Unification (computer science)
Unification, in computer science and logic, is an algorithmic process of solving equations between symbolic expressions.
Depending on which expressions (also called terms) are allowed to occur in an equation set (also called unification problem), and which expressions are considered equal, several frameworks of unification are distinguished. If higher-order variables, that is, variables representing functions, are allowed in an expression, the process is called higher-order unification, otherwise first-order unification. If a solution is required to make both sides of each equation literally equal, the process is called syntactical unification, otherwise semantical, or equational unification, or E-unification, or unification modulo theory.
A solution of a unification problem is denoted as a substitution, that is, a mapping assigning a symbolic value to each variable of the problem's expressions. A unification algorithm should compute for a given problem a complete, and minimal substitution set, that is, a set covering all its solutions, and containing no redundant members. Depending on the framework, a complete and minimal substitution set may have at most one, at most finitely many, or possibly infinitely many members, or may not exist at all.[note 1][1] In some frameworks it is generally impossible to decide whether any solution exists. For first-order syntactical unification, Martelli and Montanari[2] gave an algorithm that reports unsolvability or computes a complete and minimal singleton substitution set containing the so-called most general unifier.
For example, using x,y,z as variables, the singleton equation set { cons(x,cons(x,nil)) = cons(2,y) } is a syntactic first-order unification problem that has the substitution { x ↦ 2, y ↦ cons(2,nil) } as its only solution. The syntactic first-order unification problem { y = cons(2,y) } has no solution over the set of finite terms; however, it has the single solution { y ↦ cons(2,cons(2,cons(2,...))) } over the set of infinite trees. The semantic first-order unification problem { a⋅x = x⋅a } has each substitution of the form { x ↦ a⋅...⋅a } as a solution in a semigroup, i.e. if (⋅) is considered associative; the same problem, viewed in an abelian group, where (⋅) is considered also commutative, has any substitution at all as a solution. The singleton set { a = y(x) } is a syntactic second-order unification problem, since y is a function variable. One solution is { x ↦ a, y ↦ (identity function) }; another one is { y ↦ (constant function mapping each value to a), x ↦ (any value) }.
The first formal investigation of unification can be attributed to John Alan Robinson,[3][4] who used first-order syntactical unification as a basic building block of his resolution procedure for first-order logic, a great step forward in automated reasoning technology, as it eliminated one source of combinatorial explosion: searching for instantiation of terms. Today, automated reasoning is still the main application area of unification. Syntactical first-order unification is used in logic programming and programming language type system implementation, especially in Hindley–Milner based type inference algorithms. Semantic unification is used in SMT solvers and term rewriting algorithms. Higher-order unification is used in proof assistants, for example Isabelle and Twelf, and restricted forms of higher-order unification (higher-order pattern unification) are used in some programming language implementations, such as lambdaProlog, as higher-order patterns are expressive, yet their associated unification procedure retains theoretical properties closer to first-order unification.
Common formal definitions
Prerequisites
Formally, a unification approach presupposes
- An infinite set V of variables. For higher-order unification, it is convenient to choose V disjoint from the set of lambda-term bound variables.
- A set T of terms such that V ⊆ T. For first-order unification and higher-order unification, T is usually the set of first-order terms (terms built from variable and function symbols) and lambda terms (terms containing some higher-order variables), respectively.
- A mapping vars: T → ℙ(V), assigning to each term t the set vars(t) ⊊ V of free variables occurring in t.
- An equivalence relation ≡ on T, indicating which terms are considered equal. For higher-order unification, usually t ≡ u if t and u are alpha equivalent. For first-order E-unification, ≡ reflects the background knowledge about certain function symbols; for example, if ⊕ is considered commutative, t ≡ u if u results from t by swapping the arguments of ⊕ at some (possibly all) occurrences. [note 2] If there is no background knowledge at all, then only literally, or syntactically, identical terms are considered equal; in this case, ≡ is called the free theory (because it is a free object), the empty theory (because the set of equational sentences, or the background knowledge, is empty), the theory of uninterpreted functions (because unification is done on uninterpreted terms), or the theory of constructors (because all function symbols just build up data terms, rather than operating on them).
