Algebraic data type
In computer programming, particularly functional programming and type theory, an algebraic data type is a kind of composite type, i.e. a type formed by combining other types. Two common classes of algebraic type are product types—i.e. tuples and records—and sum types, also called tagged or disjoint unions or variant types.[1]
The values of a product type typically contain several values, called fields. All values of that type have the same combination of field types. The set of all possible values of a product type is the set-theoretical product, i.e. the Cartesian product, of the sets of all possible values of its field types.
The values of a sum type are typically grouped into several classes, called variants. A value of a variant type is usually created with a quasi-functional entity called a constructor. Each variant has its own constructor, which takes a specified number of arguments with specified types. The set of all possible values of a sum type is the set-theoretical sum, i.e. the disjoint union, of the sets of all possible values of its variants. Enumerated types are a special case of sum types in which the constructors take no arguments, as exactly one value is defined for each type.
Values of algebraic types are analyzed with pattern matching, which identifies a value by its constructor or field names and extracts the data it contains.
Algebraic data types were introduced in Hope, a small functional programming language developed in the 1970s at Edinburgh University.[2]
Examples
One of the most common examples of an algebraic data type is the singly linked list. A list type is a sum type with two variants, Nil for an empty list and Cons x xs for the combination of a new element x with a list xs to create a new list. Here is an example of how a singly linked list would be declared in Haskell:
data List a = Nil | Cons a (List a)
Cons is an abbreviation of construct. Many languages have special syntax for lists. For example, Haskell and ML use [] for Nil, : or :: for Cons, respectively, and square brackets for entire lists. So Cons 1 (Cons 2 (Cons 3 Nil)) would normally be written as 1:2:3:[] or [1,2,3] in Haskell, or as 1::2::3::[] or [1;2;3] in ML.
For a slightly more complex example, binary trees may be implemented in Haskell as follows:
data Tree = Empty
| Leaf Int
| Node Tree Tree
Here, Empty represents an empty tree, Leaf contains a piece of data, and Node organizes the data into branches.
In most languages that support algebraic data types, it is possible to define parametric types. Examples are given later in this article.
Somewhat similar to a function, a data constructor is applied to arguments of an appropriate type, yielding an instance of the data type to which the type constructor belongs. For instance, the data constructor Leaf is logically a function Int -> Tree, meaning that giving an integer as an argument to Leaf produces a value of the type Tree. As Node takes two arguments of the type Tree itself, the datatype is recursive.
Operations on algebraic data types can be defined by using pattern matching to retrieve the arguments. For example, consider a function to find the depth of a Tree, given here in Haskell:
depth :: Tree -> Int
depth Empty = 0
depth (Leaf n) = 1
depth (Node l r) = 1 + max (depth l) (depth r)
Thus, a Tree given to depth can be constructed using any of Empty, Leaf or Node and we must match for any of them respectively to deal with all cases. In case of Node, the pattern extracts the subtrees l and r for further processing.
Algebraic data types are particularly well-suited to the implementation of abstract syntax. For instance, the following algebraic data type describes a simple language representing numerical expressions:
data Expression = Number Int
| Add Expression Expression
| Minus Expression
| Mult Expression Expression
| Divide Expression Expression
An element of such a data type would have a form such as Mult (Add (Number 4) (Minus (Number 1))) (Number 2).
Writing an evaluation function for this language is a simple exercise; however, more complex transformations also become feasible. For instance, an optimization pass in a compiler might be written as a function taking an abstract expression as input and returning an optimized form.
Explanation
What is happening is that we have a datatype, which can be “one of several types of things.” Each “type of thing” is associated with an identifier called a constructor, which can be thought of as a kind of tag for that kind of data. Each constructor can carry with it a different type of data. A constructor could carry no data at all (e.g. "Empty" in the example above), carry one piece of data (e.g. “Leaf” has one Int value), or multiple pieces of data (e.g. “Node” has two Tree values).
When we want to do something with a value of this Tree algebraic data type, we deconstruct it using a process known as pattern matching. It involves matching the data with a series of patterns. The example function "depth" above pattern-matches its argument with three patterns. When the function is called, it finds the first pattern that matches its argument, performs any variable bindings that are found in the pattern, and evaluates the expression corresponding to the pattern.
Each pattern has a form that resembles the structure of some possible value of this datatype. The first pattern above simply matches values of the constructor Empty. The second pattern above matches values of the constructor Leaf. Patterns are recursive, so then the data that is associated with that constructor is matched with the pattern "n". In this case, a lowercase identifier represents a pattern that matches any value, which then is bound to a variable of that name — in this case, a variable “n” is bound to the integer value stored in the data type — to be used in the expression to be evaluated.
