Yen's algorithm
Yen's algorithm computes single-source K-shortest loopless paths for a graph with non-negative edge cost.[1] The algorithm was published by Jin Y. Yen in 1971 and employs any shortest path algorithm to find the best path, then proceeds to find K − 1 deviations of the best path.[2]
| Graph and tree search algorithms |
|---|
| Listings |
|
| Related topics |
Algorithm
Terminology and notation
| Notation | Description |
|---|---|
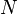 | The size of the graph, i.e., the amount of nodes in the network. |
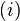 | The 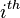 node of the graph, where node of the graph, where 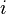 ranges from ranges from 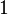 to . This means that to . This means that 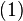 is the source node of the graph and is the source node of the graph and 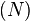 is the sink node of the graph. is the sink node of the graph. |
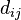 | The cost of the edge between and 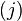 , assuming that , assuming that 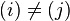 and and 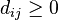 . . |
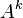 | The 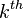 shortest path from to , where shortest path from to , where 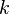 ranges from to ranges from to 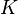 . Then . Then 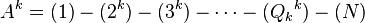 , where , where 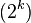 is the 2nd node of the shortest path and is the 2nd node of the shortest path and 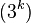 is the 3rd node of the shortest path, and so on. is the 3rd node of the shortest path, and so on. |
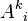 | A deviation path from 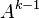 at node , where ranges from to at node , where ranges from to 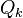 . Note that the maximum value of is , which is the node just before the sink in the shortest path. This means that the deviation path cannot deviate from the . Note that the maximum value of is , which is the node just before the sink in the shortest path. This means that the deviation path cannot deviate from the 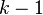 shortest path at the sink. The paths and follow the same path until the shortest path at the sink. The paths and follow the same path until the  node, then node, then 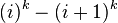 edge is different from any path in edge is different from any path in 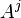 , where , where 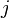 ranges from to . ranges from to . |
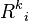 | The root path of that follows that until the node of . |
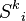 | The spur path of that starts at the node of and ends at the sink. |
Description
The algorithm can be broken down into two parts, determining the first k-shortest path, 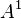 , and then determining all other k-shortest paths. It is assumed that the container
, and then determining all other k-shortest paths. It is assumed that the container 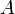 will hold the k-shortest path, whereas the container
will hold the k-shortest path, whereas the container 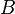 , will hold the potential k-shortest paths. To determine , the shortest path from the source to the sink, any efficient shortest path algorithm can be used.
, will hold the potential k-shortest paths. To determine , the shortest path from the source to the sink, any efficient shortest path algorithm can be used.
To find the , where ranges from 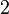 to , the algorithm assumes that all paths from to have previously been found. The iteration can be divided into two processes, finding all the deviations and choosing a minimum length path to become . Note that in this iteration, ranges from to
to , the algorithm assumes that all paths from to have previously been found. The iteration can be divided into two processes, finding all the deviations and choosing a minimum length path to become . Note that in this iteration, ranges from to 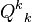 .
.
The first process can be further subdivided into three operations, choosing the , finding , and then adding to the container . The root path, , is chosen by finding the subpath in that follows the first nodes of 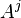 , where ranges from to . Then, if a path is found, the cost of edge
, where ranges from to . Then, if a path is found, the cost of edge 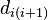 of is set to infinity. Next, the spur path, , is found by computing the shortest path from the spur node, node , to the sink. The removal of previous used edges from to
of is set to infinity. Next, the spur path, , is found by computing the shortest path from the spur node, node , to the sink. The removal of previous used edges from to 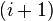 ensures that the spur path is different.
ensures that the spur path is different. 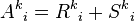 , the addition of the root path and the spur path, is added to . Next, the edges that were removed, i.e. had their cost set to infinity, are restored to their initial values.
, the addition of the root path and the spur path, is added to . Next, the edges that were removed, i.e. had their cost set to infinity, are restored to their initial values.
The second process determines a suitable path for by finding the path in container with the lowest cost. This path is removed from container and inserted into container and the algorithm continues to the next iteration. Note that if the amount of paths in container equal or exceed the amount of k-shortest paths that still need to be found, then the necessary paths of container are added to container and the algorithm is finished.
Pseudocode
The algorithm assumes that the Dijkstra algorithm is used to find the shortest path between two nodes, but any shortest path algorithm can be used in its place.
function YenKSP(Graph, source, sink, K):
// Determine the shortest path from the source to the sink.
