Bayesian programming
| Part of a series on Statistics |
| Probability theory |
|---|
 |
Bayesian programming is a formalism and a methodology to specify probabilistic models and solve problems when less than the necessary information is available.
Edwin T. Jaynes proposed that probability could be considered as an alternative and an extension of logic for rational reasoning with incomplete and uncertain information. In his founding book Probability Theory: The Logic of Science[1] he developed this theory and proposed what he called “the robot,” which was not a physical device, but an inference engine to automate probabilistic reasoning—a kind of Prolog for probability instead of logic. Bayesian programming[2] is a formal and concrete implementation of this "robot".
Bayesian programming may also be seen as an algebraic formalism to specify graphical models such as, for instance, Bayesian networks, dynamic Bayesian networks, Kalman filters or hidden Markov models. Indeed, Bayesian Programming is more general than Bayesian networks and has a power of expression equivalent to probabilistic factor graphs.
Formalism
A Bayesian program is a means of specifying a family of probability distributions.
The constituent elements of a Bayesian program are presented below:

- A program is constructed from a description and a question.
- A description is constructed using some specification (
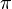 ) as given by the programmer and an identification or learning process for the parameters not completely specified by the specification, using a data set (
) as given by the programmer and an identification or learning process for the parameters not completely specified by the specification, using a data set (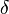 ).
). - A specification is constructed from a set of pertinent variables, a decomposition and a set of forms.
- Forms are either parametric forms or questions to other Bayesian programs.
- A question specifies which probability distribution has to be computed.
Description
The purpose of a description is to specify an effective method of computing a joint probability distribution
on a set of variables 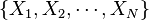 given a set of experimental data and some
specification . This joint distribution is denoted as:
given a set of experimental data and some
specification . This joint distribution is denoted as:  .
.
To specify preliminary knowledge , the programmer must undertake the following:
- Define the set of relevant variables on which the joint distribution is defined.
- Decompose the joint distribution (break it into relevant independent or conditional probabilities).
- Define the forms of each of the distributions (e.g., for each variable, one of the list of probability distributions).
Decomposition
Given a partition 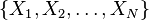 containing
containing 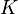 subsets, variables are defined
subsets, variables are defined
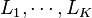 , each corresponding to one of these subsets.
Each variable
, each corresponding to one of these subsets.
Each variable  is obtained as the conjunction of the variables
is obtained as the conjunction of the variables 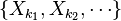 belonging to the
belonging to the 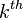 subset. Recursive application of Bayes' theorem leads to:
subset. Recursive application of Bayes' theorem leads to:
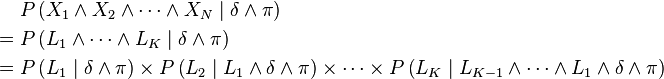
Conditional independence hypotheses then allow further simplifications. A conditional
independence hypothesis for variable is defined by choosing some variable 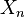 among the variables appearing in the conjunction
among the variables appearing in the conjunction 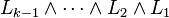 , labelling
, labelling 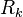 as the
conjunction of these chosen variables and setting:
as the
conjunction of these chosen variables and setting:
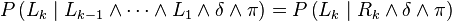
We then obtain:
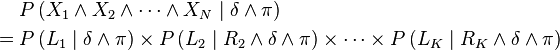
Such a simplification of the joint distribution as a product of simpler distributions is called a decomposition, derived using the chain rule.
This ensures that each variable appears at the most once on the left of a conditioning bar, which is the necessary and sufficient condition to write mathematically valid decompositions.
Forms
Each distribution  appearing in the product is then associated
with either a parametric form (i.e., a function
appearing in the product is then associated
with either a parametric form (i.e., a function  ) or a question to another Bayesian program
) or a question to another Bayesian program 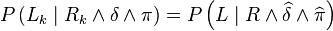 .
.
When it is a form , in general, 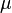 is a vector of parameters that may depend on or or both. Learning
takes place when some of these parameters are computed using the data set .
is a vector of parameters that may depend on or or both. Learning
takes place when some of these parameters are computed using the data set .
An important feature of Bayesian Programming is this capacity to use questions to other Bayesian programs as components of the definition of a new Bayesian program. is obtained by some inferences done by another Bayesian program defined by the specifications 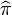 and the data
and the data 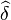 . This is similar to calling a subroutine in classical programming and provides an easy way to build hierarchical models.
. This is similar to calling a subroutine in classical programming and provides an easy way to build hierarchical models.
Question
Given a description (i.e., ), a question is obtained by partitioning
into three sets: the searched variables, the known variables and
the free variables.
