bzip2
|
| |
| Developer(s) | Julian Seward |
|---|---|
| Stable release | 1.0.6 / 20 September 2010 |
| Operating system | Cross-platform |
| Type | Data compression |
| License | BSD-like license[1] |
| Website |
bzip |
bzip2 is a free and open-source file compression program that uses the Burrows–Wheeler algorithm. It only compresses single files and is not a file archiver. It is developed and maintained by Julian Seward. Seward made the first public release of bzip2, version 0.15, in July 1996. The compressor's stability and popularity grew over the next several years, and Seward released version 1.0 in late 2000.
Compression efficiency
bzip2 compresses most files more effectively than the older LZW (.Z) and Deflate (.zip and .gz) compression algorithms, but is considerably slower. LZMA is generally more space-efficient than bzip2 at the expense of slower compression speed, while having much faster decompression.[2]
bzip2 compresses data in blocks of size between 100 and 900 kB and uses the Burrows–Wheeler transform to convert frequently-recurring character sequences into strings of identical letters. It then applies move-to-front transform and Huffman coding. bzip2's ancestor bzip used arithmetic coding instead of Huffman. The change was made because of a software patent restriction.[3]
bzip2 performance is asymmetric, as decompression is relatively fast. Motivated by the large CPU time required for compression, a modified version was created in 2003 called pbzip2 that supported multi-threading, giving almost linear speed improvements on multi-CPU and multi-core computers.[4] As of May 2010, this functionality has not been incorporated into the main project.
Like gzip, bzip2 is only a data compressor. It is not an archiver like tar or ZIP; the program itself has no facilities for multiple files, encryption or archive-splitting, but, in the UNIX tradition, relies instead on separate external utilities such as tar and GnuPG for these tasks.
Compression stack
Bzip2 uses several layers of compression techniques stacked on top of each other, which occur in the following order during compression and the reverse order during decompression:
- Run-length encoding (RLE) of initial data
- Burrows–Wheeler transform (BWT) or block sorting
- Move to front (MTF) transform
- Run-length encoding (RLE) of MTF result
- Huffman coding
- Selection between multiple Huffman tables
- Unary base 1 encoding of Huffman table selection
- Delta encoding (Δ) of Huffman code bit-lengths
- Sparse bit array showing which symbols are used
Initial run-length encoding
Any sequence of 4 to 255 consecutive duplicate symbols is replaced by the first four symbols and a repeat length between 0 and 251. Thus the sequence "AAAAAAABBBBCCCD" is replaced with "AAAA\3BBBB\0CCCD", where "\3" and "\0" represent byte values 3 and 0 respectively. Runs of symbols are always transformed after four consecutive symbols, even if the run-length is set to zero, to keep the transformation reversible.
In the worst case, it can cause an expansion of 1.25 and best case a reduction to <0.02 . While the specification theoretically allows for runs of length 256–259 to be encoded, the reference encoder will not produce such output.
The author of bzip2 has stated that the RLE step was a historical mistake and was only intended to protect the original BWT implementation from pathological cases.[5]
Burrows–Wheeler transform
This is the reversible block-sort that is at the core of bzip2. The block is entirely self-contained, with input and output buffers remaining the same size—in bzip2, the operating limit for this stage is 900 kB. For the block-sort, a (notional) matrix is created in which row  contains the whole of the buffer, rotated to start from the
contains the whole of the buffer, rotated to start from the 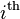 symbol. Following rotation, the rows of the matrix are sorted into alphabetic (numerical) order. A 24-bit pointer is stored marking the starting position for when the block is untransformed. In practice, it is not necessary to construct the full matrix; rather, the sort is performed using pointers for each position in the buffer. The output buffer is the last column of the matrix; this contains the whole buffer, but reordered so that it is likely to contain large runs of identical symbols.
symbol. Following rotation, the rows of the matrix are sorted into alphabetic (numerical) order. A 24-bit pointer is stored marking the starting position for when the block is untransformed. In practice, it is not necessary to construct the full matrix; rather, the sort is performed using pointers for each position in the buffer. The output buffer is the last column of the matrix; this contains the whole buffer, but reordered so that it is likely to contain large runs of identical symbols.
