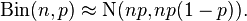
Let O1 be the number of observations from the sample that are in the first cell. The Pearson test statistic can be expressed as
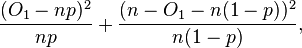
which can in turn be expressed as
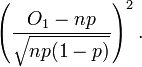
By the normal approximation to a binomial this is the squared of one standard normal variate, and hence is distributed as chi-squared with 1 degree of freedom. Note that the denominator is one standard deviation of the Gaussian approximation, so can be written
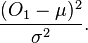
So as consistent with the meaning of the chi-squared distribution, we are measuring how probable the observed number of standard deviations away from the mean is under the Gaussian approximation (which is a good approximation for large n).
The chi-squared distribution is then integrated on the right of the statistic value to obtain the P-value, which is equal to the probability of getting a statistic equal or bigger than the observed one, assuming the null hypothesis.
Two-by-two contingency tables
When the test is applied to a contingency table containing two rows and two columns, the test is equivalent to a Z-test of proportions.
Many cells
Similar arguments as above lead to the desired result. Each cell (except the final one, whose value is completely determined by the others) is treated as an independent binomial variable, and their contributions are summed and each contributes one degree of freedom.
Let us now prove that the distribution indeed approaches asymptotically the χ2 distribution as the number of observations approaches infinity.
Let n be the number of observations, m the number of cells and pi the probability of an observation to fall in the i-th cell, for  .
We denote by {ki} the configuration where for each i there are ki observations in the i-th cell.
Note that
.
We denote by {ki} the configuration where for each i there are ki observations in the i-th cell.
Note that 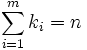 and
and 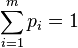 .
Let χ2P({ki},{pi}) be Pearson's cumulative test statistic for such a configuration, and let
χ2P({pi}) be the distribution of this statistic.
We will show that the latter probability approaches the χ2 distribution with m-1 degrees of freedom, as n approaches infinity.
.
Let χ2P({ki},{pi}) be Pearson's cumulative test statistic for such a configuration, and let
χ2P({pi}) be the distribution of this statistic.
We will show that the latter probability approaches the χ2 distribution with m-1 degrees of freedom, as n approaches infinity.
For any arbitrary value T:
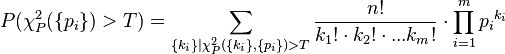
We will use a procedure similar to the approximation in de Moivre–Laplace theorem. Contributions from small ki-s are of subleading order in n and thus for large n we may use Stirling's formula for both n! and ki! to get the following:
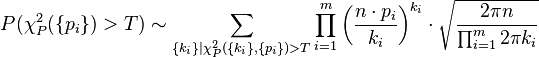
By substituting for 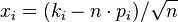 for i = 1...m-1, we may approximate for large n the sum over the ki-s by an integral over the
xi-s. Noting that:
for i = 1...m-1, we may approximate for large n the sum over the ki-s by an integral over the
xi-s. Noting that: 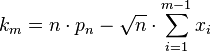 , we arrive at
, we arrive at
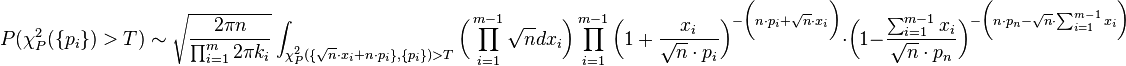
![=
\sqrt{\frac{2\pi n}{\prod_i^m \bigg(2\pi n\cdot p_i + 2\pi \sqrt{n}\cdot x_i\bigg)}}
\int_{\chi^2_P(\{\sqrt{n}\cdot x_i+n\cdot p_i\},\{p_i\}) > T} \bigg(\prod_{i=1}^{m-1} {\sqrt{n} dx_i}\bigg)
\prod_{i=1}^{m-1} {\exp\bigg[-\bigg(n\cdot p_i + \sqrt{n}\cdot x_i \bigg)\cdot \ln \bigg(1+\frac{x_i}{\sqrt{n}\cdot p_i}\bigg)\bigg]} \cdot
\exp\bigg[ -\bigg(n\cdot p_n-\sqrt{n}\cdot \sum_{i=1}^{m-1}x_i\bigg)\cdot \ln \bigg(1-\frac{\sum_{i=1}^{m-1}{x_i}}{\sqrt{n}\cdot p_n}\bigg) \bigg]](../I/m/64b77bd9cc0362b5e48cf7b82d1825a9.png)
By expanding the logarithm and taking the leading terms in n, we get
![P(\chi^2_P(\{p_i\}) > T) \sim
\frac{1}{\prod_{i=1}^{m-1} \bigg(\sqrt{p_i}\bigg)}\cdot \frac{1}{(2\pi)^{m-1}\sqrt{p_n}}
\int_{\chi^2_P(\{\sqrt{n}\cdot x_i+n\cdot p_i\},\{p_i\}) > T} \bigg(\prod_{i=1}^{m-1} dx_i\bigg)
\prod_{i=1}^{m-1} {\exp\bigg[-\frac{1}{2}\bigg(\sum_{i=1}^{m-1}{x_i^2/p_i} + (\sum_{i=1}^{m-1}{x_i})^2 /p_n\bigg)\bigg]}](../I/m/37e6a6267986ab656bc9c256efe98adc.png)
Now, it should be noted that Pearson's chi, 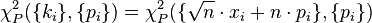 , is precisely
the argument of the exponent (except for the -1/2; note that the final term in the exponent's argument is equal to
, is precisely
the argument of the exponent (except for the -1/2; note that the final term in the exponent's argument is equal to 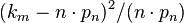 ).