The 3 variables 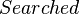 ,
, 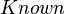 and
and  are defined as the
conjunction of the variables belonging to
these sets.
are defined as the
conjunction of the variables belonging to
these sets.
A question is defined as the set of distributions:
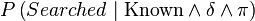
made of many "instantiated questions" as the cardinal of ,
each instantiated question being the distribution:
Inference
Given the joint distribution , it is always possible to compute any possible question using the following general inference:
![\begin{align}
& P\left(\text{Searched}\mid\text{Known}\wedge\delta\wedge\pi\right)\\
={} & \sum_\text{Free}\left[P\left( \text{Searched} \wedge \text{Free} \mid \text{Known}\wedge\delta\wedge\pi\right)\right]\\
={} & \frac{\displaystyle \sum_\text{Free}\left[P\left(\text{Searched}\wedge \text{Free}\wedge \text{Known}\mid\delta\wedge\pi\right)\right]}{\displaystyle P\left(\text{Known}\mid\delta\wedge\pi\right)}\\
={} & \frac{\displaystyle \sum_\text{Free}\left[P\left(\text{Searched}\wedge \text{Free}\wedge \text{Known}\mid\delta\wedge\pi\right)\right]}{\displaystyle \sum_{\text{Free}\wedge \text{Searched}} \left[P\left(\text{Searched} \wedge \text{Free} \wedge \text{Known}\mid\delta\wedge\pi\right)\right]}\\
={} & \frac{1}{Z}\times\sum_\text{Free}\left[P\left(\text{Searched}\wedge \text{Free} \wedge \text{Known} \mid \delta\wedge\pi\right)\right]\end{align}](../I/m/206973ba087d9040edd44c1d574d35ea.png)
where the first equality results from the marginalization rule, the second
results from Bayes' theorem and the third corresponds to a second application of marginalization. The denominator appears to be a normalization term and can be replaced by a constant 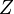 .
.
Theoretically, this allows to solve any Bayesian inference problem. In practice,
however, the cost of computing exhaustively and exactly 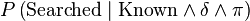 is too great in almost all cases.
is too great in almost all cases.
Replacing the joint distribution by its decomposition we get:
![\begin{align}
& P\left(\text{Searched}\mid \text{Known}\wedge\delta\wedge\pi\right)\\
= {}& \frac{1}{Z} \sum_\text{Free} \left[\prod_{k=1}^K \left[ P\left( L_{i}\mid K_{i} \wedge \pi \right)\right]\right]
\end{align}](../I/m/1a89efe553e223d4593199a5146733ab.png)
which is usually a much simpler expression to compute, as the dimensionality of the problem is considerably reduced by the decomposition into a product of lower dimension distributions.
Example
Bayesian spam detection
The purpose of Bayesian spam filtering is to eliminate junk e-mails.
The problem is very easy to formulate. E-mails should be classified into one of two categories: non-spam or spam. The only available information to classify the e-mails is their content: a set of words. Using these words without taking the order into account is commonly called a bag of words model.
The classifier should furthermore be able to adapt to its user and to learn from experience. Starting from an initial standard setting, the classifier should modify its internal parameters when the user disagrees with its own decision. It will hence adapt to the user’s criteria to differentiate between non-spam and spam. It will improve its results as it encounters increasingly classified e-mails.
Variables
The variables necessary to write this program are as follows:
-
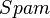 : a binary variable, false if the e-mail is not spam and true otherwise.
: a binary variable, false if the e-mail is not spam and true otherwise. -
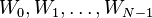 :
: 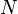 binary variables.
binary variables.  is true if the
is true if the 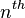 word of the dictionary is present in the text.
word of the dictionary is present in the text.
These  binary variables sum up all the information
about an e-mail.
binary variables sum up all the information
about an e-mail.
Decomposition
Starting from the joint distribution and applying recursively Bayes' theorem we obtain:
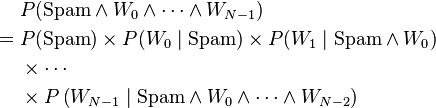
This is an exact mathematical expression.
It can be drastically simplified by assuming that the probability of appearance of a word knowing the nature of the text (spam or not) is independent of the appearance of the other words. This is the naive Bayes assumption and this makes this spam filter a naive Bayes model.
For instance, the programmer can assume that:

to finally obtain:
![P(\text{Spam} \land W_0 \land \ldots
\land W_{N-1}) = P(\text{Spam})\prod_{n=0}^{N-1}[P(W_n\mid\text{Spam})]](../I/m/edcd23c81f1dd2c969c0c7ea97e975ea.png)
This kind of assumption is known as the naive Bayes' assumption. It is "naive" in the sense that the independence between words is clearly not completely true. For instance, it completely neglects that the appearance of pairs of words may be more significant than isolated appearances. However, the programmer may assume this hypothesis and may develop the model and the associated inferences to test how reliable and efficient it is.
