Bigram
A bigram or digram is every sequence of two adjacent elements in a string of tokens, which are typically letters, syllables, or words; they are n-grams for n=2. The frequency distribution of bigrams in a string are commonly used for simple statistical analysis of text in many applications, including in computational linguistics, cryptography, speech recognition, and so on.
Gappy bigrams or skipping bigrams are word pairs which allow gaps (perhaps avoiding connecting words, or allowing some simulation of dependencies, as in a dependency grammar).
Head word bigrams are gappy bigrams with an explicit dependency relationship.
Bigrams help provide the conditional probability of a token given the preceding token, when the relation of the conditional probability is applied:
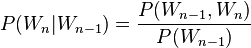
That is, the probability 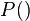 of a token
of a token  given the preceding token
given the preceding token 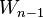 is equal to the probability of their bigram, or the co-occurrence of the two tokens
is equal to the probability of their bigram, or the co-occurrence of the two tokens 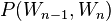 , divided by the probability of the preceding token.
, divided by the probability of the preceding token.
Applications
Bigrams are used in one of the most successful language models for speech recognition.[1] They are a special case of N-gram.
Bigram frequency attacks can be used in cryptography to solve cryptograms. See frequency analysis.
Bigram frequency is one approach to statistical language identification.
Bigram frequency in the English language
The frequency of the most common letter bigrams in a small English corpus is:[2]
th 1.52 en 0.55 ng 0.18 he 1.28 ed 0.53 of 0.16 in 0.94 to 0.52 al 0.09 er 0.94 it 0.50 de 0.09 an 0.82 ou 0.50 se 0.08 re 0.68 ea 0.47 le 0.08 nd 0.63 hi 0.46 sa 0.06 at 0.59 is 0.46 si 0.05 on 0.57 or 0.43 ar 0.04 nt 0.56 ti 0.34 ve 0.04 ha 0.56 as 0.33 ra 0.04 es 0.56 te 0.27 ld 0.02 st 0.55 et 0.19 ur 0.02
Complete bigram frequencies for a larger corpus are available.[3]
Bigram frequency in the Turkish language
The frequeny of most common letter bigrams in Turkish are illustrated below [4]
ar 0.0192 ya 0.0098 or 0.0064 la 0.0175 di 0.0093 nı 0.0063 an 0.0173 ma 0.0091 li 0.0063 er 0.0152 nd 0.0089 me 0.0062 in 0.0151 ra 0.0086 rı 0.0061 le 0.0134 al 0.0084 ta 0.0059 en 0.0132 ak 0.0079 ne 0.0058 de 0.0126 ri 0.0077 el 0.0058 ın 0.0121 il 0.0070 am 0.0058 da 0.0116 ni 0.0067 ek 0.0057 bi 0.0114 ba 0.0065 dı 0.0057 ir 0.0110 rd 0.0065 yo 0.0055 ka 0.0103 ay 0.0064 ki 0.0054
See also
References
- ↑ Michael Collins. A new statistical parser based on bigram lexical dependencies. In Proceedings of the 34th Annual Meeting of the Association of Computational Linguistics, Santa Cruz, CA. 1996. pp.184-191.
- ↑ Cornell Math Explorer's Project – Substitution Ciphers
- ↑ Jones, Michael N; D J K Mewhort (August 2004). "Case-sensitive letter and bigram frequency counts from large-scale English corpora". Behavior Research Methods, Instruments, and Computers 36 (3): 388–396. ISSN 0743-3808. PMID 15641428.
- ↑ Sefik Ilkin Serengil. Attacking Turkish Texts Encrypted by Homophonic Cipher. MSc thesis, Galatasaray University, 2011.
| ||||||||||||||||||||||||||||||||||