First-order term
Given a set V of variable symbols, a set C of constant symbols and sets Fn of n-ary function symbols, also called operator symbols, for each natural number n ≥ 1, the set of (unsorted first-order) terms T is recursively defined to be the smallest set with the following properties:[5]
- every variable symbol is a term: V ⊆ T,
- every constant symbol is a term: C ⊆ T,
- from every n terms t1,...,tn, and every n-ary function symbol f ∈ Fn, a larger term f(t1,...,tn) can be built.
For example, if x ∈ V is a variable symbol, 1 ∈ C is a constant symbol, and add ∈ F2 is a binary function symbol, then x ∈ T, 1 ∈ T, and (hence) add(x,1) ∈ T by the first, second, and third term building rule, respectively. The latter term is usually written as x+1, using infix notation and the more common operator symbol + for convenience.
Higher-order term
Substitution
A substitution is a mapping σ: V → T from variables to terms; the notation { x1 ↦ t1, ..., xk ↦ tk } refers to a substitution mapping each variable xi to the term ti, for i=1,...,k, and every other variable to itself. Applying that substitution to a term t is written in postfix notation as t {x1 ↦ t1, ..., xk ↦ tk}; it means to (simultaneously) replace every occurrence of each variable xi in the term t by ti. The result tσ of applying a substitution σ to a term t is called an instance of that term t. As a first-order example, applying the substitution { x ↦ h(a,y), z ↦ b } to the term
| f( | x | , a, g( | z | ), y) | |
| yields | |||||
| f( | h(a,y) | , a, g( | b | ), y). |
Generalization, specialization
If a term t has an instance equivalent to a term u, that is, if tσ ≡ u for some substitution σ, then t is called more general than u, and u is called more special than, or subsumed by, t. For example, x ⊕ a is more general than a ⊕ b if ⊕ is commutative, since then (x ⊕ a) {x↦b} = b ⊕ a ≡ a ⊕ b.
If ≡ is literal (syntactic) identity of terms, a term may be both more general and more special than another one only if both terms differ just in their variable names, not in their syntactic structure; such terms are called variants, or renamings of each other. For example, f(x1,a,g(z1),y1) is a variant of f(x2,a,g(z2),y2), since f(x1,a,g(z1),y1) { x1 ↦ x2, y1 ↦ y2, z1 ↦ z2 } = f(x2,a,g(z2),y2) and f(x2,a,g(z2),y2) { x2 ↦ x1, y2 ↦ y1, z2 ↦ z1 } = f(x1,a,g(z1),y1). However, f(x1,a,g(z1),y1) is not a variant of f(x2,a,g(x2),x2), since no substitution can transform the latter term into the former one. The latter term is therefore properly more special than the former one.
For arbitrary ≡, a term may be both more general and more special than a structurally different term. For example, if ⊕ is idempotent, that is, if always x ⊕ x ≡ x, then the term x ⊕ y is more general than (x ⊕ y) {x ↦ z, y ↦ z} = z ⊕ z ≡ z, and vice versa z is more general than z {z ↦ x ⊕ y} = x ⊕ y, although x⊕y and z are of different structure.
A substitution σ is more special than, or subsumed by, a substitution τ if xσ is more special than xτ for each variable x. For example, { x ↦ f(u), y ↦ f(f(u)) } is more special than { x ↦ z, y ↦ f(z) }, since f(u) and f(f(u)) is more special than z and f(z), respectively.
Unification problem, solution set
A unification problem is a finite set { l1 ≐ r1, ..., ln ≐ rn } of potential equations, where li, ri ∈ T. A substitution σ is a solution of that problem if liσ ≡ riσ for i=1,...,n. Such a substitution is also called a unifier of the unification problem. For example, if ⊕ is associative, the unification problem { x ⊕ a ≐ a ⊕ x } has the solutions {x ↦ a}, {x ↦ a ⊕ a}, {x ↦ a ⊕ a ⊕ a}, etc., while the problem { x ⊕ a ≐ a } has no solution.
