Work stealing
In parallel computing, work stealing is a scheduling strategy for multithreaded computer programs. It solves the problem of executing a dynamically multithreaded computation, one that can "spawn" new threads of execution, on a statically multithreaded computer, with a fixed number of processor cores. It does so efficiently both in terms of execution time and memory usage.
In a work stealing scheduler, each processor in a computer system has a queue of work items (computational tasks, threads) to perform. Each work item consists of a series of instructions, to be executed sequentially, but in the course of its execution, a work item may also spawn new work items that can feasibly be executed in parallel with its other work. These new items are initially put on the queue of the processor executing the work item. When a processor runs out of work, it looks at the queues of other processors and "steals" their work items.
Work stealing contrasts with work sharing, another popular scheduling approach for dynamic multithreading, where each work item is scheduled onto a processor when it is spawned. Compared to this approach, work stealing reduces the amount of process migration between processors, because no such migration occurs when all processors have work to do.[1]
The idea of work stealing goes back to the implementation of the Multilisp programming language and work on parallel functional programming languages in the 1980s.[1] It is employed in the scheduler for the Cilk programming language,[2] the Java fork/join framework,[3] and the .NET Task Parallel Library.[4]
Execution model
Work stealing is designed for a "strict" fork–join model of parallel computation, which means that a computation can be viewed as a directed acyclic graph with a single source (start of computation) and a single sink (end of computation). Each node in this graph represents either a fork, producing multiple logically parallel computations, variously called "threads"[1] or "strands".[5] Edges represent serial computation.[6][note 1]
As an example, consider the following trivial fork–join program in Cilk-like syntax:
function f(a, b):
c ← fork g(a)
d ← h(b)
join
return c + d
function g(a):
return a × 2
function h(a):
b ← fork g(a)
c ← a + 1
join
return b + c
The function call f(1, 2) gives rise to the following computation graph:

In the graph, when two edges leave a node, the computations represented by the edge labels are logically parallel: they may be performed either in parallel, or sequentially. The computation may only proceed past a join node when the computations represented by its incoming edges are complete. The work of a scheduler, now, is to assign the computations (edges) to processors in a way that makes the entire computation run to completion in the correct order (as constrained by the join nodes), preferably as fast as possible.
Algorithm
The randomized version of the work stealing algorithm presented by Blumofe and Leiserson maintains several threads of execution and schedules these onto 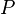 processors. Each of the processors has a double-ended queue (deque) of threads. Call the ends of the deque "top" and "bottom".
processors. Each of the processors has a double-ended queue (deque) of threads. Call the ends of the deque "top" and "bottom".
Each processor that has a current thread to execute, executes the instructions in the thread one by one, until it encounters an instruction that causes one of four "special" behaviors:[1]:10
- A spawn instruction causes a new thread to be created. The current thread is placed at the bottom of the deque, and the processor starts executing the new thread.
- A stalling instruction is one that temporarily halts execution of its thread. The processor pops a thread off the bottom of its deque and starts executing that thread. If its deque is empty, it starts work stealing, explained below.
- An instruction may cause a thread to die. The behavior in this case is the same as for an instruction that stalls.
- An instruction may enable another thread. The other thread is pushed onto the bottom of the deque, but the processor continues execution of its current thread.
Initially, a computation consists of a single thread and is assigned to some processor, while the other processors start off idle. Any processor that becomes idle starts the actual process of work stealing, which means the following:
- it picks another processor uniformly at random;
- if the other processor's deque is non-empty, it pops the top-most thread off the deque and starts executing that;
- else, repeat.