Move to front transform
Again, this transform does not alter the size of the processed block. Each of the symbols in use in the document is placed in an array. When a symbol is processed, it is replaced by its location (index) in the array and that symbol is shuffled to the front of the array. The effect is that immediately recurring symbols are replaced by zero symbols (long runs of any arbitrary symbol thus become runs of zero symbols), while other symbols are remapped according to their local frequency.
Much "natural" data contains identical symbols that recur within a limited range (text is a good example). As the MTF transform assigns low values to symbols that reappear frequently, this results in a data stream which contains many symbols in the low integer range, many of them being identical (different recurring input symbols can actually map to the same output symbol). Such data can be very efficiently encoded by any legacy compression method.
Run-length encoding of MTF result
Long strings of zeros in the output of the move-to-front transform (which come from repeated symbols in the output of the BWT) are replaced by a sequence of two special codes, RUNA and RUNB, which represent the run-length as a binary number. Actual zeros are never encoded in the output; a lone zero becomes RUNA. (This step in fact is done at the same time as MTF is; whenever MTF would produce zero, it instead increases a counter to then encode with RUNA and RUNB.)
The sequence 0,0,0,0,0,1 would be represented as RUNA,RUNB,1; RUNA,RUNB represents the value 5 as described below. The run-length code is terminated by reaching another normal symbol. This RLE process is more flexible than the initial RLE step, as it is able to encode arbitrarily long integers (in practice, this is usually limited by the block size, so that this step does not encode a run of more than 900000 bytes). The run-length is encoded in this fashion: assigning place values of 1 to the first bit, 2 to the second, 4 to the third, etc. in the sequence, multiply each place value in a RUNB spot by 2, and add all the resulting place values (for RUNA and RUNB values alike) together. This is similar to base-2 bijective numeration. Thus, the sequence RUNA,RUNB results in the value (1 + 2 × 2) = 5. As a more complicated example:
RUNA RUNB RUNA RUNA RUNB (ABAAB) 1 2 4 8 16 1 4 4 8 32 = 49
Huffman coding
This process replaces fixed length symbols in the range 0–258 with variable length codes based on the frequency of use. More frequently used codes end up shorter (2–3 bits) whilst rare codes can be allocated up to 20 bits. The codes are selected carefully so that no sequence of bits can be confused for a different code.
The end-of-stream code is particularly interesting. If there are n different bytes (symbols) used in the uncompressed data, then the Huffman code will consist of two RLE codes (RUNA and RUNB), n − 1 symbol codes and one end-of-stream code. Because of the combined result of the MTF and RLE encodings in the previous two steps, there is never any need to explicitly reference the first symbol in the MTF table (would be zero in the ordinary MTF), thus saving one symbol for the end-of-stream marker (and explaining why only n − 1 symbols are coded in the Huffman tree). In the extreme case where only one symbol is used in the uncompressed data, there will be no symbol codes at all in the Huffman tree, and the entire block will consist of RUNA and RUNB (implicitly repeating the single byte) and an end-of-stream marker with value 2.
- 0: RUNA
1: RUNB
2–257: byte values 0–255
258: end of stream, finish processing. (could be as low as 2).
Multiple Huffman tables
Several identically-sized Huffman tables can be used with a block if the gain from using them is greater than the cost of including the extra table. At least two (2) and up to six (6) tables can be present, with the most appropriate table being reselected before every 50 symbols processed. This has the advantage of having very responsive Huffman dynamics without having to continuously supply new tables, as would be required in DEFLATE. Run-length encoding in the previous step is designed to take care of codes that have an inverse probability of use higher than the shortest code Huffman code in use.