For a given unification problem, a set S of unifiers is called complete if each solution substitution is subsumed by some substitution σ ∈ S; the set S is called minimal if none of its members subsumes another one.
Syntactic unification of first-order terms
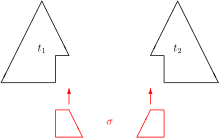
Syntactic unification of first-order terms is the most widely used unification framework. It is based on T being the set of first-order terms (over some given set V of variables, C of constants and Fn of n-ary function symbols) and on ≡ being syntactic equality. In this framework, each solvable unification problem {l1 ≐ r1, ..., ln ≐ rn} has a complete, and obviously minimal, singleton solution set {σ}. Its member σ is called the most general unifier (mgu) of the problem. The terms on the left and the right hand side of each potential equation become syntactically equal when the mgu is applied i.e. l1σ = r1σ ∧ ... ∧ lnσ = rnσ. Any unifier of the problem is subsumed[note 3] by the mgu σ. The mgu is unique up to variants: if S1 and S2 are both complete and minimal solution sets of the same syntactical unification problem, then S1 = { σ1 } and S2 = { σ2 } for some substitutions σ1 and σ2, and xσ1 is a variant of xσ2 for each variable x occurring in the problem.
For example, the unification problem { x ≐ z, y ≐ f(x) } has a unifier { x ↦ z, y ↦ f(z) }, because
| x | { x ↦ z, y ↦ f(z) } | = | z | = | z | { x ↦ z, y ↦ f(z) } | , and |
| y | { x ↦ z, y ↦ f(z) } | = | f(z) | = | f(x) | { x ↦ z, y ↦ f(z) } | . |
This is also the most general unifier. Other unifiers for the same problem are e.g. { x ↦ f(x1), y ↦ f(f(x1)), z ↦ f(x1) }, { x ↦ f(f(x1)), y ↦ f(f(f(x1))), z ↦ f(f(x1)) }, and so on; there are infinitely many similar unifiers.
As another example, the problem g(x,x) ≐ f(y) has no solution with respect to ≡ being literal identity, since any substitution applied to the left and right hand side will keep the outermost g and f, respectively, and terms with different outermost function symbols are syntactically different.
A unification algorithm
| Robinson's 1965 unification algorithm | ||
|---|---|---|
| Symbols are ordered such that variables precede function symbols. | ||
| Terms are ordered by increasing written length; equally long terms | ||
| are ordered lexicographically.[6] For a set T of terms, its disagreement | ||
| path p is the lexicographically least path where two member terms | ||
| of T differ. Its disagreement set is the set of subterms starting at p, | ||
| formally: { t|p : t∈T }.[7] | ||
| Algorithm:[8] | ||
| Given a set T of terms to be unified | ||
| Let σ initially be the identity substitution | ||
| do forever | ||
| if | Tσ is a singleton set | |
| then | return σ | |
| fi | ||
| let D be the disagreement set of Tσ | ||
| let s, t be the two lexicographically least terms in D | ||
| If | s is not a variable or s occurs in t | |
| else | return "NONUNIFIABLE" | |
| fi | ||
| σ := σ { s↦t } | ||
| done | ||
The first algorithm given by Robinson (1965) was rather inefficient; cf. box. The following faster algorithm originated from Martelli, Montanari (1982).[9] This paper also lists preceding attempts to find an efficient syntactical unification algorithm,[10][11][12][13][14][15] and states that linear-time algorithms were discovered independently by Martelli, Montanari (1976)[12] and Paterson, Wegman (1978).[13][16]
Given a finite set G = { s1 ≐ t1, ..., sn ≐ tn } of potential equations, the algorithm applies rules to transform it to an equivalent set of equations of the form { x1 ≐ u1, ..., xm ≐ um } where x1, ..., xm are distinct variables and u1, ..., um are terms containing none of the xi. A set of this form can be read as a substitution. If there is no solution the algorithm terminates with ⊥; other authors use "Ω", "{}", or "fail" in that case. The operation of substituting all occurrences of variable x in problem G with term t is denoted G {x ↦ t}. For simplicity, constant symbols are regarded as function symbols having zero arguments.
