Universal hashing
Using universal hashing (in a randomized algorithm or data structure) refers to selecting a hash function at random from a family of hash functions with a certain mathematical property (see definition below). This guarantees a low number of collisions in expectation, even if the data is chosen by an adversary. Many universal families are known (for hashing integers, vectors, strings), and their evaluation is often very efficient. Universal hashing has numerous uses in computer science, for example in implementations of hash tables, randomized algorithms, and cryptography.
Introduction
Assume we want to map keys from some universe 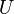 into
into 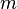 bins (labelled
bins (labelled ![[m] = \{0, \dots, m-1\}](../I/m/996198cf634c01f7df11d24f34f17980.png) ). The algorithm will have to handle some data set
). The algorithm will have to handle some data set  of
of 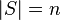 keys, which is not known in advance. Usually, the goal of hashing is to obtain a low number of collisions (keys from
keys, which is not known in advance. Usually, the goal of hashing is to obtain a low number of collisions (keys from 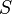 that land in the same bin). A deterministic hash function cannot offer any guarantee in an adversarial setting if the size of is greater than
that land in the same bin). A deterministic hash function cannot offer any guarantee in an adversarial setting if the size of is greater than 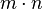 , since the adversary may choose to be precisely the preimage of a bin. This means that all data keys land in the same bin, making hashing useless. Furthermore, a deterministic hash function does not allow for rehashing: sometimes the input data turns out to be bad for the hash function (e.g. there are too many collisions), so one would like to change the hash function.
, since the adversary may choose to be precisely the preimage of a bin. This means that all data keys land in the same bin, making hashing useless. Furthermore, a deterministic hash function does not allow for rehashing: sometimes the input data turns out to be bad for the hash function (e.g. there are too many collisions), so one would like to change the hash function.
The solution to these problems is to pick a function randomly from a family of hash functions. A family of functions ![H = \{ h : U \to [m] \}](../I/m/4f541cb630b1b1301c0aecfc337b0844.png) is called a universal family if,
is called a universal family if, ![\forall x, y \in U, ~ x\ne y: ~~ \Pr_{h\in H} [h(x) = h(y)] \le \frac{1}{m}](../I/m/030fb4de473ae00dd33831fca8d4cbaa.png) .
.
In other words, any two keys of the universe collide with probability at most 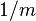 when the hash function
when the hash function 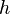 is drawn randomly from
is drawn randomly from 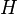 . This is exactly the probability of collision we would expect if the hash function assigned truly random hash codes to every key. Sometimes, the definition is relaxed to allow collision probability
. This is exactly the probability of collision we would expect if the hash function assigned truly random hash codes to every key. Sometimes, the definition is relaxed to allow collision probability  . This concept was introduced by Carter and Wegman[1] in 1977, and has found numerous applications in computer science (see, for example [2]). If we have an upper bound of
. This concept was introduced by Carter and Wegman[1] in 1977, and has found numerous applications in computer science (see, for example [2]). If we have an upper bound of 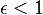 on the collision probability, we say that we have
on the collision probability, we say that we have  -almost universality.
-almost universality.
Many, but not all, universal families have the following stronger uniform difference property:
-
 , when is drawn randomly from the family , the difference
, when is drawn randomly from the family , the difference  is uniformly distributed in
is uniformly distributed in ![[m]](../I/m/efc831aabf9ade051f781ccb54c2dcdb.png) .
.
Note that the definition of universality is only concerned with whether 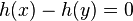 , which counts collisions. The uniform difference property is stronger.
, which counts collisions. The uniform difference property is stronger.
(Similarly, a universal family can be XOR universal if , the value 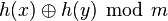 is uniformly distributed in where
is uniformly distributed in where 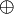 is the bitwise exclusive or operation. This is only possible if is a power of two.)
is the bitwise exclusive or operation. This is only possible if is a power of two.)
An even stronger condition is pairwise independence: we have this property when we have the probability that 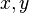 will hash to any pair of hash values
will hash to any pair of hash values 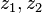 is as if they were perfectly random:
is as if they were perfectly random: 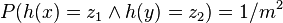 . Pairwise independence is sometimes called strong universality.
. Pairwise independence is sometimes called strong universality.
Another property is uniformity. We say that a family is uniform if all hash values are equally likely: 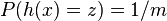 for any hash value
for any hash value 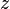 . Universality does not imply uniformity. However, strong universality does imply uniformity.
. Universality does not imply uniformity. However, strong universality does imply uniformity.