Parametric forms
To be able to compute the joint distribution, the programmer must now specify the
distributions appearing in the decomposition:
-
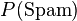 is a prior defined, for instance, by
is a prior defined, for instance, by ![P([\text{Spam}=1]) = 0.75](../I/m/87d3f6ea18041f9bd69eb1efc5168381.png)
- Each of the forms
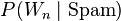 may be specified using Laplace rule of succession (this is a pseudocounts-based smoothing technique to counter the zero-frequency problem of words never-seen-before):
may be specified using Laplace rule of succession (this is a pseudocounts-based smoothing technique to counter the zero-frequency problem of words never-seen-before):
-
![P(W_n\mid[\text{Spam}=\text{false}])=\frac{1+a^n_f}{2+a_f}](../I/m/404e105066632ab56f1bf67ac3c593f4.png)
![P(W_n\mid[\text{Spam}=\text{true}])=\frac{1+a^n_t}{2+a_t}](../I/m/3897bb2859a8c1db28b5031121bdafe3.png)
where 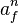 stands for the number of appearances of the word in non-spam e-mails and
stands for the number of appearances of the word in non-spam e-mails and  stands for the total number of non-spam e-mails. Similarly,
stands for the total number of non-spam e-mails. Similarly, 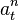 stands for the number of appearances of the word in spam e-mails and
stands for the number of appearances of the word in spam e-mails and  stands for the total number of spam e-mails.
stands for the total number of spam e-mails.
Identification
The forms are not yet completely specified because the 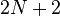 parameters
parameters  ,
, 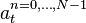 , and have no values yet.
, and have no values yet.
The identification of these parameters could be done either by batch processing a series of classified e-mails or by an incremental updating of the parameters using the user's classifications of the e-mails as they arrive.
Both methods could be combined: the system could start with initial standard values of these parameters issued from a generic database, then some incremental learning customizes the classifier to each individual user.
Question
The question asked to the program is: "what is the probability for a given text to be spam knowing which words appear and don't appear in this text?" It can be formalized by:
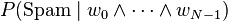
which can be computed as follows:
![\begin{align}
& P(\text{Spam}\mid w_{0}\wedge\cdots\wedge w_{N-1} )\\
={} & \frac{\displaystyle P(\text{Spam}) \prod_{n=0}^{N-1} [ P(w_{n}\mid\text{Spam})]}{\displaystyle \sum_\text{Spam} [P(\text{Spam}) \prod_{n=0}^{N-1} [P (w_{n}\mid\text{Spam})]]}\end{align}](../I/m/0ed462ea97dae4979dd6a5f2673337ca.png)
The denominator appears to be a normalization constant. It is not necessary to compute it to decide if we are dealing with spam. For instance, an easy trick is to compute the ratio:
![\begin{align}
& \frac{P([\text{Spam}=\text{true}]\mid w_0\wedge\cdots\wedge w_{N-1})}{P([ \text{Spam} = \text{false} ]\mid w_0 \wedge\cdots\wedge w_{N-1})}\\
={} & \frac{P([ \text{Spam}=\text{true} ] )}{P([ \text{Spam} =\text{false} ])}\times\prod_{n=0}^{N-1} \left[\frac{P(w_n\mid [\text{Spam}=\text{true}])}{P(w_n\mid [\text{Spam} = \text{false}])}\right] \end{align}](../I/m/fbd9d2bab56ba53fb33cf58cd5321133.png)
This computation is faster and easier because it requires only  products.
products.
Bayesian program
The Bayesian spam filter program is completely defined by:
![\Pr
\begin{cases}
Ds
\begin{cases}
Sp (\pi)
\begin{cases}
Va: \text{Spam},W_0,W_1 \ldots W_{N-1} \\
Dc:
\begin{cases}
P(\text{Spam} \land W_0 \land \ldots \land W_n \land \ldots \land W_{N-1})\\
= P(\text{Spam})\prod_{n=0}^{N-1}P(W_n\mid\text{Spam})
\end{cases}\\
Fo:
\begin{cases}
P(\text{Spam}):
\begin{cases}
P([\text{Spam}=\text{false}])=0.25 \\
P([\text{Spam}=\text{true}])=0.75
\end{cases}\\
P(W_n\mid\text{Spam}):
\begin{cases}
P(W_n\mid[\text{Spam}=\text{false}])\\
=\frac{1+a^n_f}{2+a_f} \\
P(W_n\mid[\text{Spam}=\text{true}])\\
=\frac{1+a^n_t}{2+a_t}
\end{cases} \\
\end{cases}\\
\end{cases}\\
\text{Identification (based on }\delta)
\end{cases}\\
Qu: P(\text{Spam}\mid w_0 \land \ldots \land w_n \land \ldots \land w_{N-1})
\end{cases}](../I/m/ab3c964163a1dce163ff753181e75080.png)
Bayesian filter, Kalman filter and hidden Markov model
Bayesian filters (often called Recursive Bayesian estimation) are generic probabilistic models for time evolving processes. Numerous models are particular instances of this generic approach, for instance: the Kalman filter or the Hidden Markov model (HMM).