| G ∪ { t ≐ t } | ⇒ | G | delete | |
| G ∪ { f(s0,...,sk) ≐ f(t0,...,tk) } | ⇒ | G ∪ { s0 ≐ t0, ..., sk ≐ tk } | decompose | |
| G ∪ { f(s0,...,sk) ≐ g(t0,...,tm) } | ⇒ | ⊥ | if f ≠ g or k ≠ m | conflict |
| G ∪ { f(s0,...,sk) ≐ x } | ⇒ | G ∪ { x ≐ f(s0,...,sk) } | swap | |
| G ∪ { x ≐ t } | ⇒ | G{x↦t} ∪ { x ≐ t } | if x ∉ vars(t) and x ∈ vars(G) | eliminate |
| G ∪ { x ≐ f(s0,...,sk) } | ⇒ | ⊥ | if x ∈ vars(f(s0,...,sk)) | check |
Occurs check
An attempt to unify a variable x with a term containing x as a strict subterm x≐f(...,x,...) would lead to an infinite term as solution for x, since x would occur as a subterm of itself. In the set of (finite) first-order terms as defined above, the equation x≐f(...,x,...) has no solution; hence the eliminate rule may only be applied if x ∉ vars(t). Since that additional check, called occurs check, slows down the algorithm, it is omitted e.g. in most Prolog systems. From a theoretical point of view, omitting the check amounts to solving equations over infinite trees, see below.
Proof of termination
For the proof of termination of the algorithm consider a triple <nvar,nlhs,neqn> where nvar is the number of variables that occur more than once in the equation set, nlhs is the number of function symbols and constants on the left hand sides of potential equations, and neqn is the number of equations. When rule eliminate is applied, nvar decreases, since x is eliminated from G and kept only in { x ≐ t }. Applying any other rule can never increase nvar again. When rule decompose, conflict, or swap is applied, nlhs decreases, since at least the left hand side's outermost f disappears. Applying any of the remaining rules delete or check can't increase nlhs, but decreases neqn. Hence, any rule application decreases the triple <nvar,nlhs,neqn> with respect to the lexicographical order, which is possible only a finite number of times.
Conor McBride observes[17] that “by expressing the structure which unification exploits” in a dependently typed language such as Epigram, Robinson's algorithm can be made recursive on the number of variables, in which case a separate termination proof becomes unnecessary.
Examples of syntactic unification of first-order terms
In the Prolog syntactical convention a symbol starting with an upper case letter is a variable name; a symbol that starts with a lowercase letter is a function symbol; the comma is used as the logical and operator. For maths notation, x,y,z are used as variables, f,g as function symbols, and a,b as constants.
| Prolog Notation | Maths Notation | Unifying Substitution | Explanation |
|---|---|---|---|
| a = a | { a = a } | {} | Succeeds. (tautology) |
| a = b | { a = b } | ⊥ | a and b do not match |
| X = X | { x = x } | {} | Succeeds. (tautology) |
| a = X | { a = x } | { x ↦ a } | x is unified with the constant a |
| X = Y | { x = y } | { x ↦ y } | x and y are aliased |
| f(a,X) = f(a,b) | { f(a,x) = f(a,b) } | { x ↦ b } | function and constant symbols match, x is unified with the constant b |
| f(a) = g(a) | { f(a) = g(a) } | ⊥ | f and g do not match |
| f(X) = f(Y) | { f(x) = f(y) } | { x ↦ y } | x and y are aliased |
| f(X) = g(Y) | { f(x) = g(y) } | ⊥ | f and g do not match |
| f(X) = f(Y,Z) | { f(x) = f(y,z) } | ⊥ | Fails. The f function symbols have different arity |
| f(g(X)) = f(Y) | { f(g(x)) = f(y) } | { y ↦ g(x) } | Unifies y with the term g(x) |
| f(g(X),X) = f(Y,a) | { f(g(x),x) = f(y,a) } | { x ↦ a, y ↦ g(a) } | Unifies x with constant a, and y with the term g(a) |
| X = f(X) | { x = f(x) } | should be ⊥ | Returns ⊥ in first-order logic and many modern Prolog dialects (enforced by the occurs check).
