BrownBoost
BrownBoost is a boosting algorithm that may be robust to noisy datasets. BrownBoost is an adaptive version of the boost by majority algorithm. As is true for all boosting algorithms, BrownBoost is used in conjunction with other machine learning methods. BrownBoost was introduced by Yoav Freund in 2001.[1]
Motivation
AdaBoost performs well on a variety of datasets; however, it can be shown that AdaBoost does not perform well on noisy data sets.[2] This is a result of AdaBoost's focus on examples that are repeatedly misclassified. In contrast, BrownBoost effectively "gives up" on examples that are repeatedly misclassified. The core assumption of BrownBoost is that noisy examples will be repeatedly mislabeled by the weak hypotheses and non-noisy examples will be correctly labeled frequently enough to not be "given up on." Thus only noisy examples will be "given up on," whereas non-noisy examples will contribute to the final classifier. In turn, if the final classifier is learned from the non-noisy examples, the generalization error of the final classifier may be much better than if learned from noisy and non-noisy examples.
The user of the algorithm can set the amount of error to be tolerated in the training set. Thus, if the training set is noisy (say 10% of all examples are assumed to be mislabeled), the booster can be told to accept a 10% error rate. Since the noisy examples may be ignored, only the true examples will contribute to the learning process.
Algorithm Description
BrownBoost uses a non-convex potential loss function, thus it does not fit into the AnyBoost framework. The non-convex optimization provides a method to avoid overfitting noisy data sets. However, in contrast to boosting algorithms that analytically minimize a convex loss function (e.g. AdaBoost and LogitBoost), BrownBoost solves a system of two equations and two unknowns using standard numerical methods.
The only parameter of BrownBoost ( in the algorithm) is the "time" the algorithm runs. The theory of BrownBoost states that each hypothesis takes a variable amount of time (
in the algorithm) is the "time" the algorithm runs. The theory of BrownBoost states that each hypothesis takes a variable amount of time ( in the algorithm) which is directly related to the weight given to the hypothesis
in the algorithm) which is directly related to the weight given to the hypothesis  . The time parameter in BrownBoost is analogous to the number of iterations
. The time parameter in BrownBoost is analogous to the number of iterations  in AdaBoost.
in AdaBoost.
A larger value of means that BrownBoost will treat the data as if it were less noisy and therefore will give up on fewer examples. Conversely, a smaller value of means that BrownBoost will treat the data as more noisy and give up on more examples.
During each iteration of the algorithm, a hypothesis is selected with some advantage over random guessing. The weight of this hypothesis and the "amount of time passed" during the iteration are simultaneously solved in a system of two non-linear equations ( 1. uncorrelate hypothesis w.r.t example weights and 2. hold the potential constant) with two unknowns (weight of hypothesis and time passed ). This can be solved by bisection (as implemented in the JBoost software package) or Newton's method (as described in the original paper by Freund). Once these equations are solved, the margins of each example (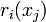 in the algorithm) and the amount of time remaining
in the algorithm) and the amount of time remaining  are updated appropriately. This process is repeated until there is no time remaining.
are updated appropriately. This process is repeated until there is no time remaining.
The initial potential is defined to be 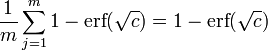 . Since a constraint of each iteration is that the potential be held constant, the final potential is
. Since a constraint of each iteration is that the potential be held constant, the final potential is 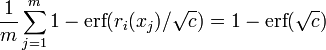 . Thus the final error is likely to be near
. Thus the final error is likely to be near 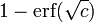 . However, the final potential function is not the 0-1 loss error function. For the final error to be exactly , the variance of the loss function must decrease linearly w.r.t. time to form the 0-1 loss function at the end of boosting iterations. This is not yet discussed in the literature and is not in the definition of the algorithm below.
. However, the final potential function is not the 0-1 loss error function. For the final error to be exactly , the variance of the loss function must decrease linearly w.r.t. time to form the 0-1 loss function at the end of boosting iterations. This is not yet discussed in the literature and is not in the definition of the algorithm below.
The final classifier is a linear combination of weak hypotheses and is evaluated in the same manner as most other boosting algorithms.
BrownBoost Learning Algorithm Definition
Input:
-
 training examples
training examples 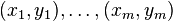 where
where 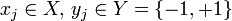
- The parameter
Initialise:
-
 . The value of is the amount of time remaining in the game)
. The value of is the amount of time remaining in the game) -
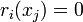
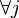 . The value of is the margin at iteration
. The value of is the margin at iteration  for example
for example 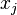 .
.
While  :
:
- Set the weights of each example:
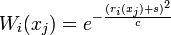 , where is the margin of example
, where is the margin of example - Find a classifier
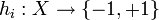 such that
such that 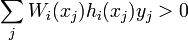
- Find values
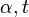 that satisfy the equation:
that satisfy the equation:
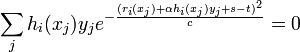 .
.
(Note this is similar to the condition![E_{W_{i+1}}[h_i(x_j) y_j]=0](../I/m/bfdd3485ea20221358c27809587f7967.png) set forth by Schapire and Singer.[3] In this setting, we are numerically finding the
set forth by Schapire and Singer.[3] In this setting, we are numerically finding the 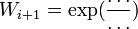 such that .)
such that .)
This update is subject to the constraint
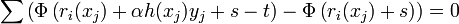 ,
,
where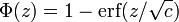 is the potential loss for a point with margin
is the potential loss for a point with margin - Update the margins for each example:
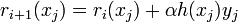
- Update the time remaining:
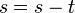
Output: 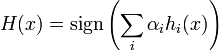
Empirical Results
In preliminary experimental results with noisy datasets, BrownBoost outperformed AdaBoost's generalization error; however, LogitBoost performed as well as BrownBoost.[4] An implementation of BrownBoost can be found in the open source software JBoost.
References
- ↑ Yoav Freund. An adaptive version of the boost by majority algorithm. Machine Learning, 43(3):293--318, June 2001.
- ↑ Dietterich, T. G., (2000). An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization. Machine Learning, 40 (2) 139-158.
- ↑ Robert Schapire and Yoram Singer. Improved Boosting Using Confidence-rated Predictions. Journal of Machine Learning, Vol 37(3), pages 297-336. 1999
- ↑ Ross A. McDonald, David J. Hand, Idris A. Eckley. An Empirical Comparison of Three Boosting Algorithms on Real Data Sets with Artificial Class Noise. Multiple Classifier Systems, In Series Lecture Notes in Computer Science, pages 35-44, 2003.