Variables
- Variables
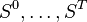 are a time series of state variables considered to be on a time horizon ranging from
are a time series of state variables considered to be on a time horizon ranging from  to
to  .
. - Variables
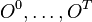 are a time series of observation variables on the same horizon.
are a time series of observation variables on the same horizon.
Decomposition
The decomposition is based:
- on
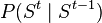 , called the system model, transition model or dynamic model, which formalizes the transition from the state at time
, called the system model, transition model or dynamic model, which formalizes the transition from the state at time  to the state at time
to the state at time  ;
; - on
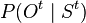 , called the observation model, which expresses what can be observed at time when the system is in state
, called the observation model, which expresses what can be observed at time when the system is in state 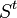 ;
; - on an initial state at time :
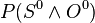 .
.
Parametrical forms
The parametrical forms are not constrained and different choices lead to different well-known models: see Kalman filters and Hidden Markov models just below.
Question
The typical question for such models is 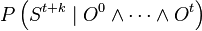 : what is the probability distribution for the state at time
: what is the probability distribution for the state at time 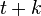 knowing the observations from instant to ?
knowing the observations from instant to ?
The most common case is Bayesian filtering where 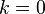 , which searches for the present state, knowing past observations.
, which searches for the present state, knowing past observations.
However it is also possible 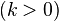 , to extrapolate a future state from past observations, or to do smoothing
, to extrapolate a future state from past observations, or to do smoothing  , to recover a past state from observations made either before or after that instant.
, to recover a past state from observations made either before or after that instant.
More complicated questions may also be asked as shown below in the HMM section.
Bayesian filters 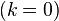 have a very interesting recursive property, which contributes greatly to their attractiveness.
have a very interesting recursive property, which contributes greatly to their attractiveness.  may be computed simply from
may be computed simply from 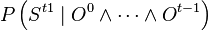 with the following formula:
with the following formula:
![\begin{array}{ll}
& P\left(S^{t}|O^{0}\wedge\cdots\wedge O^{t}\right)\\
= & P\left(O^{t}|S^{t}\right)\times\sum_{S^{t-1}}\left[P\left(S^{t}|S^{t-1}\right)\times P\left(S^{t-1}|O^{0}\wedge\cdots\wedge O^{t-1}\right)\right]\end{array}](../I/m/a0125a2f3a90f2bbad2c643d058ba94b.png)
Another interesting point of view for this equation is to consider that there are two phases: a prediction phase and an estimation phase:
- During the prediction phase, the state is predicted using the dynamic model and the estimation of the state at the previous moment:
![\begin{array}{ll}
& P\left(S^{t}|O^{0}\wedge\cdots\wedge O^{t-1}\right)\\
= & \sum_{S^{t-1}}\left[P\left(S^{t}|S^{t-1}\right)\times P\left(S^{t-1}|O^{0}\wedge\cdots\wedge O^{t-1}\right)\right]\end{array}](../I/m/69f577703f7b5c7edcb106a6466ae917.png)
- During the estimation phase, the prediction is either confirmed or invalidated using the last observation:
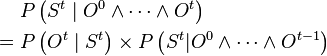
Bayesian program
![Pr\begin{cases}
Ds\begin{cases}
Sp(\pi)\begin{cases}
Va:\\
S^{0},\cdots,S^{T},O^{0},\cdots,O^{T}\\
Dc:\\
\begin{cases}
& P\left(S^{0}\wedge\cdots\wedge S^{T}\wedge O^{0}\wedge\cdots\wedge O^{T}|\pi\right)\\
= & P\left(S^{0}\wedge O^{0}\right)\times\prod_{t=1}^{T}\left[P\left(S^{t}|S^{t-1}\right)\times P\left(O^{t}|S^{t}\right)\right]\end{cases}\\
Fo:\\
\begin{cases}
P\left(S^{0}\wedge O^{0}\right)\\
P\left(S^{t}|S^{t-1}\right)\\
P\left(O^{t}|S^{t}\right)\end{cases}\end{cases}\\
Id\end{cases}\\
Qu:\\
\begin{cases}
\begin{array}{l}
P\left(S^{t+k}|O^{0}\wedge\cdots\wedge O^{t}\right)\\
\left(k=0\right)\equiv \text{Filtering} \\
\left(k>0\right)\equiv \text{Prediction} \\
\left(k<0\right)\equiv \text{Smoothing} \end{array}\end{cases}\end{cases}](../I/m/71b8390e1a83bbff40cf027c1d96f4e5.png)
Kalman filter
The very well-known Kalman filters[3] are a special case of Bayesian filters.
