Apertium
|
| |
 | |
| Stable release | 3.2[1] / September 21, 2010 |
|---|---|
| Written in | C++ |
| Operating system | POSIX compatible |
| Available in | Multilingual |
| Type | Machine translation |
| License | GNU General Public License |
| Website | www.apertium.org |
Apertium is a free/open-source rule-based machine translation platform. It is free software and released under the terms of the GNU General Public License.
Overview
Apertium is a shallow-transfer machine translation system, which uses finite state transducers for all of its lexical transformations, and hidden Markov models for part-of-speech tagging or word category disambiguation. Constraint Grammar taggers are also used for some language pairs (e.g. Breton-French).[2]
Existing machine translation systems available at present are mostly commercial or use proprietary technologies, which makes them very hard to adapt to new usages; furthermore, they use different technologies across language pairs, which makes it very difficult, for instance, to integrate them in a single multilingual content management system.
Apertium uses a language-independent specification, to allow for the ease of contributing to Apertium, more efficient development, and enhancing the project's overall growth.
At present, Apertium has released 40 stable language pairs, delivering fast translation with reasonably intelligible results (errors are easily corrected). Being an open-source project, Apertium provides tools for potential developers to build their own language pair and contribute to the project.
History
Apertium originated as one of the machine translation engines in the project OpenTrad, which was funded by the Spanish government, and developed by the Transducens research group at the Universitat d'Alacant. It was originally designed to translate between closely related languages, although it has recently been expanded to treat more divergent language pairs. To create a new machine translation system, one just has to develop linguistic data (dictionaries, rules) in well-specified XML formats.
Language data developed for it (in collaboration with the Universidade de Vigo, the Universitat Politècnica de Catalunya and the Universitat Pompeu Fabra) currently support (in stable version) Arabic, Aragonese, Asturian, Basque, Breton, Bulgarian, Catalan, Danish, English, Esperanto, French, Galician, Hindi, Icelandic, Indonesian, Italian, Kazakh, Macedonian, Malaysian, Maltese, North Sami, Norwegian (Bokmål and Nynorsk), Occitan, Portuguese, Romanian, Serbo-Croatian, Slovenian, Spanish, Swedish, Tatar, Urdu, and Welsh languages. A full list is available below. Several companies are also involved in the development of Apertium, including Prompsit Language Engineering, Imaxin Software and Eleka Ingeniaritza Linguistikoa.
The project has taken part in the 2009,[3] 2010,[4] 2011,[5] 2012,[6] 2013[7] and 2014[8] editions of Google Summer of Code and the 2010,[9] 2011,[10] 2012,[11] 2013,[12] 2014,[13] and 2015[14] editions of Google Code-In.
How Apertium Works
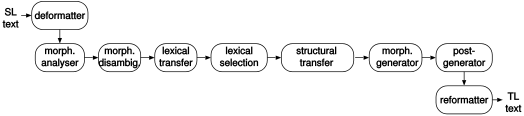
This is an overall, step-by-step view how Apertium works.
The diagram displays the steps that Apertium takes to translate a source-language text (the text we want to translate) into a target-language text (the translated text).
- Source language text is passed into Apertium for translation.
- The deformatter removes formatting markup (HTML, RTF, etc) that should be kept in place but not translated.
- The morphological analyser segments the text (expanding elisions, marking set phrases, etc), and look up segments in the language dictionaries, then returning baseform and tags for all matches. In pairs that involve agglutinative morphology, including a number of Turkic languages, a Helsinki Finite-State Transducer (HFST) is used. Otherwise, an Apertium-specific technology, called the lttoolbox,[15] is used.
- The morphological disambiguator (the morphological analyser and the morphological disambiguator together form the part of speech tagger) resolves ambiguous segments (i.e., when there is more than one match) by choosing one match. Apertium is working on installing more Constraint Grammar frameworks for its language pairs, allowing the imposition of more fine-grained constraints than would be otherwise possible. Apertium uses the Visual Interactive Syntax Learning Constraint Grammar Parser.[16]
- Lexical transfer looks up disambiguated source-language basewords to find their target-language equivalents (i.e., mapping source language to target language). For lexical transfer, Apertium uses an XML-based dictionary format called bidix.[17]
- Lexical selection chooses between alternative translations when the source text word has alternative meanings. Apertium uses a specific XML-based technology, apertium-lex-tools,[18] to perform lexical selection.