).
This argument can be written as: 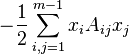 , where i,j = 1... m-1 and
, where i,j = 1... m-1 and 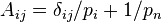 . A is a regular symmetric (m-1)x(m-1) matrix,
and hence diagonalizable. It is therefore possible to make a linear change of variables in {x_i} so as to get m-1 new variables {x'_i} so that:
. A is a regular symmetric (m-1)x(m-1) matrix,
and hence diagonalizable. It is therefore possible to make a linear change of variables in {x_i} so as to get m-1 new variables {x'_i} so that:
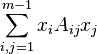 =
= 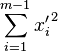 .
This linear change of variables merely multiplies the integral by a constant Jacobian, so we get:
.
This linear change of variables merely multiplies the integral by a constant Jacobian, so we get:
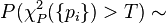
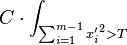
![\bigg(\prod_{i=1}^{m-1} dx^{\prime}_i\bigg) \prod_{i=1}^{m-1} {\exp\bigg[-\frac{1}{2}\bigg(\sum_{i=1}^{m-1}{{x^{\prime}_i}^2}\bigg)\bigg]}](../I/m/675822c65383eed9bd336900d751993c.png)
Where C is a constant.
This is the probability that squared sum of m-1 independent normally distributed variables of zero mean and variance 1 will be greater than T, namely that χ2 with m-1 degrees of freedom is larger than T.
We have thus shown that at the limit where n approaches infinity, the distribution of Pearson's chi approaches the chi distribution with m-1 degrees of freedom.
Examples
Fairness of dice
A 6-sided die is thrown 60 times. The number of times it lands with 1, 2, 3, 4, 5 and 6 face up is 5, 8, 9, 8, 10 and 20, respectively. Is the die biased, according to the Pearson's chi-squared test at a significance level of
- 95%, and
- 99%?
n is 6 as there are 6 possible outcomes, 1 to 6. The null hypothesis is that the die is unbiased, hence each number is expected to occur the same number of times, in this case, 60/n = 10. The outcomes can be tabulated as follows:
| i | Oi | Ei | Oi −Ei | (Oi −Ei )2 | (Oi −Ei )2/Ei |
|---|---|---|---|---|---|
| 1 | 5 | 10 | −5 | 25 | 2.5 |
| 2 | 8 | 10 | −2 | 4 | 0.4 |
| 3 | 9 | 10 | −1 | 1 | 0.1 |
| 4 | 8 | 10 | −2 | 4 | 0.4 |
| 5 | 10 | 10 | 0 | 0 | 0 |
| 6 | 20 | 10 | 10 | 100 | 10 |
| Sum | 13.4 | ||||
The number of degrees of freedom is n − 1 = 5. The Upper-tail critical values of chi-square distribution table gives a critical value of 11.070 at 95% significance level:
| Degrees of freedom |
Probability less than the critical value | ||||
|---|---|---|---|---|---|
| 0.90 | 0.95 | 0.975 | 0.99 | 0.999 | |
| 5 | 9.236 | 11.070 | 12.833 | 15.086 | 20.515 |
As the chi-squared statistic of 13.4 exceeds this critical value, we reject the null hypothesis and conclude that the die is biased at 95% significance level.
At 99% significance level, the critical value is 15.086. As the chi-squared statistic does not exceed it, we fail to reject the null hypothesis and thus conclude that there is insufficient evidence to show that the die is biased at 99% significance level.