Given a family with the uniform distance property, one can produce a pairwise independent or strongly universal hash family by adding a uniformly distributed random constant with values in to the hash functions. (Similarly, if is a power of two, we can achieve pairwise independence from an XOR universal hash family by doing an exclusive or with a uniformly distributed random constant.) Since a shift by a constant is sometimes irrelevant in applications (e.g. hash tables), a careful distinction between the uniform distance property and pairwise independent is sometimes not made.[3]
For some applications (such as hash tables), it is important for the least significant bits of the hash values to be also universal. When a family is strongly universal, this is guaranteed: if is a strongly universal family with  , then the family made of the functions
, then the family made of the functions  for all
for all 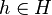 is also strongly universal for
is also strongly universal for 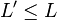 . Unfortunately, the same is not true of (merely) universal families. For example the family made of the identity function
. Unfortunately, the same is not true of (merely) universal families. For example the family made of the identity function 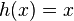 is clearly universal, but the family made of the function
is clearly universal, but the family made of the function 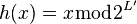 fails to be universal.
fails to be universal.
Mathematical guarantees
For any fixed set of  keys, using a universal family guarantees the following properties.
keys, using a universal family guarantees the following properties.
- For any fixed
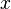 in , the expected number of keys in the bin
in , the expected number of keys in the bin 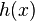 is
is 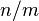 . When implementing hash tables by chaining, this number is proportional to the expected running time of an operation involving the key (for example a query, insertion or deletion).
. When implementing hash tables by chaining, this number is proportional to the expected running time of an operation involving the key (for example a query, insertion or deletion). - The expected number of pairs of keys in with
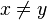 that collide (
that collide (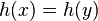 ) is bounded above by
) is bounded above by 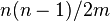 , which is of order
, which is of order 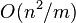 . When the number of bins, , is
. When the number of bins, , is 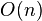 , the expected number of collisions is . When hashing into
, the expected number of collisions is . When hashing into 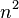 bins, there are no collisions at all with probability at least a half.
bins, there are no collisions at all with probability at least a half. - The expected number of keys in bins with at least
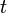 keys in them is bounded above by
keys in them is bounded above by 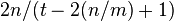 .[4] Thus, if the capacity of each bin is capped to three times the average size (
.[4] Thus, if the capacity of each bin is capped to three times the average size (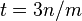 ), the total number of keys in overflowing bins is at most
), the total number of keys in overflowing bins is at most 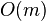 . This only holds with a hash family whose collision probability is bounded above by . If a weaker definition is used, bounding it by , this result is no longer true.[4]
. This only holds with a hash family whose collision probability is bounded above by . If a weaker definition is used, bounding it by , this result is no longer true.[4]
As the above guarantees hold for any fixed set , they hold if the data set is chosen by an adversary. However, the adversary has to make this choice before (or independent of) the algorithm's random choice of a hash function. If the adversary can observe the random choice of the algorithm, randomness serves no purpose, and the situation is the same as deterministic hashing.
The second and third guarantee are typically used in conjunction with rehashing. For instance, a randomized algorithm may be prepared to handle some number of collisions. If it observes too many collisions, it chooses another random from the family and repeats. Universality guarantees that the number of repetitions is a geometric random variable.
Constructions
Since any computer data can be represented as one or more machine words, one generally needs hash functions for three types of domains: machine words ("integers"); fixed-length vectors of machine words; and variable-length vectors ("strings").
Hashing integers
This section refers to the case of hashing integers that fit in machines words; thus, operations like multiplication, addition, division, etc. are cheap machine-level instructions. Let the universe to be hashed be  .
.
The original proposal of Carter and Wegman[1] was to pick a prime 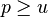 and define
and define
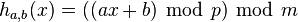
where  are randomly chosen integers modulo
are randomly chosen integers modulo 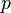 with
with 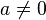 . Technically, adding
. Technically, adding 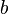 is not needed for universality (but it does make the hash function 2-independent).
(This is a single iteration of a linear congruential generator).
is not needed for universality (but it does make the hash function 2-independent).
(This is a single iteration of a linear congruential generator).
To see that  is a universal family, note that only holds when
is a universal family, note that only holds when
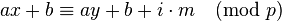
for some integer 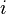 between
between 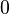 and
and 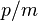 . If , their difference,
. If , their difference, 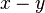 is nonzero and has an inverse modulo . Solving for
is nonzero and has an inverse modulo . Solving for 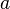 ,
,
-
 .
.