- Structural transfer (i.e., it's an XML format that allows writing complex structural transfer rules) can comprise of a one-step transfer or a three-step transfer module. It flags grammatical differences between the source language and target language (e.g. gender or number agreement) by creating a sequence of chunks containing markers for this. It then reorders or modifies chunks in order to produce a grammatical translation in the target-language. This is also done using lttoolbox.
- The morphological generator uses the tags to deliver the correct target language surface form. The morphological generator is a morphological transducer,[19] just like the morphological analyser. A morphological transducer both analyses and generates forms.
- The post-generator makes any necessary orthographic changes due to the contact of words (e.g. elisions)
- The reformatter replaces formatting markup (HTML, RTF, etc) that was removed by the deformatter in the first step.
- Apertium delivers the target-language translation.
Language pairs
List of currently stable language pairs, hover over the language codes to see the languages that they represent.
af |
ar |
an |
ast |
eu |
br |
bg |
ca |
da |
nl |
en |
eo |
fr |
gl |
hin |
is |
id |
it |
kaz |
mk |
ms |
mt |
sme |
nb |
nn |
oc |
pt |
ro |
hbs |
slv |
es |
sv |
tat |
urd |
cy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Afrikaans | — | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
| Arabic | No | — | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (←) | No | No | No | No | No | No | No | No | No | No | No | No | No |
| Aragonese | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | No |
| Asturian | No | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | No |
| Basque | No | No | No | No | — | No | No | No | No | No | Yes (→) | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (→) | No | No | No | No |
| Breton | No | No | No | No | No | — | No | No | No | No | No | No | Yes (→) | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
| Bulgarian | No | No | No | No | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
| Catalan | No | No | No | No | No | No | No | — | No | No | Yes (⇄) | Yes (→) | Yes (⇄) | No | No | No | No | Yes (←) | No | No | No | No | No | No | No | Yes (⇄) | Yes (⇄) | No | No | No | Yes (⇄) | No | No | No | No |
| Danish | No | No | No | No | No | No | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | Yes (⇄) | No | No | No | No | No | No | Yes (←) | No | No | No |
| Dutch | Yes (⇄) | No | No | No | No | No | No | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
| English | No | No | No | No | Yes (←) | No | No | Yes (⇄) | No | No | — | Yes (⇄) | No | Yes (⇄) | No | Yes (←) | No | No | No | Yes (←) | No | No | No | No | No | No | No | No | Yes (←) | No | Yes (⇄) | No | No | No | Yes (←) |
| Esperanto | No | No | No | No | No | No | No | Yes (←) | No | No | Yes (⇄) | — | Yes (←) | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (←) | No | No | No | No | No | No | No |
| French | No | No | No | No | No | Yes (←) | No | Yes (⇄) | No | No | No | Yes (→) | — | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No |
| Galician | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | Yes (⇄) | No | No | No | No |
| Hindi | No | No | No | No | No | No | No | No | No | No | No | No | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No |
| Icelandic | No | No | No | No | No | No | No | No | No | No | Yes (→) | No | No | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No |
| Indonesian | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | — | No | No | No | Yes (⇄) | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
| Italian | No | No | No | No | No | No | No | Yes (→) | No | No | No | No | No | No | No | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
| Kazakh | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No | No |
| Macedonian | No | No | No | No | No | No | Yes (⇄) | No | No | No | Yes (→) | No | No | No | No | No | No | No | No | — | No | No | No | No | No | No | No | No | Yes (←) | No | No | No | No | No | No |
| Malaysian | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
| Maltese | No | Yes (→) | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | — | No | No | No | No | No | No | No | No | No | No | No | No | No |
| North Sami | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | — | Yes (→) | No | No | No | No | No | No | No | No | No | No | No |