Goodness of fit
In this context, the frequencies of both theoretical and empirical distributions are unnormalised counts, and for a chi-squared test the total sample sizes of both these distributions (sums of all cells of the corresponding contingency tables) have to be the same.
For example, to test the hypothesis that a random sample of 100 people has been drawn from a population in which men and women are equal in frequency, the observed number of men and women would be compared to the theoretical frequencies of 50 men and 50 women. If there were 44 men in the sample and 56 women, then
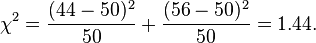
If the null hypothesis is true (i.e., men and women are chosen with equal probability), the test statistic will be drawn from a chi-squared distribution with one degree of freedom (because if the male frequency is known, then the female frequency is determined).
Consultation of the chi-squared distribution for 1 degree of freedom shows that the probability of observing this difference (or a more extreme difference than this) if men and women are equally numerous in the population is approximately 0.23. This probability is higher than conventional criteria for statistical significance (0.01 or 0.05), so normally we would not reject the null hypothesis that the number of men in the population is the same as the number of women (i.e., we would consider our sample within the range of what we'd expect for a 50/50 male/female ratio.)
Problems
The approximation to the chi-squared distribution breaks down if expected frequencies are too low. It will normally be acceptable so long as no more than 20% of the events have expected frequencies below 5. Where there is only 1 degree of freedom, the approximation is not reliable if expected frequencies are below 10. In this case, a better approximation can be obtained by reducing the absolute value of each difference between observed and expected frequencies by 0.5 before squaring; this is called Yates's correction for continuity.
In cases where the expected value, E, is found to be small (indicating a small underlying population probability, and/or a small number of observations), the normal approximation of the multinomial distribution can fail, and in such cases it is found to be more appropriate to use the G-test, a likelihood ratio-based test statistic. When the total sample size is small, it is necessary to use an appropriate exact test, typically either the binomial test or (for contingency tables) Fisher's exact test. This test uses the conditional distribution of the test statistic given the marginal totals; however, it does not assume that the data were generated from an experiment in which the marginal totals are fixed and is valid whether or not that is the case.
See also
- G-test, test to which chi-squared test is an approximation
- Degrees of freedom (statistics), including Degrees of freedom (statistics)#Effective degrees of freedom for correlated observations and regularized models
- Fisher's exact test
- Median test
- Chi-squared test
- Lexis ratio, earlier statistic, replaced by chi-squared
- Chi-squared nomogram
- Deviance (statistics), another measure of the quality of fit.
- Yates's correction for continuity
- Mann–Whitney U
- Cramér's V – a measure of correlation for the chi-squared test.
- Minimum chi-square estimation
Notes
- ↑ Gosall, Narinder Kaur Gosall, Gurpal Singh (2012). Doctor's Guide to Critical Appraisal. (3. ed.). Knutsford: PasTest. pp. 129–130. ISBN 9781905635818.
- ↑ Pearson, Karl (1900). "On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling" (PDF). Philosophical Magazine Series 5 50 (302): 157–175. doi:10.1080/14786440009463897.
- ↑ "1.3.6.7.4. Critical Values of the Chi-Square Distribution". Retrieved 14 October 2014.
- ↑ "Critical Values of the Chi-Squared Distribution". NIST/SEMATECH e-Handbook of Statistical Methods. National Institute of Standards and Technology.
- ↑ See Field, Andy. Discovering Statistics Using SPSS. for assumptions on Chi Square.
- ↑ "A Bayesian Formulation for Exploratory Data Analysis and Goodness-of-Fit Testing" (PDF). International Statistical Review. p. 375.
- ↑ Statistics for Applications. MIT OpenCourseWare. Lecture 23. Pearson's Theorem. Retrieved 21 March 2007.
References
- Chernoff, H.; Lehmann, E. L. (1954). "The Use of Maximum Likelihood Estimates in Tests for Goodness of Fit". The Annals of Mathematical Statistics 25 (3): 579–586. doi:10.1214/aoms/1177728726.
- Plackett, R. L. (1983). "Karl Pearson and the Chi-Squared Test". International Statistical Review (International Statistical Institute (ISI)) 51 (1): 59–72. doi:10.2307/1402731. JSTOR 1402731.
- Greenwood, P.E.; Nikulin, M.S. (1996). A guide to chi-squared testing. New York: Wiley. ISBN 0-471-55779-X.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||