Child stealing vs. continuation stealing
Note that, in the rule for spawn, Blumofe and Leiserson suggest that the "parent" thread execute its new thread, as if performing a function call (in the C-like program f(x); g(y);, the function call to f completes before the call to g is performed). This is called "continuation stealing", because the continuation of the function can be stolen while the spawned thread is executed, and is what is used by Cilk Plus.[5] It is not the only way to implement work stealing; the alternative strategy is called "child stealing" and is easier to implement as a library, without compiler support.[5] Child stealing is used by Threading Building Blocks, Microsoft's Task Parallel Library and OpenMP, although the latter gives the programmer control over which strategy is used.[5]
Efficiency
Several variants of work stealing have been proposed. The randomized variant due to Blumofe and Leiserson executes a parallel computation in expected time 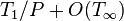 on processors; here,
on processors; here, 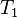 is the work, or the amount of time required to run the computation on a serial computer, and
is the work, or the amount of time required to run the computation on a serial computer, and 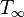 is the span, the amount of time required on an infinitely parallel machine.[note 2] This means that, in expectation, the time required is at most a constant factor times the theoretical minimum.[1]
is the span, the amount of time required on an infinitely parallel machine.[note 2] This means that, in expectation, the time required is at most a constant factor times the theoretical minimum.[1]
Space usage
A computation scheduled by the Blumofe–Leiserson version of work stealing uses 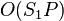 stack space, if
stack space, if 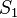 were the stack usage of the same computation on a single processor,[1] fitting the authors' own earlier definition of space efficiency.[7] This bound requires continuation stealing; in a child stealing scheduler, it does not hold.[5]
were the stack usage of the same computation on a single processor,[1] fitting the authors' own earlier definition of space efficiency.[7] This bound requires continuation stealing; in a child stealing scheduler, it does not hold.[5]
Multiprogramming variant
The work stealing algorithm as outlined earlier, and its analysis, assume a computing environment where a computation are scheduled onto dedicated processors. In a multiprogramming (multi-tasking) environment, other processes may be vying for the processors and an operating system scheduler determines how much processor time each process gets. A variant of work stealing has been devised for this situation, which executes a computation in expected time 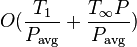 , where
, where 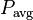 is the average number of processors allocated to the computation by the OS scheduler over the computation's running time.[8]
is the average number of processors allocated to the computation by the OS scheduler over the computation's running time.[8]
Notes
References
- ↑ 1.0 1.1 1.2 1.3 1.4 1.5 Blumofe, Robert D.; Leiserson, Charles E. (1999). "Scheduling multithreaded computations by work stealing". Journal of the ACM 46 (5): 720–748. doi:10.1145/324133.324234.
- ↑ Blumofe, Robert D.; Joerg, Christopher F.; Kuszmaul, Bradley C.; Leiserson, Charles E.; Randall, Keith H.; Zhou, Yuli (1996). "Cilk: An efficient multithreaded runtime system". J. Parallel and Distributed Computing 37 (1): 55–69. doi:10.1006/jpdc.1996.0107.
- ↑ Doug Lea (2000). A Java fork/join framework. ACM Conf. on Java.
- ↑ Leijen, Daan; Schulte, Wolfram; Burckhardt, Sebastian (2009). "The Design of a Task Parallel Library". ACM SIGPLAN Notices 44 (10).
- ↑ 5.0 5.1 5.2 5.3 5.4 Robison, Arch (15 January 2014). A Primer on Scheduling Fork–Join Parallelism with Work Stealing (Technical report). ISO/IEC JTC 1/SC 22/WG 21—The C++ Standards Committee. N3872.
- ↑ Halpern, Pablo (24 September 2012). Strict Fork–Join Parallelism (Technical report). ISO/IEC JTC 1/SC 22/WG 21—The C++ Standards Committee. N3409=12-0099.
- ↑ Blumofe, Robert D.; Leiserson, Charles E. (1998). "Space-efficient scheduling of multithreaded computations". SIAM J. Computing 27 (1): 202–229. doi:10.1137/s0097539793259471.
- ↑ Arora, Nimar S.; Blumofe, Robert D.; Plaxton, C. Greg (2001). "Thread scheduling for multiprogrammed multiprocessors". Theory of Computing Systems 34 (2): 115–144. doi:10.1007/s002240011004.