Brown clustering
Brown clustering is a hard hierarchical agglomerative clustering problem based on distributional information. It is typically applied to text, grouping words into clusters that are assumed to be semantically related by virtue of their having been embedded in similar contexts.
Introduction
In natural language processing, Brown clustering[1][2] or IBM clustering[3] is a form of hierarchical clustering of words based on the contexts in which they occur, proposed by Peter Brown, Vincent Della Pietra, Peter deSouza, Jennifer Lai, and Robert Mercer of IBM in the context of language modeling.[4] The intuition behind the method is that a class-based language model (also called cluster n-gram model[3]), i.e. one where probabilities of words are based on the classes (clusters) of previous words, is used to address the data sparsity problem inherent in language modeling.
Jurafsky and Martin give the example of a flight reservation system that needs to estimate the likelihood of the bigram "to Shanghai", without having seen this in a training set.[3] The system can obtain a good estimate if it can cluster "Shanghai" with other city names, then make its estimate based on the likelihood of phrases such as "to London", "to Beijing" and "to Denver".
Technical definition
Brown groups items (i.e., types) into classes, using a binary merging criterion based on the log-probability of a text under a class-based language model, i.e. a probability model that takes the clustering into account. Thus, AMI is the optimisation function, and merges are chosen such that they incur the least loss in global mutual information.
As a result, the output can be thought of not only as a binary tree but perhaps more helpfully as a sequence of merges, terminating with one big class of all words. This model has the same general form as a hidden Markov model,[1] reduced to bigram probabilities in Brown's solution to the problem. MI is defined as:
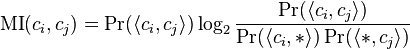
Finding the clustering which maximizes the likelihood of the data is computationally expensive. The approach proposed by Brown et al. is a greedy heuristic.
The work also suggests use of Brown clusterings as a simplistic bigram class-based language model. Given cluster membership indicators ci for the tokens wi in a text, the probability of the word instance wi given preceding word wi-1 is given by:[3][5]
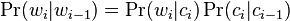
This has been criticised as being of limited utility, as it only ever predicts the most common word in any class, and so is restricted to |c| word types; this is reflected in the low relative reduction in perplexity found when using this model and Brown.
Variations
Other works have examined trigrams in their approaches to the Brown clustering problem.[6]
Brown clustering as proposed generates a fixed number of output classes. It is important to choose the correct number of classes, which is task-dependent.[7] The cluster memberships of words resulting from Brown clustering can be used as features in a variety of machine-learned natural language processing tasks.[2]
See also
References
- 1 2 Percy Liang (2005). Semi-Supervised Learning for Natural Language (PDF) (M. Eng.). MIT. pp. 44–52.
- 1 2 Joseph Turian; Lev Ratinov; Yoshua Bengio (2010). Word representations: a simple and general method for semi-supervised learning (PDF). Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.
- 1 2 3 4 Daniel Jurafsky; James H. Martin (2009). Speech and Language Processing. Pearson Education International. pp. 145–146.
- ↑ Peter F. Brown; Peter V. deSouza; Robert L. Mercer; Vincent J. Della Pietra; Jenifer C. Lai (1992). "Class-based n-gram models of natural language" (PDF). Computational Linguistics 18 (4).
- ↑ Šuster, Simon. "Brown et al. 1992 Clustering" (PDF). Retrieved 20 October 2015.
- ↑ Sven Martin; Jorg Liermann; Hermann Ney (1999). "Algorithms for bigram and trigram word clustering". Speech Communication 24 (1).
- ↑ Leon Derczynski; Sean Chester; Kenneth S. Bogh (2015). Tune your Brown clustering, please (PDF). Proceedings of the conference on Recent Advances in Natural Language Processing.