They are defined by the following Bayesian program:
![Pr\begin{cases}
Ds\begin{cases}
Sp(\pi)\begin{cases}
Va:\\
S^{0},\cdots,S^{T},O^{0},\cdots,O^{T}\\
Dc:\\
\begin{cases}
& P\left(S^{0}\wedge\cdots\wedge O^{T}|\pi\right)\\
= & \left[\begin{array}{c}
P\left(S^{0}\wedge O^{0}|\pi\right)\\
\prod_{t=1}^{T}\left[P\left(S^{t}|S^{t-1}\wedge\pi\right)\times P\left(O^{t}|S^{t}\wedge\pi\right)\right]\end{array}\right]\end{cases}\\
Fo:\\
\begin{cases}
P\left(S^t \mid S^{t-1}\wedge\pi\right)\equiv G\left(S^{t},A\bullet S^{t-1},Q\right)\\
P\left(O^t \mid S^t \wedge\pi\right)\equiv G\left(O^{t},H\bullet S^{t},R\right)\end{cases}\end{cases}\\
Id\end{cases}\\
Qu:\\
P\left(S^T \mid O^0 \wedge\cdots\wedge O^{T}\wedge\pi\right)\end{cases}](../I/m/8e6a42c75c8c52492d74dfcb0a0073c4.png)
- Variables are continuous.
- The transition model
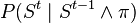 and the observation model
and the observation model  are both specified using Gaussian laws with means that are linear functions of the conditioning variables.
are both specified using Gaussian laws with means that are linear functions of the conditioning variables.
With these hypotheses and by using the recursive formula, it is possible to solve
the inference problem analytically to answer the usual 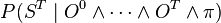 question.
This leads to an extremely efficient algorithm, which explains the popularity of Kalman filters and the number of their everyday applications.
question.
This leads to an extremely efficient algorithm, which explains the popularity of Kalman filters and the number of their everyday applications.
When there are no obvious linear transition and observation models, it is still often possible, using a first-order Taylor's expansion, to treat these models as locally linear. This generalization is commonly called the extended Kalman filter.
Hidden Markov model
Hidden Markov models (HMMs) are another very popular specialization of Bayesian filters.
They are defined by the following Bayesian program:
![\Pr\begin{cases}
Ds\begin{cases}
Sp(\pi)\begin{cases}
Va:\\
S^{0},\ldots,S^{T},O^{0},\ldots,O^{T}\\
Dc:\\
\begin{cases}
& P\left(S^{0}\wedge\cdots\wedge O^{T}\mid\pi\right)\\
= & \left[\begin{array}{c}
P\left(S^{0}\wedge O^{0}\mid\pi\right)\\
\prod_{t=1}^{T}\left[P\left(S^{t}\mid S^{t-1}\wedge\pi\right)\times P\left(O^{t}\mid S^{t}\wedge\pi\right)\right]\end{array}\right]\end{cases}\\
Fo:\\
\begin{cases}
P\left(S^{0}\wedge O^{0}\mid\pi\right)\equiv \text{Matrix}\\
P\left(S^{t}\mid S^{t-1}\wedge\pi\right)\equiv \text{Matrix}\\
P\left(O^{t}\mid S^{t}\wedge\pi\right)\equiv \text{Matrix}\end{cases}\end{cases}\\
Id\end{cases}\\
Qu:\\
\max_{S^{1}\wedge\cdots\wedge S^{T-1}}\left[P\left(S^{1}\wedge\cdots\wedge S^{T-1}\mid S^{T}\wedge O^{0}\wedge\cdots\wedge O^{T}\wedge\pi\right)\right]\end{cases}](../I/m/21f1b4269390e57db9b285f2b2dab244.png)
- Variables are treated as being discrete.
- The transition model
 and the observation model
and the observation model  are
are
both specified using probability matrices.
