Bias–variance tradeoff

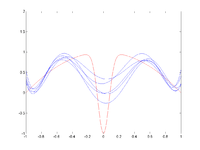


In statistics and machine learning, the bias–variance tradeoff (or dilemma) is the problem of simultaneously minimizing two sources of error that prevent supervised learning algorithms from generalizing beyond their training set:
- The bias is error from erroneous assumptions in the learning algorithm. High bias can cause an algorithm to miss the relevant relations between features and target outputs (underfitting).
- The variance is error from sensitivity to small fluctuations in the training set. High variance can cause overfitting: modeling the random noise in the training data, rather than the intended outputs.
The bias–variance decomposition is a way of analyzing a learning algorithm's expected generalization error with respect to a particular problem as a sum of three terms, the bias, variance, and a quantity called the irreducible error, resulting from noise in the problem itself.
This tradeoff applies to all forms of supervised learning: classification, regression (function fitting),[1][2] and structured output learning. It has also been invoked to explain the effectiveness of heuristics in human learning.
Motivation
The bias–variance tradeoff is a central problem in supervised learning. Ideally, one wants to choose a model that both accurately captures the regularities in its training data, but also generalizes well to unseen data. Unfortunately, it is typically impossible to do both simultaneously. High-variance learning methods may be able to represent their training set well, but are at risk of overfitting to noisy or unrepresentative training data. In contrast, algorithms with high bias typically produce simpler models that don't tend to overfit, but may underfit their training data, failing to capture important regularities.
Models with low bias are usually more complex (e.g. higher-order regression polynomials), enabling them to represent the training set more accurately. In the process, however, they may also represent a large noise component in the training set, making their predictions less accurate - despite their added complexity. In contrast, models with higher bias tend to be relatively simple (low-order or even linear regression polynomials), but may produce lower variance predictions when applied beyond the training set.
Bias–variance decomposition of squared error
Suppose that we have a training set consisting of a set of points  and real values
and real values 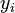 associated with each point
associated with each point  . We assume that there is a functional, but noisy relation
. We assume that there is a functional, but noisy relation 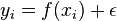 , where the noise,
, where the noise,  , has zero mean and variance
, has zero mean and variance  .
.
We want to find a function 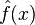 , that approximates the true function
, that approximates the true function  as well as possible, by means of some learning algorithm. We make "as well as possible" precise by measuring the mean squared error between
as well as possible, by means of some learning algorithm. We make "as well as possible" precise by measuring the mean squared error between 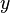 and : we want
and : we want 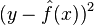 to be minimal, both for and for points outside of our sample. Of course, we cannot hope to do so perfectly, since the contain noise ; this means we must be prepared to accept an irreducible error in any function we come up with.
to be minimal, both for and for points outside of our sample. Of course, we cannot hope to do so perfectly, since the contain noise ; this means we must be prepared to accept an irreducible error in any function we come up with.
Finding an  that generalizes to points outside of the training set can be done with any of the countless algorithms used for supervised learning. It turns out that whichever function we select, we can decompose its expected error on an unseen sample
that generalizes to points outside of the training set can be done with any of the countless algorithms used for supervised learning. It turns out that whichever function we select, we can decompose its expected error on an unseen sample  as follows:[3]:34[4]:223
as follows:[3]:34[4]:223
![\begin{align}
\mathrm{E}\Big[\big(y - \hat{f}(x)\big)^2\Big]
& = \mathrm{Bias}\big[\hat{f}(x)\big]^2 + \mathrm{Var}\big[\hat{f}(x)\big] + \sigma^2 \\
\end{align}](../I/m/cbc65310d09a6efa630d8c1f33cdfa88.png)
Where:
![\begin{align}
\mathrm{Bias}\big[\hat{f}(x)\big] = \mathrm{E}\big[\hat{f}(x)\big] - f(x)
\end{align}](../I/m/d50ed92100881594dd3e3e5fe524d1d9.png)
and
![\begin{align}
\mathrm{Var}\big[\hat{f}(x)\big] = \mathrm{E}\Big[ \big( \hat{f}(x) - \mathrm{E}[\hat{f}(x)] \big)^2 \Big]
\end{align}](../I/m/6491e89f257cf71eea37182592f4cd3c.png)
The expectation ranges over different choices of the training set 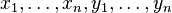 , all sampled from the same distribution. The three terms represent:
, all sampled from the same distribution. The three terms represent:
- the square of the bias of the learning method, which can be thought of the error caused by the simplifying assumptions built into the method. E.g., when approximating a non-linear function
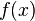 using a learning method for linear models, there will be error in the estimates due to this assumption;
using a learning method for linear models, there will be error in the estimates due to this assumption; - the variance of the learning method, or, intuitively, how much the learning method will move around its mean;
- the irreducible error . Since all three terms are non-negative, this forms a lower bound on the expected error on unseen samples.[3]:34
The more complex the model is, the more data points it will capture, and the lower the bias will be. However, complexity will make the model "move" more to capture the data points, and hence its variance will be larger.