A[0] = Dijkstra(Graph, source, sink);
// Initialize the heap to store the potential kth shortest path.
B = [];
for k from 1 to K:
// The spur node ranges from the first node to the next to last node in the previous k-shortest path.
for i from 0 to size(A[k − 1]) − 1:
// Spur node is retrieved from the previous k-shortest path, k − 1.
spurNode = A[k-1].node(i);
// The sequence of nodes from the source to the spur node of the previous k-shortest path.
rootPath = A[k-1].nodes(0, i);
for each path p in A:
if rootPath == p.nodes(0, i):
// Remove the links that are part of the previous shortest paths which share the same root path.
remove p.edge(i, i + 1) from Graph;
for each node rootPathNode in rootPath except spurNode:
remove rootPathNode from Graph;
// Calculate the spur path from the spur node to the sink.
spurPath = Dijkstra(Graph, spurNode, sink);
// Entire path is made up of the root path and spur path.
totalPath = rootPath + spurPath;
// Add the potential k-shortest path to the heap.
B.append(totalPath);
// Add back the edges and nodes that were removed from the graph.
restore edges to Graph;
restore nodes in rootPath to Graph;
if B is empty:
// This handles the case of there being no spur paths, or no spur paths left.
// This could happen if the spur paths have already been exhausted (added to A),
// or there are no spur paths at all - such as when both the source and sink vertices
// lie along a "dead end".
break;
// Sort the potential k-shortest paths by cost.
B.sort();
// Add the lowest cost path becomes the k-shortest path.
A[k] = B[0];
B.pop();
return A;
Example

The example uses Yen's K-Shortest Path Algorithm to compute three paths from 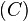 to
to 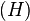 . Dijkstra's algorithm is used to calculate the best path from to , which is
. Dijkstra's algorithm is used to calculate the best path from to , which is 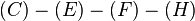 with cost 5. This path is appended to container and becomes the first k-shortest path, .
with cost 5. This path is appended to container and becomes the first k-shortest path, .
Node of becomes the spur node with a root path of itself, 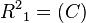 . The edge,
. The edge, 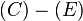 , is removed because it coincides with the root path and a path in container . Dijkstra's algorithm is used to compute the spur path
, is removed because it coincides with the root path and a path in container . Dijkstra's algorithm is used to compute the spur path 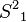 , which is
, which is  , with a cost of 8.
, with a cost of 8. 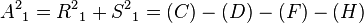 is added to container as a potential k-shortest path.
is added to container as a potential k-shortest path.
Node 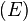 of becomes the spur node with
of becomes the spur node with 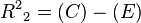 . The edge,
. The edge, 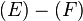 , is removed because it coincides with the root path and a path in container . Dijkstra's algorithm is used to compute the spur path
, is removed because it coincides with the root path and a path in container . Dijkstra's algorithm is used to compute the spur path 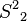 , which is
, which is 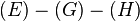 , with a cost of 7.
, with a cost of 7. 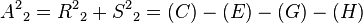 is added to container as a potential k-shortest path.
is added to container as a potential k-shortest path.
Node 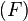 of becomes the spur node with a root path,
of becomes the spur node with a root path,  . The edge,
. The edge, 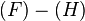 , is removed because it coincides with the root path and a path in container . Dijkstra's algorithm is used to compute the spur path
, is removed because it coincides with the root path and a path in container . Dijkstra's algorithm is used to compute the spur path 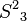 , which is
, which is 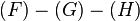 , with a cost of 8.
, with a cost of 8. 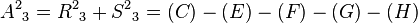 is added to container as a potential k-shortest path.
is added to container as a potential k-shortest path.
Of the three paths in container B, 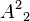 is chosen to become
is chosen to become 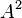 because it has the lowest cost of 7. This process is continued to the 3rd k-shortest path. However, within this 3rd iteration, note that some spur paths do not exist.And the path that is chosen to become
because it has the lowest cost of 7. This process is continued to the 3rd k-shortest path. However, within this 3rd iteration, note that some spur paths do not exist.And the path that is chosen to become  is .
is .