Unary encoding of Huffman table selection
If multiple Huffman tables are in use, the selection of each table (numbered 0..5) is done from a list by a zero-terminated bit run between one (1) and six (6) bits in length. The selection is into a MTF list of the tables. Using this feature results in a maximum expansion of around 1.015, but generally less. This expansion is likely to be greatly over-shadowed by the advantage of selecting more appropriate Huffman tables and the common-case of continuing to use the same Huffman table is represented as a single bit. Rather than unary encoding, effectively this is an extreme form of a Huffman tree where each code has half the probability of the previous code.
Delta encoding
Huffman code bit-lengths are required to reconstruct each of the used canonical Huffman tables. Each bit-length is stored as an encoded difference against the previous code bit-length. A zero-bit (0) means that the previous bit-length should be duplicated for the current code, whilst a one-bit (1) means that a further bit should be read and the bit-length incremented or decremented based on that value.
In the common case a single bit is used per symbol per table and the worst case—going from length one (1) to length twenty (20)—would require approximately 37 bits. As a result of the earlier MTF encoding, code lengths would start at 2–3 bits long (very frequently used codes) and gradually increase, meaning that the delta format is fairly efficient—requiring around 300 bits (38 bytes) per full Huffman table.
Sparse bit array
A bitmap is used to show which symbols are used inside the block and should be included in the Huffman trees. Binary data is likely to use all 256 symbols representable by a byte, whereas textual data may only use a small subset of available values, perhaps covering the ASCII range between 32 and 126. Storing 256 zero bits would be inefficient if they were mostly unused. A sparse method is used: the 256 symbols are divided up into 16 ranges and only if symbols are used within that block is a 16-bit array included. The presence of each of these 16 ranges is indicated by an additional 16-bit bit array at the front.
The total bitmap uses between 32 and 272 bits of storage (4–34 bytes). For contrast, the DEFLATE algorithm would show the absence of symbols by encoding the symbols as having a (zero) bit-length with Run Length Encoding and additional Huffman coding.
File format
| Filename extension |
.bz2 |
|---|---|
| Internet media type |
application/x-bzip2 |
| Type code | Bzp2 |
| Uniform Type Identifier (UTI) | public.archive.bzip2 |
| Magic number | BZh |
| Developed by | Julian Seward |
| Type of format | Data compression |
| Open format? | Yes |
A .bz2 stream consists of a 4-byte header, followed by zero or more compressed blocks, immediately followed by an end-of-stream marker containing a 32-bit CRC for the plaintext whole stream processed. The compressed blocks are bit-aligned and no padding occurs.
.magic:16 = 'BZ' signature/magic number
.version:8 = 'h' for Bzip2 ('H'uffman coding), '0' for Bzip1 (deprecated)
.hundred_k_blocksize:8 = '1'..'9' block-size 100 kB-900 kB (uncompressed)
.compressed_magic:48 = 0x314159265359 (BCD (pi))
.crc:32 = checksum for this block
.randomised:1 = 0=>normal, 1=>randomised (deprecated)
.origPtr:24 = starting pointer into BWT for after untransform
.huffman_used_map:16 = bitmap, of ranges of 16 bytes, present/not present
.huffman_used_bitmaps:0..256 = bitmap, of symbols used, present/not present (multiples of 16)
.huffman_groups:3 = 2..6 number of different Huffman tables in use
.selectors_used:15 = number of times that the Huffman tables are swapped (each 50 bytes)
*.selector_list:1..6 = zero-terminated bit runs (0..62) of MTF'ed Huffman table (*selectors_used)
.start_huffman_length:5 = 0..20 starting bit length for Huffman deltas
*.delta_bit_length:1..40 = 0=>next symbol; 1=>alter length
{ 1=>decrement length; 0=>increment length } (*(symbols+2)*groups)
.contents:2..∞ = Huffman encoded data stream until end of block (max. 7372800 bit)
.eos_magic:48 = 0x177245385090 (BCD sqrt(pi))
.crc:32 = checksum for whole stream
.padding:0..7 = align to whole byte
Because of the first-stage RLE compression (see above), the maximum length of plaintext that a single 900 kB bzip2 block can contain is around 46 MB (45,899,236 bytes). This can occur if the whole plaintext consists entirely of repeated values (the resulting .bz2 file in this case is 46 bytes long). An even smaller file of 40 bytes can be achieved by using an input containing entirely values of 251, an apparent compression ratio of 1147480.9:1.