- The question most frequently asked of HMMs is:
![\max_{S^{1}\wedge\cdots\wedge S^{T-1}}\left[P\left(S^{1}\wedge\cdots\wedge S^{T-1}\mid S^{T}\wedge O^{0}\wedge\cdots\wedge O^{T}\wedge\pi\right)\right]](../I/m/aa590d39cccb76a7b3b0a6c066501cca.png)
What is the most probable series of states that leads to the present state, knowing the past observations?
This particular question may be answered with a specific and very efficient algorithm called the Viterbi algorithm.
The Baum–Welch algorithm has been developed for HMMs.
Applications
Academic applications
Since 2000, Bayesian programming has been used to develop both robotics applications and life sciences models.[4]
Robotics
In robotics, bayesian programming was applied to autonomous robotics,[5][6][7][8][9] robotic CAD systems,[10] advanced driver assistance systems,[11] robotic arm control, mobile robotics,[12][13] human-robot interaction,[14] human-vehicle interaction (Bayesian autonomous driver models)[15][16][17][18][19][20] video game avatar programming and training [21] and real-time strategy games (AI).[22]
Life sciences
In life sciences, bayesian brogramming was used in vision to reconstruct shape from motion,[23] to model visuo-vestibular interaction[24] and to study saccadic eye movements;[25] in speech perception and control to study early speech acquisition[26] and the emergence of articulatory-acoustic systems;[27] and to model handwriting perception and control.[28]
Pattern recognition
Bayesian program learning has potential applications voice recognition and synthesis, image recognition and natural language processing. It employs the principles of compositionality (building abstract representations from parts), causality (building complexity from parts) and learning to learn (using previously recognized concepts to ease the creation of new concepts).[29]
Possibility theories
The comparison between probabilistic approaches (not only bayesian programming) and possibility theories continues to be debated.
Possibility theories like, for instance, fuzzy sets,[30] fuzzy logic[31] and possibility theory[32] are alternatives to probability to model uncertainty. They argue that probability is insufficient or inconvenient to model certain aspects of incomplete/uncertain knowledge.
The defense of probability is mainly based on Cox's theorem, which starts from four postulates concerning rational reasoning in the presence of uncertainty. It demonstrates that the only mathematical framework that satisfies these postulates is probability theory. The argument is that any approach other than probability necessarily infringes one of these postulates and the value of that infringement.
Probabilistic programming
The purpose of probabilistic programming is to unify the scope of classical programming languages with probabilistic modeling (especially bayesian networks) to deal with uncertainty while profiting from the programming languages' expressiveness to encode complexity.
Extended classical programming languages include logical languages as proposed in Probabilistic Horn Abduction,[33] Independent Choice Logic,[34] PRISM,[35] and ProbLog which proposes an extension of Prolog.
It can also be extensions of functional programming languages (essentially Lisp and Scheme) such as IBAL or CHURCH. The underlying programming languages can be object-oriented as in BLOG and FACTORIE or more standard ones as in CES and FIGARO.[36]
The purpose of Bayesian programming is different. Jaynes' precept of "probability as logic" argues that probability is an extension of and an alternative to logic above which a complete theory of rationality, computation and programming can be rebuilt.[1] Bayesian programming attempts to replace classical languages with a programming approach based on probability that considers incompleteness and uncertainty.
The precise comparison between the semantics and power of expression of Bayesian and probabilistic programming is an open question.
See also
- Bayes' rule
- Bayesian inference
- Bayesian probability
- Bayesian spam filtering
- Belief propagation
- Cox's theorem
- Expectation-maximization algorithm
- Factor graph
- Graphical model
- Hidden Markov model
- Judea Pearl
- Kalman filter
- Naive Bayes classifier
- Pierre-Simon de Laplace
- Probabilistic logic
- Probabilistic programming language
- Subjective logic
References
- 1 2 Jaynes, E. T. (10 April 2003). Probability Theory: The Logic of Science. Cambridge University Press. ISBN 978-1-139-43516-1.
- ↑ Bessiere, Pierre; Mazer, Emmanuel; Manuel Ahuactzin, Juan; Mekhnacha, Kamel (20 December 2013). Bayesian Programming. CRC Press. ISBN 978-1-4398-8032-6.
- ↑ Kalman, R. E. (1960). "A New Approach to Linear Filtering and Prediction Problems". Transactions of the ASME--Journal of Basic Engineering 82: 33––45. doi:10.1115/1.3662552.
- ↑ Probabilistic Reasoning and Decision Making in Sensory-Motor Systems. Springer Science & Business Media. 15 May 2008. ISBN 978-3-540-79006-8.
|first1=missing|last1=in Authors list (help);|first2=missing|last2=in Authors list (help);|first3=missing|last3=in Authors list (help) - ↑ Lebeltel, O.; Bessière, P.; Diard, J.; Mazer, E. (2004). "Bayesian Robot Programming". Advanced Robotics 16 (1): 49––79. doi:10.1023/b:auro.0000008671.38949.43.
