w-shingling
In natural language processing a w-shingling is a set of unique "shingles" (n-grams, contiguous subsequences of tokens in a document) that can be used to gauge the similarity of two documents. The w denotes the number of tokens in each shingle in the set.
The document, "a rose is a rose is a rose" can be tokenized as follows:
- (a,rose,is,a,rose,is,a,rose)
The set of all contiguous sequences of 4 tokens (4-grams) is
- { (a,rose,is,a), (rose,is,a,rose), (is,a,rose,is), (a,rose,is,a), (rose,is,a,rose) } = { (a,rose,is,a), (rose,is,a,rose), (is,a,rose,is) }
Resemblance
For a given shingle size, the degree to which two documents A and B resemble each other can be expressed as the ratio of the magnitudes of their shinglings' intersection and union, or
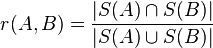
where |A| is the size of set A. The resemblance is a number in the range [0,1], where 1 indicates that two documents are identical. This definition is identical with the Jaccard coefficient describing similarity and diversity of sample sets.
See also
- Concept mining offers an alternative method for document similarity calculation with more computational complexity, but where the measure more closely models a human's perception of document similarity.
- N-gram
- k-mer
- MinHash
- Rolling hash
- Rabin fingerprint
- Vector space model
- Bag-of-words model
References
- (Manber 1993) Finding Similar Files in a Large File System. Does not yet use the term "shingling". Available as PDF
- (Broder, Glassman, Manasse, and Zweig 1997) Syntactic Clustering of the Web. SRC Technical Note #1997-015. Available at HTML here