There are 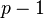 possible choices for (since
possible choices for (since 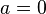 is excluded) and, varying in the allowed range,
is excluded) and, varying in the allowed range, 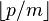 possible values for the right hand side. Thus the collision probability is
possible values for the right hand side. Thus the collision probability is

which tends to for large as required. This analysis also shows that does not have to be randomised in order to have universality.
Another way to see is a universal family is via the notion of statistical distance. Write the difference  as
as
-
 .
.
Since is nonzero and is uniformly distributed in 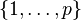 , it follows that
, it follows that 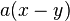 modulo is also uniformly distributed in . The distribution of
modulo is also uniformly distributed in . The distribution of  is thus almost uniform, up to a difference in probability of
is thus almost uniform, up to a difference in probability of  between the samples. As a result, the statistical distance to a uniform family is
between the samples. As a result, the statistical distance to a uniform family is  , which becomes negligible when
, which becomes negligible when 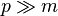 .
.
Avoiding modular arithmetic
The state of the art for hashing integers is the multiply-shift scheme described by Dietzfelbinger et al. in 1997.[5] By avoiding modular arithmetic, this method is much easier to implement and also runs significantly faster in practice (usually by at least a factor of four[6]). The scheme assumes the number of bins is a power of two, 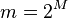 . Let
. Let 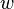 be the number of bits in a machine word. Then the hash functions are parametrised over odd positive integers
be the number of bits in a machine word. Then the hash functions are parametrised over odd positive integers 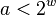 (that fit in a word of bits). To evaluate
(that fit in a word of bits). To evaluate 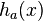 , multiply by modulo
, multiply by modulo 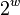 and then keep the high order
and then keep the high order 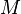 bits as the hash code. In mathematical notation, this is
bits as the hash code. In mathematical notation, this is

and it can be implemented in C-like programming languages by
-
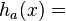
(unsigned) (a*x) >> (w-M)
This scheme does not satisfy the uniform difference property and is only 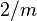 -almost-universal; for any ,
-almost-universal; for any , 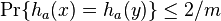 .
.
To understand the behavior of the hash function,
notice that, if 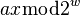 and
and 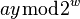 have the same highest-order 'M' bits, then
have the same highest-order 'M' bits, then 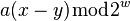 has either all 1's or all 0's as its highest order M bits (depending on whether or is larger.
Assume that the least significant set bit of appears on position
has either all 1's or all 0's as its highest order M bits (depending on whether or is larger.
Assume that the least significant set bit of appears on position  . Since is a random odd integer and odd integers have inverses in the ring
. Since is a random odd integer and odd integers have inverses in the ring  , it follows that will be uniformly distributed among -bit integers with the least significant set bit on position . The probability that these bits are all 0's or all 1's is therefore at most
, it follows that will be uniformly distributed among -bit integers with the least significant set bit on position . The probability that these bits are all 0's or all 1's is therefore at most 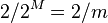 .
On the other hand, if
.
On the other hand, if 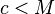 , then higher-order M bits of
contain both 0's and 1's, so
it is certain that
, then higher-order M bits of
contain both 0's and 1's, so
it is certain that 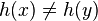 . Finally, if
. Finally, if 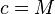 then bit
then bit  of
is 1 and
of
is 1 and 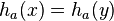 if and only if bits
if and only if bits 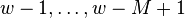 are also 1, which happens with probability
are also 1, which happens with probability 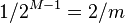 .
.
This analysis is tight, as can be shown with the example  and
and 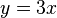 . To obtain a truly 'universal' hash function, one can use the multiply-add-shift scheme
. To obtain a truly 'universal' hash function, one can use the multiply-add-shift scheme
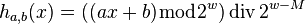
which can be implemented in C-like programming languages by
-
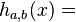
(unsigned) (a*x+b) >> (w-M)
where is a random odd positive integer with and is a random non-negative integer with 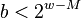 . With these choices of and ,
. With these choices of and , 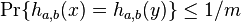 for all
for all 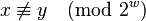 .[7] This differs slightly but importantly from the mistranslation in the English paper.[8]
.[7] This differs slightly but importantly from the mistranslation in the English paper.[8]
Hashing vectors
This section is concerned with hashing a fixed-length vector of machine words. Interpret the input as a vector 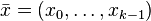 of
of 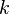 machine words (integers of bits each). If is a universal family with the uniform difference property, the following family (dating back to Carter and Wegman[1]) also has the uniform difference property (and hence is universal):
machine words (integers of bits each). If is a universal family with the uniform difference property, the following family (dating back to Carter and Wegman[1]) also has the uniform difference property (and hence is universal):
-
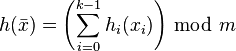 , where each
, where each 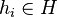 is chosen independently at random.
is chosen independently at random.