Features
Space complexity
To store the edges of the graph, the shortest path list , and the potential shortest path list , 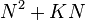 memory addresses are required.[2] At worse case, the every node in the graph has an edge to every other node in the graph, thus
memory addresses are required.[2] At worse case, the every node in the graph has an edge to every other node in the graph, thus 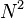 addresses are needed. Only
addresses are needed. Only 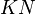 addresses are need for both list and because at most only paths will be stored,[2] where it is possible for each path to have nodes.
addresses are need for both list and because at most only paths will be stored,[2] where it is possible for each path to have nodes.
Time complexity
The time complexity of Yen's algorithm is dependent on the shortest path algorithm used in the computation of the spur paths, so the Dijkstra algorithm is assumed. Dijkstra's algorithm has a worse case time complexity of 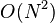 , but using a Fibonacci heap it becomes
, but using a Fibonacci heap it becomes 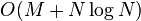 ,[3] where
,[3] where 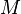 is the amount of edges in the graph. Since Yen's algorithm makes
is the amount of edges in the graph. Since Yen's algorithm makes 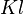 calls to the Dijkstra in computing the spur paths, where
calls to the Dijkstra in computing the spur paths, where 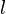 is the length of spur paths. In a condensed graph, the expected value of is
is the length of spur paths. In a condensed graph, the expected value of is 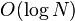 , while the worst case is .
, the time complexity becomes
, while the worst case is .
, the time complexity becomes 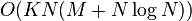 .
[4]
.
[4]
Improvements
Yen's algorithm can be improved by using a heap to store , the set of potential k-shortest paths. Using a heap instead of a list will improve the performance of the algorithm, but not the complexity.[5] One method to slightly decrease complexity is to skip the nodes where there are non-existent spur paths. This case is produced when all the spur paths from a spur node have been used in the previous . Also, if container has 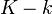 paths of minimum length, in reference to those in container , then they can be extract and inserted into container since no shorter paths will be found.
paths of minimum length, in reference to those in container , then they can be extract and inserted into container since no shorter paths will be found.
Lawler's modification
Eugene Lawler proposed a modification to Yen's algorithm in which duplicates path are not calculated as opposed to the original algorithm where they are calculated and then discarded when they are found to be duplicates.[6] These duplicates paths result from calculating spur paths of nodes in the root of . For instance, 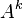 deviates from at some node . Any spur path,
deviates from at some node . Any spur path, 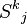 where
where 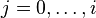 , that is calculated will be a duplicate because they have already been calculated during the iteration. Therefore, only spur paths for nodes that were on the spur path of must be calculated, i.e. only
, that is calculated will be a duplicate because they have already been calculated during the iteration. Therefore, only spur paths for nodes that were on the spur path of must be calculated, i.e. only 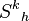 where
where 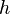 ranges from
ranges from 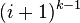 to
to 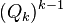 . To perform this operation for , a record is needed to identify the node where branched from
. To perform this operation for , a record is needed to identify the node where branched from 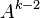 .
.
See also
- Yen's improvement to the Bellman–Ford algorithm
References
- ↑ Yen, Jin Y. (1970). "An algorithm for finding shortest routes from all source nodes to a given destination in general networks". Quarterly of Applied Mathematics 27: 526–530. MR 0102435.
- ↑ 2.0 2.1 2.2 Yen, Jin Y. (Jul 1971). "Finding the k Shortest Loopless Paths in a Network". Management Science 17 (11): 712–716. doi:10.1287/mnsc.17.11.712.
- ↑ Fredman, Michael Lawrence; Tarjan, Robert E. (1984). Fibonacci heaps and their uses in improved network optimization algorithms. 25th Annual Symposium on Foundations of Computer Science. IEEE. pp. 338–346. doi:10.1109/SFCS.1984.715934.
- ↑ Bouillet, Eric (2007). Path routing in mesh optical networks. Chichester, England: John Wiley & Sons. ISBN 9780470032985.
- ↑ Brander, Andrew William; Sinclair, Mark C. A comparative study of k-shortest path algorithms. Department of Electronic Systems Engineering, University of Essex, 1995.
- ↑ Lawler, EL (1972). "A procedure for computing the k best solutions to discrete optimization problems and its application to the shortest path problem.". Management Science, Theory Series 18: 401–405. doi:10.1287/mnsc.18.7.401.
External links
- Open Source Python Implementation on GitHub
- Open Source C++ Implementation on Google Code