The compressed blocks in bzip2 can be independently decompressed, without having to process earlier blocks. This means that bzip2 files can be decompressed in parallel, making it a good format for use in big data applications with cluster computing frameworks like Hadoop and Apache Spark.[6]
Implementations
In addition to Julian Seward's original reference implementation, the following programs support bzip2 format.
- 7-Zip: Written by Igor Pavlov in C++, the 7-Zip suite contains a bzip2 encoder/decoder which is freely licensed. 7-Zip comes with multi-threading support.
- micro-bzip2: A version by Rob Landley designed for reduced compiled code size and available under the GNU LGPL.
- PBZIP2: Parallel pthreads-based implementation in C++ by Jeff Gilchrist (and Windows version).
- bzip2smp: A modification to
libbzip2that has SMP parallelisation "hacked in" by Konstantin Isakov. - smpbzip2: Another go at parallel bzip2, by Niels Werensteijn.
- pyflate: A pure-Python stand-alone bzip2 and DEFLATE (gzip) decoder by Paul Sladen. Probably useful for research and prototyping, made available under the BSD/GPL/LGPL, or any other DFSG-compatible license.
- Arnaud Bouchez's BZip: Implementation using C library or optimized i386 assembler code.
- lbzip2: Parallel pthreads-based bzip2/bunzip2 (bzip2 compressor/decompressor) filter for sequential access input/output, by László Érsek.
- mpibzip2: An MPI-enabled implementation that compresses/decompresses in parallel, by Jeff Gilchrist, available under a BSD-style license.
- Apache Commons Compress Apache Commons Compress project contains Java implementations of Bzip2 compressor and decompressor.
- jbzip2: A Java implementation of bzip2 made available under the MIT license
- DotNetZip: Includes a C# implementation of bzip2, derived from the Java implementation in Apache Commons Compress. Includes a multi-threaded .NET bzip2 encoder/decoder library, and a bzip2 command-line tool in managed code.
- DotNetCompression: A streaming implementation of bzip2 in managed C# that conforms to the API of System.IO.Compression and includes assemblies for .NET Framework, .NET Compact Framework, Xamarin.iOS, Xamarin.Android, Xamarin.Mac, Windows Phone, Xbox 360, Silverlight, Mono and as a Portable Class Library.
See also
- Comparison of archive formats
- Comparison of file archivers
- List of archive formats
- List of file archivers
- List of Unix programs
- rzip
References
- ↑ "bzip2 : Home". Julian Seward. Retrieved 2008-09-27.
Why would I want to use it? [..] Because it's open-source (BSD-style license), and, as far as I know, patent-free.
- ↑ http://compressionratings.com/comp.cgi?7-zip+9.12b++bzip2+1.0.5++gzip+1.3.3+-5
- ↑ The bzip2 home page at the Wayback Machine (archived 4 July 1998) - section "How does it relate to your previous offering (bzip-0.21) ?"
- ↑ "bzip2 vs pbzip2 on quad-core".
- ↑ http://www.bzip.org/1.0.3/html/misc.html
- ↑ "[HADOOP-4012] Providing splitting support for bzip2 compressed files - ASF JIRA". Apache Software Foundation. 2009. Retrieved 2015-10-14.
External links
- Official website
- The bzip2 Command - by The Linux Information Project (LINFO)
- bzip2 for Windows
- Graphical bzip2 for Windows(WBZip2)
- MacBzip2 (for Classic Mac OS; under Mac OS X, the standard bzip2 is available at the command line)
- Feature comparison and benchmarks for different kinds of parallel bzip2 implementations available
- 4 Parallel bzip2 Implementations at The Data Compression News Blog
- The original bzip compressor - may be restricted by patents
| ||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||