If is a power of two, one may replace summation by exclusive or.[9]
In practice, if double-precision arithmetic is available, this is instantiated with the multiply-shift hash family of.[10] Initialize the hash function with a vector 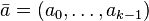 of random odd integers on
of random odd integers on 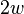 bits each. Then if the number of bins is for
bits each. Then if the number of bins is for  :
:
-
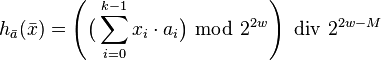 .
.
It is possible to halve the number of multiplications, which roughly translates to a two-fold speed-up in practice.[9] Initialize the hash function with a vector of random odd integers on bits each. The following hash family is universal:[11]
-
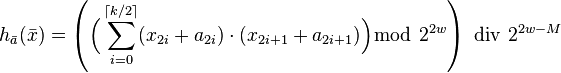 .
.
If double-precision operations are not available, one can interpret the input as a vector of half-words ( -bit integers). The algorithm will then use
-bit integers). The algorithm will then use 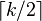 multiplications, where was the number of half-words in the vector. Thus, the algorithm runs at a "rate" of one multiplication per word of input.
multiplications, where was the number of half-words in the vector. Thus, the algorithm runs at a "rate" of one multiplication per word of input.
The same scheme can also be used for hashing integers, by interpreting their bits as vectors of bytes. In this variant, the vector technique is known as tabulation hashing and it provides a practical alternative to multiplication-based universal hashing schemes.[12]
Strong universality at high speed is also possible.[13] Initialize the hash function with a vector 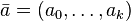 of random integers on bits. Compute
of random integers on bits. Compute
-
 .
.
The result is strongly universal on bits. Experimentally, it was found to run at 0.2 CPU cycle per byte on recent Intel processors for 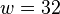 .
.
Hashing strings
This refers to hashing a variable-sized vector of machine words. If the length of the string can be bounded by a small number, it is best to use the vector solution from above (conceptually padding the vector with zeros up to the upper bound). The space required is the maximal length of the string, but the time to evaluate 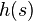 is just the length of
is just the length of  . As long as zeroes are forbidden in the string, the zero-padding can be ignored when evaluating the hash function without affecting universality[9]). Note that if zeroes are allowed in the string, then it might be best to append a fictitious non-zero (e.g., 1) character to all strings prior to padding: this will ensure that universality is not affected.[13]
. As long as zeroes are forbidden in the string, the zero-padding can be ignored when evaluating the hash function without affecting universality[9]). Note that if zeroes are allowed in the string, then it might be best to append a fictitious non-zero (e.g., 1) character to all strings prior to padding: this will ensure that universality is not affected.[13]
Now assume we want to hash 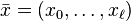 , where a good bound on
, where a good bound on 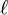 is not known a priori. A universal family proposed by [10]
treats the string as the coefficients of a polynomial modulo a large prime. If
is not known a priori. A universal family proposed by [10]
treats the string as the coefficients of a polynomial modulo a large prime. If ![x_i \in [u]](../I/m/172d10d5b2b0afb601ee9a6f2cacafcb.png) , let
, let 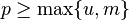 be a prime and define:
be a prime and define:
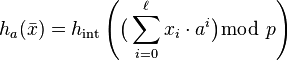 , where
, where ![a \in [p]](../I/m/cef7afeea1e6c15d42fae0eec49d4bd3.png) is uniformly random and
is uniformly random and 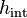 is chosen randomly from a universal family mapping integer domain
is chosen randomly from a universal family mapping integer domain ![[p] \mapsto [m]](../I/m/dfb85a19f2be89413dd0ccab187872b5.png) .
.
Using properties of modular arithmetic, above can be computed without producing large numbers for large strings as follows:[14]
int hash(String x, int a, int p) int h=x[0] for (int i=1 ; i < x.length ; i++) h = ((h*a) + x[i]) mod p return h
Consider two strings 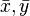 and let be length of the longer one; for the analysis, the shorter string is conceptually padded with zeros up to length . A collision before applying implies that is a root of the polynomial with coefficients
and let be length of the longer one; for the analysis, the shorter string is conceptually padded with zeros up to length . A collision before applying implies that is a root of the polynomial with coefficients 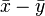 . This polynomial has at most roots modulo , so the collision probability is at most
. This polynomial has at most roots modulo , so the collision probability is at most 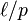 . The probability of collision through the random brings the total collision probability to
. The probability of collision through the random brings the total collision probability to 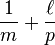 . Thus, if the prime is sufficiently large compared to the length of strings hashed, the family is very close to universal (in statistical distance).