Derivation
The derivation of the bias–variance decomposition for squared error proceeds as follows.[5][6]
For notational convenience, abbreviate 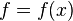 and
and 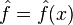 . First, note that for any random variable
. First, note that for any random variable 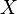 , we have
, we have
![\begin{align}
\mathrm{Var}[X] = \mathrm{E}[X^2] - \mathrm{E}[X]^2
\end{align}](../I/m/19e4929be4fb755ca4e5a36e6034e722.png)
Rearranging, we get:
![\begin{align}
\mathrm{E}[X^2] = \mathrm{Var}[X] + \mathrm{E}[X]^2
\end{align}](../I/m/3bf4cd9743a611061e28a61c4573cabc.png)
Since 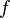 is deterministic
is deterministic
![\begin{align}
\mathrm{E}[f] = f
\end{align}](../I/m/7aae5f50f91af7aec57128a437b8cd56.png) .
.
This, given 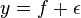 and
and ![\mathrm{E}[\epsilon] = 0](../I/m/c47c1c36b741b705b6c395908159103f.png) , implies
, implies ![\mathrm{E}[y] = \mathrm{E}[f + \epsilon] = \mathrm{E}[f] = f](../I/m/d9870e42729aa64c1218000df648bef9.png) .
.
Also, since ![\mathrm{Var}[\epsilon] = \sigma^2](../I/m/bf222ae3d929b9745f4c4726cb9999c0.png)
![\begin{align}
\mathrm{Var}[y] = \mathrm{E}[(y - \mathrm{E}[y])^2] = \mathrm{E}[(y - f)^2] = \mathrm{E}[(f + \epsilon - f)^2] = \mathrm{E}[\epsilon^2] = \mathrm{Var}[\epsilon] + \mathrm{E}[\epsilon]^2 = \sigma^2
\end{align}](../I/m/78c8b20ea90b1c9e09bf934cf88e8800.png)
Thus, since and are independent, we can write
![\begin{align}
\mathrm{E}\big[(y - \hat{f})^2\big]
& = \mathrm{E}[y^2 + \hat{f}^2 - 2 y\hat{f}] \\
& = \mathrm{E}[y^2] + \mathrm{E}[\hat{f}^2] - \mathrm{E}[2y\hat{f}] \\
& = \mathrm{Var}[y] + \mathrm{E}[y]^2 + \mathrm{Var}[\hat{f}] + \mathrm{E}[\hat{f}]^2 - 2f\mathrm{E}[\hat{f}] \\
& = \mathrm{Var}[y] + \mathrm{Var}[\hat{f}] + (f - \mathrm{E}[\hat{f}])^2 \\
& = \mathrm{Var}[y] + \mathrm{Var}[\hat{f}] + \mathrm{E}[f - \hat{f}]^2 \\
& = \sigma^2 + \mathrm{Var}[\hat{f}] + \mathrm{Bias}[\hat{f}]^2
\end{align}](../I/m/cbf82477ff088e056de49e452f74fbbf.png)
Application to classification
The bias–variance decomposition was originally formulated for least-squares regression. For the case of classification under the 0-1 loss (misclassification rate), it's possible to find a similar decomposition.[7][8] Alternatively, if the classification problem can be phrased as probabilistic classification, then the expected squared error of the predicted probabilities with respect to the true probabilities can be decomposed as before.[9]
Approaches
Dimensionality reduction and feature selection can decrease variance by simplifying models. Similarly, a larger training set tends to decrease variance. Adding features (predictors) tends to decrease bias, at the expense of introducing additional variance. Learning algorithms typically have some tunable parameters that control bias and variance, e.g.:
- (Generalized) linear models can be regularized to decrease their variance at the cost of increasing their bias [10]
- In artificial neural networks, the variance increases and the bias decreases with the number of hidden units.[1] Like in GLMs, regularization is typically applied.
- In k-nearest neighbor models, a high value of k leads to high bias and low variance (see below).
- In Instance-based learning, regularization can be achieved varying the mixture of prototypes and exemplars.[11]
- In decision trees, the depth of the tree determines the variance. Decision trees are commonly pruned to control variance.[3]:307
One way of resolving the trade-off is to use mixture models and ensemble learning.[12][13] For example, boosting combines many "weak" (high bias) models in an ensemble that has lower bias than the individual models, while bagging combines "strong" learners in a way that reduces their variance.