Succeeds in traditional Prolog and in Prolog II, unifying x with infinite term x=f(f(f(f(...)))). |
| X = Y, Y = a | { x = y, y = a } | { x ↦ a, y ↦ a } | Both x and y are unified with the constant a |
| a = Y, X = Y | { a = y, x = y } | { x ↦ a, y ↦ a } | As above (order of equations in set doesn't matter) |
| X = a, b = X | { x = a, b = x } | ⊥ | Fails. a and b do not match, so x can't be unified with both |

The most general unifier of a syntactic first-order unification problem of size n may have a size of 2n. For example, the problem { (((a*z)*y)*x)*w ≐ w*(x*(y*(z*a))) } has the most general unifier { z ↦ a, y ↦ a*a, x ↦ (a*a)*(a*a), w ↦ ((a*a)*(a*a))*((a*a)*(a*a)) }, cf. picture. In order to avoid exponential time complexity caused by such blow-up, advanced unification algorithms work on directed acyclic graphs (dags) rather than trees.[18]
Application: Unification in logic programming
The concept of unification is one of the main ideas behind logic programming, best known through the language Prolog. It represents the mechanism of binding the contents of variables and can be viewed as a kind of one-time assignment. In Prolog, this operation is denoted by the equality symbol =, but is also done when instantiating variables (see below). It is also used in other languages by the use of the equality symbol =, but also in conjunction with many operations including +, -, *, /. Type inference algorithms are typically based on unification.
In Prolog:
- A variable which is uninstantiated—i.e. no previous unifications were performed on it—can be unified with an atom, a term, or another uninstantiated variable, thus effectively becoming its alias. In many modern Prolog dialects and in first-order logic, a variable cannot be unified with a term that contains it; this is the so-called occurs check.
- Two atoms can only be unified if they are identical.
- Similarly, a term can be unified with another term if the top function symbols and arities of the terms are identical and if the parameters can be unified simultaneously. Note that this is a recursive behavior.
Application: Type inference
Unification is used during type inference, for instance in the functional programming language Haskell. On one hand, the programmer does not need to provide type information for every function, on the other hand it is used to detect typing errors. The Haskell expression 1:['a','b','c'] is not correctly typed, because the list construction function ":" is of type a->[a]->[a] and for the first argument "1" the polymorphic type variable "a" has to denote the type Int whereas "['a','b','c']" is of type [Char], but "a" cannot be both Char and Int at the same time.
Like for prolog an algorithm for type inference can be given:
- Any type variable unifies with any type expression, and is instantiated to that expression. A specific theory might restrict this rule with an occurs check.
- Two type constants unify only if they are the same type.
- Two type constructions unify only if they are applications of the same type constructor and all of their component types recursively unify.
Due to its declarative nature, the order in a sequence of unifications is (usually) unimportant.
Note that in the terminology of first-order logic, an atom is a basic proposition and is unified similarly to a Prolog term.
Order-sorted unification
Order-sorted logic allows one to assign a sort, or type, to each term, and to declare a sort s1 a subsort of another sort s2, commonly written as s1 ⊆ s2. For example, when reаsoning about biological creatures, it is useful to declare a sort dog to be a subsort of a sort animal. Wherever a term of some sort s is required, a term of any subsort of s may be supplied instead. For example, assuming a function declaration mother: animal → animal, and a constant declaration lassie: dog, the term mother(lassie) is perfectly valid and has the sort animal. In order to supply the information that the mother of a dog is a dog in turn, another declaration mother: dog → dog may be issued; this is called function overloading, similar to overloading in programming languages.