- ↑ Diard, J.; Gilet, E.; Simonin, E.; Bessière, P. (2010). "Incremental learning of Bayesian sensorimotor models: from low-level behaviours to large-scale structure of the environment". Connection Science 22 (4): 291––312. doi:10.1080/09540091003682561.
- ↑ Pradalier, C.; Hermosillo, J.; Koike, C.; Braillon, C.; Bessière, P.; Laugier, C. (2005). "The CyCab: a car-like robot navigating autonomously and safely among pedestrians". Robotics and Autonomous Systems 50 (1): 51––68. doi:10.1016/j.robot.2004.10.002.
- ↑ Ferreira, J.; Lobo, J.; Bessière, P.; Castelo-Branco, M.; Dias, J. (2012). "A Bayesian Framework for Active Artificial Perception". IEEE Transactions on Systems, IEEE Transactions on Systems, Man, and Cybernetics, Part B 99: 1––13.
- ↑ Ferreira, J. F.; Dias, J. M. (2014). Probabilistic Approaches to Robotic Perception. Springer.
- ↑ Mekhnacha, K.; Mazer, E.; Bessière, P. (2001). "The design and implementation of a Bayesian CAD modeler for robotic applications". Advanced Robotics 15 (1): 45––69. doi:10.1163/156855301750095578.
- ↑ Coué, C.; Pradalier, C.; Laugier, C.; Fraichard, T.; Bessière, P. (2006). "Bayesian Occupancy Filtering for Multitarget Tracking: an Automotive Application". International Journal of Robotics Research 25 (1): 19––30. doi:10.1177/0278364906061158.
- ↑ Vasudevan, S.; Siegwart, R. (2008). "Bayesian space conceptualization and place classification for semantic maps in mobile robotics". Robotics and Autonomous Systems 56 (6): 522––537. doi:10.1016/j.robot.2008.03.005.
- ↑ Perrin, X.; Chavarriaga, R.; Colas, F.; Seigwart, R.; Millan, J. (2010). "Brain-coupled interaction for semi-autonomous navigation of an assistive robot". Robotics and Autonomous Systems 58 (12): 1246––1255. doi:10.1016/j.robot.2010.05.010.
- ↑ Rett, J.; Dias, J.; Ahuactzin, J-M. (2010). "Bayesian reasoning for Laban Movement Analysis used in human-machine interaction". Int. J. of Reasoning-based Intelligent Systems 2 (1): 13––35. doi:10.1504/IJRIS.2010.029812.
- ↑ Möbus, C.; Eilers, M.; Garbe, H.; Zilinski, M. (2009), "Probabilistic and Empirical Grounded Modeling of Agents in (Partial) Cooperative Traffic Scenarios", in Duffy, Vincent G., Digital Human Modeling, Lecture Notes in Computer Science, Volume 5620, Second International Conference, ICDHM 2009, San Diego, CA, USA: Springer, pp. 423–432, doi:10.1007/978-3-642-02809-0_45, ISBN 978-3-642-02808-3
- ↑ Möbus, C.; Eilers, M. (2009), "Further Steps Towards Driver Modeling according to the Bayesian Programming Approach", in Duffy, Vincent G., Digital Human Modeling, Lecture Notes in Computer Science, Volume 5620, Second International Conference, ICDHM 2009, San Diego, CA, USA: Springer, pp. 413–422, doi:10.1007/978-3-642-02809-0_44, ISBN 978-3-642-02808-3
- ↑ Eilers, M.; Möbus, C. (2010). "Lernen eines modularen Bayesian Autonomous Driver Mixture-of-Behaviors (BAD MoB) Modells" (PDF). In Kolrep, H.; Jürgensohn, Th. Fahrermodellierung - Zwischen kinematischen Menschmodellen und dynamisch-kognitiven Verhaltensmodellen. Fortschrittsbericht des VDI in der Reihe 22 (Mensch-Maschine-Systeme). Düsseldorf, Germany: VDI-Verlag. pp. 61–74. ISBN 978-3-18-303222-8.
- ↑ Möbus, C.; Eilers, M. (2011). "Prototyping Smart Assistance with Bayesian Autonomous Driver Models". In Mastrogiovanni, F.; Chong, N.-Y. Handbook of Research on Ambient Intelligence and Smart Environments: Trends and Perspectives. Hershey, Pennsylvania (USA): IGI Global publications. pp. 460–512. doi:10.4018/978-1-61692-857-5.ch023. ISBN 9781616928575.