. Thus, if the prime is sufficiently large compared to the length of strings hashed, the family is very close to universal (in statistical distance).
To mitigate the computational penalty of modular arithmetic, two tricks are used in practice:[9]
- One chooses the prime to be close to a power of two, such as a Mersenne prime. This allows arithmetic modulo to be implemented without division (using faster operations like addition and shifts). For instance, on modern architectures one can work with
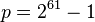 , while
, while 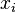 's are 32-bit values.
's are 32-bit values. - One can apply vector hashing to blocks. For instance, one applies vector hashing to each 16-word block of the string, and applies string hashing to the
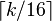 results. Since the slower string hashing is applied on a substantially smaller vector, this will essentially be as fast as vector hashing.
results. Since the slower string hashing is applied on a substantially smaller vector, this will essentially be as fast as vector hashing.
See also
- K-independent hashing
- Rolling hashing
- Tabulation hashing
- Min-wise independence
- Universal one-way hash function
- Low-discrepancy sequence
- Perfect hashing
References
- ↑ 1.0 1.1 1.2 Carter, Larry; Wegman, Mark N. (1979). "Universal Classes of Hash Functions". Journal of Computer and System Sciences 18 (2): 143–154. doi:10.1016/0022-0000(79)90044-8. Conference version in STOC'77.
- ↑ Miltersen, Peter Bro. "Universal Hashing" (PDF). Archived from the original on 24 June 2009.
- ↑ Motwani, Rajeev; Raghavan, Prabhakar (1995). Randomized Algorithms. Cambridge University Press. p. 221. ISBN 0-521-47465-5.
- ↑ 4.0 4.1 Baran, Ilya; Demaine, Erik D.; Pătraşcu, Mihai (2008). "Subquadratic Algorithms for 3SUM". Algorithmica 50 (4): 584–596. doi:10.1007/s00453-007-9036-3.
- ↑ Dietzfelbinger, Martin; Hagerup, Torben; Katajainen, Jyrki; Penttonen, Martti (1997). "A Reliable Randomized Algorithm for the Closest-Pair Problem" (Postscript). Journal of Algorithms 25 (1): 19–51. doi:10.1006/jagm.1997.0873. Retrieved 10 February 2011.
- ↑ Thorup, Mikkel. "Text-book algorithms at SODA".
- ↑ Woelfel, Philipp (2003). Über die Komplexität der Multiplikation in eingeschränkten Branchingprogrammmodellen (PDF) (Ph.D.). Universität Dortmund. Retrieved 18 September 2012.
- ↑ Woelfel, Philipp (1999). Efficient Strongly Universal and Optimally Universal Hashing (PDF). Mathematical Foundations of Computer Science 1999. LNCS 1672. pp. 262–272. doi:10.1007/3-540-48340-3_24. Retrieved 17 May 2011.
- ↑ 9.0 9.1 9.2 9.3 Thorup, Mikkel (2009). String hashing for linear probing. Proc. 20th ACM-SIAM Symposium on Discrete Algorithms (SODA): 655–664., section 5.3
- ↑ 10.0 10.1 Dietzfelbinger, Martin; Gil, Joseph; Matias, Yossi; Pippenger, Nicholas (1992). Polynomial Hash Functions Are Reliable (Extended Abstract). Proc. 19th International Colloquium on Automata, Languages and Programming (ICALP): 235–246.
- ↑ Black, J.; Halevi, S.; Krawczyk, H.; Krovetz, T. (1999). UMAC: Fast and Secure Message Authentication. Advances in Cryptology (CRYPTO '99)., Equation 1
- ↑ Pătraşcu, Mihai; Thorup, Mikkel (2011). The power of simple tabulation hashing. Proceedings of the 43rd annual ACM Symposium on Theory of Computing (STOC '11): 1–10. arXiv:1011.5200. doi:10.1145/1993636.1993638.
- ↑ 13.0 13.1 Kaser, Owen; Lemire, Daniel (2013). "Strongly universal string hashing is fast". Computer Journal (Oxford University Press). arXiv:1202.4961. doi:10.1093/comjnl/bxt070.
- ↑ "Hebrew University Course Slides".
Further reading
- Knuth, Donald Ervin (1998). The Art of Computer Programming, Vol. III: Sorting and Searching (3rd ed.). Reading, Mass; London: Addison-Wesley. ISBN 0-201-89685-0.