Walther gave a unification algorithm for terms in order-sorted logic, requiring for any two declared sorts s1, s2 their intersection s1 ∩ s2 to be declared, too: if x1 and x2 is a variable of sort s1 and s2, respectively, the equation x1 ≐ x2 has the solution { x1 = x, x2 = x }, where x: s1 ∩ s2. [19] After incorporating this algorithm into a clause-based automated theorem prover, he could solve a benchmark problem by translating it into order-sorted logic, thereby boiling it down an order of magnitude, as many unary predicates turned into sorts.
Smolka generalized order-sorted logic to allow for parametric polymorphism. [20] In his framework, subsort declarations are propagated to complex type expressions. As a programming example, a parametric sort list(X) may be declared (with X being a type parameter as in a C++ template), and from a subsort declaration int ⊆ float the relation list(int) ⊆ list(float) is automatically inferred, meaning that each list of integers is also a list of floats.
Schmidt-Schauß generalized order-sorted logic to allow for term declarations. [21] As an example, assuming subsort declarations even ⊆ int and odd ⊆ int, a term declaration like ∀i:int. (i+i):even allows to declare a property of integer addition that could not be expressed by ordinary overloading.
Unification of infinite terms
Background on infinite trees:
- B. Courcelle (1983). "Fundamental Properties of Infinite Trees" (PDF). Theoret. Comput. Sci. 25: 95–169. doi:10.1016/0304-3975(83)90059-2.
- Michael J. Maher (Jul 1988). "Complete Axiomatizations of the Algebras of Finite, Rational and Infinite Trees". Proc. IEEE 3rd Annual Symp. on Logic in Computer Science, Edinburgh. pp. 348–357.
- Joxan Jaffar, Peter J. Stuckey (1986). "Semantics of Infinite Tree Logic Programming". Theoretical Computer Science 46: 141–158. doi:10.1016/0304-3975(86)90027-7.
Unification algorithm, Prolog II:
- A. Colmerauer (1982). K.L. Clark and S.-A. Tarnlund, ed. Prolog and Infinite Trees. Academic Press.
- Alain Colmerauer (1984). "Equations and Inequations on Finite and Infinite Trees". In ICOT. Proc. Int. Conf. on Fifth Generation Computer Systems. pp. 85–99.
Applications:
- Francis Giannesini, Jacques Cohen (1984). "Parser Generation and Grammar Manipulation using Prolog's Infinite Trees". J. Logic Programming 3: 253–265.
E-unification
E-unification is the problem of finding solutions to a given set of equations, taking into account some equational background knowledge E. The latter is given as a set of universal equalities. For some particular sets E, equation solving algorithms (a.k.a. E-unification algorithms) have been devised; for others it has been proven that no such algorithms can exist.
For example, if a and b are distinct constants, the equation x*a ≐ y*b has no solution with respect to purely syntactic unification, where nothing is known about the operator *. However, if the * is known to be commutative, then the substitution { x ↦ b, y ↦ a } solves the above equation, since
| x*a | {x ↦ b, y ↦ a} | ||
| = | b*a | by substitution application | |
| = | a*b | by commutativity of * | |
| = | y*b | {x ↦ b, y ↦ a} | by (converse) substitution application |
The background knowledge E could state the commutativity of * by the universal equality "u*v = v*u for all u, v".
Particular background knowledge sets E
| ∀ u,v,w: | u*(v*w) | = | (u*v)*w | A | Associativity of * |
| ∀ u,v: | u*v | = | v*u | C | Commutativity of * |
| ∀ u,v,w: | u*(v+w) | = | u*v+u*w | Dl | Left distributivity of * over + |
| ∀ u,v,w: | (v+w)*u | = | v*u+w*u | Dr | Right distributivity of * over + |
| ∀ u: | u*u | = | u | I | Idempotence of * |
| ∀ u: | n*u | = | u | Nl | Left neutral element n with respect to * |
| ∀ u: | u*n | = | u | Nr | Right neutral element n with respect to * |
It is said that unification is decidable for a theory, if a unification algorithm has been devised for it that terminates for any input problem. It is said that unification is semi-decidable for a theory, if a unification algorithm has been devised for it that terminates for any solvable input problem, but may keep searching forever for solutions of an unsolvable input problem.