- ↑ Eilers, M.; Möbus, C. (2011). "Learning the Relevant Percepts of Modular Hierarchical Bayesian Driver Models Using a Bayesian Information Criterion". In Duffy, V.G. Digital Human Modeling. LNCS 6777. Heidelberg, Germany: Springer. pp. 463–472. doi:10.1007/978-3-642-21799-9_52. ISBN 978-3-642-21798-2.
- ↑ Eilers, M.; Möbus, C. (2011). "Learning of a Bayesian Autonomous Driver Mixture-of-Behaviors (BAD-MoB) Model". In Duffy, V.G. Advances in Applied Digital Human Modeling. LNCS 6777. Boca Raton, USA: CRC Press, Taylor & Francis Group. pp. 436–445. ISBN 978-1-4398-3511-1.
- ↑ Le Hy, R.; Arrigoni, A.; Bessière, P.; Lebetel, O. (2004). "Teaching Bayesian Behaviours to Video Game Characters". Robotics and Autonomous Systems 47 (2–3): 177––185. doi:10.1016/j.robot.2004.03.012.
- ↑ Synnaeve, G. (2012). Bayesian Programming and Learning for Multiplayer Video Games (PDF).
- ↑ Colas, F.; Droulez, J.; Wexler, M.; Bessière, P. (2008). "A unified probabilistic model of the perception of three-dimensional structure from optic flow". Biological Cybernetics: 132––154.
- ↑ Laurens, J.; Droulez, J. (2007). "Bayesian processing of vestibular information". Biological Cybernetics 96 (4): 389––404. doi:10.1007/s00422-006-0133-1.
- ↑ Colas, F.; Flacher, F.; Tanner, T.; Bessière, P.; Girard, B. (2009). "Bayesian models of eye movement selection with retinotopic maps". Biological Cybernetics 100 (3): 203––214. doi:10.1007/s00422-009-0292-y.
- ↑ Serkhane, J.; Schwartz, J-L.; Bessière, P. (2005). "Building a talking baby robot A contribution to the study of speech acquisition and evolution". Interaction Studies 6 (2): 253––286. doi:10.1075/is.6.2.06ser.
- ↑ Moulin-Frier, C.; Laurent, R.; Bessière, P.; Schwartz, J-L.; Diard, J. (2012). "Adverse conditions improve distinguishability of auditory, motor and percep-tuo-motor theories of speech perception: an exploratory Bayesian modeling study". Language and Cognitive Processes 27 (7–8): 1240––1263. doi:10.1080/01690965.2011.645313.
- ↑ Gilet, E.; Diard, J.; Bessière, P. (2011). Sporns, Olaf, ed. "Bayesian Action–Perception Computational Model: Interaction of Production and Recognition of Cursive Letters". PLOS ONE 6 (6): e20387. Bibcode:2011PLoSO...620387G. doi:10.1371/journal.pone.0020387.
- ↑ "New algorithm helps machines learn as quickly as humans". www.gizmag.com. 2016-01-22. Retrieved 2016-01-23.
- ↑ Zadeh, Lofti, A. (1965). "Fuzzy sets". Information and Control 8 (3): 338––353. doi:10.1016/S0019-9958(65)90241-X.
- ↑ Zadeh, Lofti, A. (1975). "Fuzzy logic and approximate reasoning". Synthese 30 (3––4): 407––428. doi:10.1007/BF00485052.
- ↑ Dubois, D.; Prade, H. (2001). "Possibility Theory, Probability Theory and Multiple-Valued Logics: A Clarification" (PDF). Ann. Math. Artif. Intell. 32 (1––4): 35––66. doi:10.1023/A:1016740830286.
- ↑ Poole, D. (1993). "Probabilistic Horn abduction and Bayesian networks". Artificial Intelligence 64: 81–129. doi:10.1016/0004-3702(93)90061-F.
- ↑ Poole, D. (1997). "The Independent Choice Logic for modelling multiple agents under uncertainty". Artficial Intelligence 94: 7–56. doi:10.1016/S0004-3702(97)00027-1.
- ↑ Sato, T.; Kameya, Y. (2001). "Parameter learning of logic programs for symbolic-statistical modeling" (PDF). Journal of Artificial Intelligence Research 15: 391––454.
- ↑ figaro on GitHub
Further reading
- Kamel Mekhnacha (2013). Bayesian Programming. Chapman and Hall/CRC. ISBN 978-1-4398-8032-6.
External links
- A companion site to the Bayesian programming book where to download ProBT an inference engine dedicated to Bayesian programming.
- The Bayesian-programming.org site for the promotion of Bayesian programming with detailed information and numerous publications.