Uniformly most powerful test
In statistical hypothesis testing, a uniformly most powerful (UMP) test is a hypothesis test which has the greatest power 1 − β among all possible tests of a given size α. For example, according to the Neyman–Pearson lemma, the likelihood-ratio test is UMP for testing simple (point) hypotheses.
Setting
Let 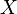 denote a random vector (corresponding to the measurements), taken from a parametrized family of probability density functions or probability mass functions
denote a random vector (corresponding to the measurements), taken from a parametrized family of probability density functions or probability mass functions 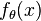 , which depends on the unknown deterministic parameter
, which depends on the unknown deterministic parameter 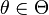 . The parameter space
. The parameter space 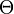 is partitioned into two disjoint sets
is partitioned into two disjoint sets 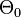 and
and 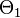 . Let
. Let 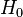 denote the hypothesis that
denote the hypothesis that 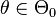 , and let
, and let 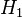 denote the hypothesis that
denote the hypothesis that 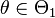 .
The binary test of hypotheses is performed using a test function
.
The binary test of hypotheses is performed using a test function 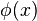 .
.
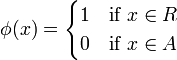
meaning that is in force if the measurement 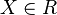 and that is in force if the measurement
and that is in force if the measurement 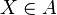 .
Note that
.
Note that 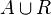 is a disjoint covering of the measurement space.
is a disjoint covering of the measurement space.
Formal definition
A test function is UMP of size 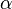 if for any other test function
if for any other test function 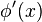 satisfying
satisfying
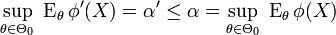
we have
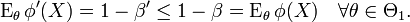
The Karlin-Rubin theorem
The Karlin-Rubin theorem[1] can be regarded as an extension of the Neyman-Pearson lemma for composite hypotheses. Consider a scalar measurement having a probability density function parameterized by a scalar parameter θ, and define the likelihood ratio 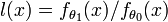 .
If
.
If 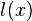 is monotone non-decreasing, in
is monotone non-decreasing, in 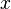 , for any pair
, for any pair 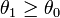 (meaning that the greater is, the more likely is), then the threshold test:
(meaning that the greater is, the more likely is), then the threshold test:
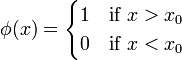
- where
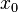 is chosen such that
is chosen such that 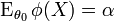
is the UMP test of size α for testing 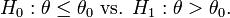
Note that exactly the same test is also UMP for testing 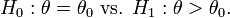
Important case: The exponential family
Although the Karlin-Rubin theorem may seem weak because of its restriction to scalar parameter and scalar measurement, it turns out that there exist a host of problems for which the theorem holds. In particular, the one-dimensional exponential family of probability density functions or probability mass functions with
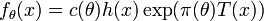
has a monotone non-decreasing likelihood ratio in the sufficient statistic T(x), provided that 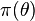 is non-decreasing.
is non-decreasing.
Example
Let 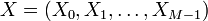 denote i.i.d. normally distributed
denote i.i.d. normally distributed  -dimensional random vectors with mean
-dimensional random vectors with mean 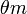 and covariance matrix
and covariance matrix 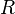 . We then have
. We then have
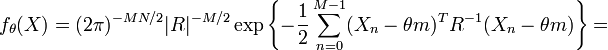
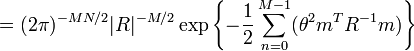
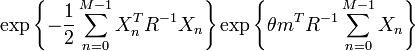
which is exactly in the form of the exponential family shown in the previous section, with the sufficient statistic being
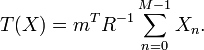
Thus, we conclude that the test
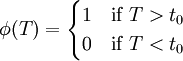
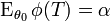
is the UMP test of size for testing 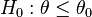 vs.
vs. 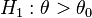
Further discussion
Finally, we note that in general, UMP tests do not exist for vector parameters or for two-sided tests (a test in which one hypothesis lies on both sides of the alternative). Why is it so?
The reason is that in these situations, the most powerful test of a given size for one possible value of the parameter (e.g. for 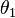 where
where 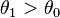 ) is different from the most powerful test of the same size for a different value of the parameter (e.g. for
) is different from the most powerful test of the same size for a different value of the parameter (e.g. for 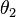 where
where 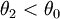 ). As a result, no test is uniformly most powerful.
). As a result, no test is uniformly most powerful.
References
- ↑ Casella, G.; Berger, R.L. (2008), Statistical Inference, Brooks/Cole. ISBN 0-495-39187-5 (Theorem 8.3.17)
Further reading
- L. L. Scharf, Statistical Signal Processing, Addison-Wesley, 1991, section 4.7.