Unification is decidable for the following theories:
- A[22]
- A,C[23]
- A,C,I[24]
- A,C,Nl[note 4][24]
- A,I[25]
- A,Nl,Nr (monoid)[26]
- C[27]
- Boolean rings[28][29]
- Abelian groups, even if the signature is expanded by arbitrary additional symbols (but not axioms)[30]
- K4 modal algebras[31]
Unification is semi-decidable for the following theories:
- A,Dl,Dr[32]
- A,C,Dl[note 4][33]
- Commutative rings[30]
One-sided paramodulation
If there is a convergent term rewriting system R available for E, the one-sided paramodulation algorithm[34] can be used to enumerate all solutions of given equations.
| G ∪ { f(s1,...,sn) ≐ f(t1,...,tn) } | ; S | ⇒ | G ∪ { s1 ≐ t1, ..., sn ≐ tn } | ; S | decompose | |
| G ∪ { x ≐ t } | ; S | ⇒ | G { x ↦ t } | ; S{x↦t} ∪ {x↦t} | if the variable x doesn't occur in t | eliminate |
| G ∪ { f(s1,...,sn) ≐ t } | ; S | ⇒ | G ∪ { s1 ≐ u1, ..., sn ≐ un, r ≐ t } | ; S | if f(u1,...,un) → r is a rule from R | mutate |
| G ∪ { f(s1,...,sn) ≐ y } | ; S | ⇒ | G ∪ { s1 ≐ y1, ..., sn ≐ yn, y ≐ f(y1,...,yn) } | ; S | if y1,...,yn are new variables | imitate |
Starting with G being the unification problem to be solved and S being the identity substitution, rules are applied nondeterministically until the empty set appears as the actual G, in which case the actual S is a unifying substitution. Depending on the order the paramodulation rules are applied, on the choice of the actual equation from G, and on the choice of R’s rules in mutate, different computations paths are possible. Only some lead to a solution, while others end at a G ≠ {} where no further rule is applicable (e.g. G = { f(...) ≐ g(...) }).
| 1 | app(nil,z) | → z |
| 2 | app(x.y,z) | → x.app(y,z) |
For an example, a term rewrite system R is used defining the append operator of lists built from cons and nil; where cons(x,y) is written in infix notation as x.y for brevity; e.g. app(a.b.nil,c.d.nil) → a.app(b.nil,c.d.nil) → a.b.app(nil,c.d.nil) → a.b.c.d.nil demonstrates the concatenation of the lists a.b.nil and c.d.nil, employing the rewrite rule 2,2, and 1. The equational theory E corresponding to R is the congruence closure of R, both viewed as binary relations on terms. For example, app(a.b.nil,c.d.nil) ≡ a.b.c.d.nil ≡ app(a.b.c.d.nil,nil). The paramodulation algorithm enumerates solutions to equations with respect to that E when fed with the example R.
A successful example computation path for the unification problem { app(x,app(y,x)) ≐ a.a.nil } is shown below. To avoid variable name clashes, rewrite rules are consistently renamed each time before their use by rule mutate; v2, v3, ... are computer-generated variable names for this purpose. In each line, the chosen equation from G is highlighted in red. Each time the mutate rule is applied, the chosen rewrite rule (1 or 2) is indicated in parentheses. From the last line, the unifying substitution S = { y ↦ nil, x ↦ a.nil } can be obtained. In fact, app(x,app(y,x)) {y↦nil, x↦ a.nil } = app(a.nil,app(nil,a.nil)) ≡ app(a.nil,a.nil) ≡ a.app(nil,a.nil) ≡ a.a.nil solves the given problem. A second successful computation path, obtainable by choosing "mutate(1), mutate(2), mutate(2), mutate(1)" leads to the substitution S = { y ↦ a.a.nil, x ↦ nil }; it is not shown here. No other path leads to a success.