K-nearest neighbors
In the case of k-nearest neighbors regression, a closed-form expression exists that relates the bias–variance decomposition to the parameter k:[4]:37, 223
![\mathrm{E}[(y - \hat{f}(x))^2] = \left( f(x) - \frac{1}{k}\sum_{i=1}^k f(N_i(x)) \right)^2 + \frac{\sigma^2}{k} + \sigma^2](../I/m/e5c96479ed6e85f8e451fd2790879d26.png)
where 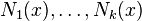 are the k nearest neighbors of x in the training set. The bias (first term) is a monotone rising function of k, while the variance (second term) drops off as k is increased. In fact, under "reasonable assumptions" the bias of the first-nearest neighbor (1-NN) estimator vanishes entirely as the size of the training set approaches infinity.[1]
are the k nearest neighbors of x in the training set. The bias (first term) is a monotone rising function of k, while the variance (second term) drops off as k is increased. In fact, under "reasonable assumptions" the bias of the first-nearest neighbor (1-NN) estimator vanishes entirely as the size of the training set approaches infinity.[1]
Application to human learning
While widely discussed in the context of machine learning, the bias-variance dilemma has been examined in the context of human cognition, most notably by Gerd Gigerenzer and co-workers in the context of learned heuristics. They have argued (see references below) that the human brain resolves the dilemma in the case of the typically sparse, poorly-characterised training-sets provided by experience by adopting high-bias/low variance heuristics. This reflects the fact that a zero-bias approach has poor generalisability to new situations, and also unreasonably presumes precise knowledge of the true state of the world. The resulting heuristics are relatively simple, but produce better inferences in a wider variety of situations.[14]
Geman et al.[1] argue that the bias-variance dilemma implies that abilities such as generic object recognition cannot be learned from scratch, but require a certain degree of “hard wiring” that is later tuned by experience. This is because model-free approaches to inference require impractically large training sets if they are to avoid high variance.
See also
References
- 1 2 3 4 Geman, Stuart; E. Bienenstock; R. Doursat (1992). "Neural networks and the bias/variance dilemma" (PDF). Neural Computation 4: 1–58. doi:10.1162/neco.1992.4.1.1.
- ↑ Bias–variance decomposition, In Encyclopedia of Machine Learning. Eds. Claude Sammut, Geoffrey I. Webb. Springer 2011. pp. 100-101
- 1 2 3 Gareth James; Daniela Witten; Trevor Hastie; Robert Tibshirani (2013). An Introduction to Statistical Learning. Springer.
- 1 2 Hastie, Trevor; Tibshirani, Robert; Friedman, Jerome (2009). The Elements of Statistical Learning.
- ↑ Vijayakumar, Sethu (2007). "The Bias–Variance Tradeoff" (PDF). University Edinburgh. Retrieved 19 August 2014.
- ↑ Shakhnarovich, Greg (2011). "Notes on derivation of bias-variance decomposition in linear regression" (PDF). Archived from the original (PDF) on 21 August 2014. Retrieved 20 August 2014.
- ↑ Domingos, Pedro (2000). A unified bias-variance decomposition (PDF). ICML.
- ↑ Valentini, Giorgio; Dietterich, Thomas G. (2004). "Bias–variance analysis of support vector machines for the development of SVM-based ensemble methods". JMLR 5: 725–775.
- ↑ Manning, Christopher D.; Raghavan, Prabhakar; Schütze, Hinrich (2008). Introduction to Information Retrieval. Cambridge University Press. pp. 308–314.
- ↑ Belsley, David (1991). Conditioning diagnostics : collinearity and weak data in regression. New York: Wiley. ISBN 978-0471528890.
- ↑ Gagliardi, F (2011). "Instance-based classifiers applied to medical databases: diagnosis and knowledge extraction". Artificial Intelligence in Medicine 52 (3): 123–139. doi:10.1016/j.artmed.2011.04.002.
- ↑ Jo-Anne Ting, Sethu Vijaykumar, Stefan Schaal, Locally Weighted Regression for Control. In Encyclopedia of Machine Learning. Eds. Claude Sammut, Geoffrey I. Webb. Springer 2011. p. 615
- ↑ Scott Fortmann-Roe. Understanding the Bias–Variance Tradeoff. 2012. http://scott.fortmann-roe.com/docs/BiasVariance.html
- ↑ Gigerenzer, Gerd; Brighton, Henry (2009). "Homo Heuristicus: Why Biased Minds Make Better Inferences". Topics in Cognitive Science 1: 107–143. doi:10.1111/j.1756-8765.2008.01006.x. PMID 25164802.
External links
- Fortmann-Roe, Scott (June 2012). "Understanding the Bias-Variance Tradeoff".