The recursion in patterns in this example are trivial, but a possible more complex recursive pattern would be something like Node (Node (Leaf 4) x) (Node y (Node Empty z))
The example above is operationally equivalent to the following pseudocode:
switch on (data.constructor)
case Empty:
return 0
case Leaf:
let n = data.field1
return 1
case Node:
let l = data.field1
let r = data.field2
return 1 + max (depth l) (depth r)
The comparison of this with pattern matching will point out some of the advantages of algebraic data types and pattern matching. First is type safety. The pseudocode above relies on the diligence of the programmer to not access field2 when the constructor is a Leaf, for example. Also, the type of field1 is different for Leaf and Node (for Leaf it is Int; for Node it is Tree), so the type system would have difficulties assigning a static type to it in a safe way in a traditional record data structure. However, in pattern matching, the type of each extracted value is checked based on the types declared by the relevant constructor, and how many values you can extract is known based on the constructor, so it does not face these problems.
Second, in pattern matching, the compiler statically checks that all cases are handled. If one of the cases of the “depth” function above were missing, the compiler would issue a warning, indicating that a case is not handled. This task may seem easy for the simple patterns above, but with many complicated recursive patterns, the task becomes difficult for the average human (or compiler, if it has to check arbitrary nested if-else constructs) to handle. Similarly, there may be patterns which never match (i.e. it is already covered by previous patterns), and the compiler can also check and issue warnings for these, as they may indicate an error in reasoning.
Do not confuse these patterns with regular expression patterns used in string pattern matching. The purpose is similar — to check whether a piece of data matches certain constraints, and if so, extract relevant parts of it for processing — but the mechanism is very different. This kind of pattern matching on algebraic data types matches on the structural properties of an object rather than on the character sequence of strings.
Theory
A general algebraic data type is a possibly recursive sum type of product types. Each constructor tags a product type to separate it from others, or if there is only one constructor, the data type is a product type. Further, the parameter types of a constructor are the factors of the product type. A parameterless constructor corresponds to the empty product. If a datatype is recursive, the entire sum of products is wrapped in a recursive type, and each constructor also rolls the datatype into the recursive type.
For example, the Haskell datatype:
data List a = Nil | Cons a (List a)
is represented in type theory as
 with constructors
with constructors  and
and  .
.
The Haskell List datatype can also be represented in type theory in a slightly different form, as follows:
 .
(Note how the
.
(Note how the 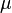 and
and  constructs are reversed relative to the original.) The original formation specified a type function whose body was a recursive type; the revised version specifies a recursive function on types. (We use the type variable
constructs are reversed relative to the original.) The original formation specified a type function whose body was a recursive type; the revised version specifies a recursive function on types. (We use the type variable 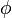 to suggest a function rather than a "base type" like
to suggest a function rather than a "base type" like 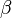 , since is like a Greek "f".) Note that we must also now apply the function to its argument type
, since is like a Greek "f".) Note that we must also now apply the function to its argument type  in the body of the type.
in the body of the type.
For the purposes of the List example, these two formulations are not significantly different; but the second form allows one to express so-called nested data types, i.e., those where the recursive type differs parametrically from the original. (For more information on nested data types, see the works of Richard Bird, Lambert Meertens and Ross Paterson.)
In set theory the equivalent of a sum type is a disjoint union – a set whose elements are pairs consisting of a tag (equivalent to a constructor) and an object of a type corresponding to the tag (equivalent to the constructor arguments).
Programming languages with algebraic data types
The following programming languages have algebraic data types as a first class notion:
See also
- Disjoint union
- Generalized algebraic data type
- Initial algebra
- Quotient type
- Tagged union
- Type theory
- Visitor pattern
References
- ↑ Records and variants - OCaml manual section 1.4
- ↑ Paul Hudak, John Hughes, Simon Peyton Jones, Philip Wadler. "A history of Haskell: being lazy with class". Proceedings of the third ACM SIGPLAN conference on History of programming languages.
Presentations included Rod Burstall, Dave MacQueen, and Don Sannella on Hope, the language that introduced algebraic data types
This article is based on material taken from algebraic data type at the Free On-line Dictionary of Computing prior to 1 November 2008 and incorporated under the "relicensing" terms of the GFDL, version 1.3 or later.
| ||||||||||||||||||||||||||||||