| Norwegian (Bokmål) | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (←) | — | Yes (⇄) | No | No | No | No | No | No | No | No | No | No |
| Norwegian (Nynorsk) | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | — | No | No | No | No | No | No | No | No | No | No |
| Occitan | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | — | No | No | No | No | Yes (⇄) | No | No | No | No |
| Portuguese | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | No | No | Yes (⇄) | No | No | No | No | No | No | No | No | No | No | No | No | — | No | No | No | Yes (⇄) | No | No | No | No |
| Romanian | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | — | No | No | Yes (←) | No | No | No | No |
| Serbo-Croatian | No | No | No | No | No | No | No | No | No | No | Yes (→) | No | No | No | No | No | No | No | No | Yes (→) | No | No | No | No | No | No | No | No | — | Yes (⇄) | No | No | No | No | No |
| Slovenian | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | — | No | No | No | No | No |
| Spanish | No | No | Yes (⇄) | Yes (⇄) | Yes (←) | No | No | Yes (⇄) | No | No | Yes (⇄) | Yes (→) | Yes (⇄) | Yes (⇄) | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | Yes (⇄) | Yes (←) | No | No | — | No | No | No | No |
| Swedish | No | No | No | No | No | No | No | No | Yes (→) | No | No | No | No | No | No | Yes (⇄) | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | — | No | No | No |
| Tatar | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | No | No | No | No | No | No | No | No | No | No | — | No | No |
| Urdu | No | No | No | No | No | No | No | No | No | No | No | No | No | No | Yes (⇄) | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | — | No |
| Welsh | No | No | No | No | No | No | No | No | No | No | Yes (→) | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | No | — |
See also
- Comparison of machine translation applications
- List of natural language processing toolkits
- Moses
- OpenLogos
- Machine translation
- Matxin
End-user services and software
(All services are based on the Apertium Engine)
Online translation websites
- Apertium Translation Home
- Prompsit Translator
- PoliTraductor Translator
- University d' Alacant Translator
- Universitat Oberta de Catalunya Translator
Offline applications
References
- Corbí-Bellot, M. et al. (2005) "An open-source shallow-transfer machine translation engine for the romance languages of Spain" in Proceedings of the European Association for Machine Translation, 10th Annual Conference, Budapest 2005, pp. 79–86
- Armentano-Oller, C. et al. (2006) "Open-source Portuguese-Spanish machine translation" in Lecture Notes in Computer Science 3960 [Computational Processing of the Portuguese Language, Proceedings of the 7th International Workshop on Computational Processing of Written and Spoken Portuguese, PROPOR 2006], p 50-59.
- Forcada, M. L. et al. (2010) "Documentation of the Open-Source Shallow-Transfer Machine Translation Platform Apertium" in Departament de Llenguatges i Sistemes Informatics, University of Alacant.
- Forcada, M. L. et. al. (2011) "Apertium: a free/open-source platform for rule-based machine translation". in "http://dx.doi.org/10.1007/s10590-011-9090-0"
- ↑ http://sourceforge.net/projects/apertium/files/apertium/3.2/
- ↑ Francis M. Tyers (2010) "Rule-based Breton to French machine translation". 'Proceedings of the 14th Annual Conference of the European Association of Machine Translation, EAMT10', pp. 174--181
- ↑ "Accepted organizations for Google Summer of Code 2009".
- ↑ "Accepted organizations for Google Summer of Code 2010".
- ↑ "Accepted organizations for Google Summer of Code 2011".
- ↑ "Accepted organizations for Google Summer of Code 2012".
- ↑ "Accepted organizations for Google Summer of Code 2013".
- ↑ "Accepted organizations for Google Summer of Code 2014".
- ↑ "Accepted organizations for Google Code-in 2010".
- ↑ "Accepted organizations for Google Code-in 2011".
- ↑ "Accepted organizations for Google Code In 2012".
- ↑ "Accepted organizations for Google Code-in 2013".
- ↑ "Accepted organizations for Google Code-in 2014".
- ↑ "Accepted organizations for Google Code-in 2015".
- ↑ "Lttoolbox - Apertium". wiki.apertium.org. Retrieved 2016-01-19.
- ↑ "VISL". beta.visl.sdu.dk. Retrieved 2016-01-19.
- ↑ "Bilingual dictionary - Apertium". wiki.apertium.org. Retrieved 2016-01-19.
- ↑ "Constraint-based lexical selection module - Apertium". wiki.apertium.org. Retrieved 2016-01-19.
- ↑ "Morphological dictionary - Apertium". wiki.apertium.org. Retrieved 2016-01-19.