| Used rule | G | S | |
|---|---|---|---|
| { app(x,app(y,x)) ≐ a.a.nil } | {} | ||
| mutate(2) | ⇒ | { x ≐ v2.v3, app(y,x) ≐ v4, v2.app(v3,v4) ≐ a.a.nil } | {} |
| decompose | ⇒ | { x ≐ v2.v3, app(y,x) ≐ v4, v2 ≐ a, app(v3,v4) ≐ a.nil } | {} |
| eliminate | ⇒ | { app(y,v2.v3) ≐ v4, v2 ≐ a, app(v3,v4) ≐ a.nil } | { x ↦ v2.v3 } |
| eliminate | ⇒ | { app(y,a.v3) ≐ v4, app(v3,v4) ≐ a.nil } | { x ↦ a.v3 } |
| mutate(1) | ⇒ | { y ≐ nil, a.v3 ≐ v5, v5 ≐ v4, app(v3,v4) ≐ a.nil } | { x ↦ a.v3 } |
| eliminate | ⇒ | { y ≐ nil, a.v3 ≐ v4, app(v3,v4) ≐ a.nil } | { x ↦ a.v3 } |
| eliminate | ⇒ | { a.v3 ≐ v4, app(v3,v4) ≐ a.nil } | { y ↦ nil, x ↦ a.v3 } |
| mutate(1) | ⇒ | { a.v3 ≐ v4, v3 ≐ nil, v4 ≐ v6, v6 ≐ a.nil } | { y ↦ nil, x ↦ a.v3 } |
| eliminate | ⇒ | { a.v3 ≐ v4, v3 ≐ nil, v4 ≐ a.nil } | { y ↦ nil, x ↦ a.v3 } |
| eliminate | ⇒ | { a.nil ≐ v4, v4 ≐ a.nil } | { y ↦ nil, x ↦ a.nil } |
| eliminate | ⇒ | { a.nil ≐ a.nil } | { y ↦ nil, x ↦ a.nil } |
| decompose | ⇒ | { a ≐ a, nil ≐ nil } | { y ↦ nil, x ↦ a.nil } |
| decompose | ⇒ | { nil ≐ nil } | { y ↦ nil, x ↦ a.nil } |
| decompose | ⇒ | {} | { y ↦ nil, x ↦ a.nil } |
Narrowing
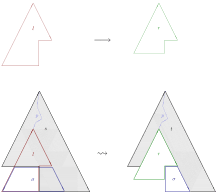
If R is a convergent term rewriting system for E, an approach alternative to the previous section consists in successive application of "narrowing steps"; this will eventually enumerate all solutions of a given equation. A narrowing step (cf. picture) consists in
- choosing a nonvariable subterm of the current term,
- syntactically unifying it with the left hand side of a rule from R, and
- replacing the instantiated rule's right hand side into the instantiated term.
Formally, if l → r is a renamed copy of a rewrite rule from R, having no variables in common with a term s, and the subterm s|p is not a variable and is unifiable with l via the mgu σ, then s can be narrowed to the term t = sσ[rσ]p, i.e. to the term sσ, with the subterm at p replaced by rσ. The situation that s can be narrowed to t is commonly denoted as s ~› t. Intuitively, a sequence of narrowing steps t1 ~› t2 ~› ... ~› tn can be thought of as a sequence of rewrite steps t1 → t2 → ... → tn, but with the initial term t1 being further and further instantiated, as necessary to make each of the used rules applicable.
The above example paramodulation computation corresponds to the following narrowing sequence ("↓" indicating instatiation here):
| app( | x | ,app(y, | x | )) | |||||||||||||
| ↓ | ↓ | x ↦ v2.v3 | |||||||||||||||
| app( | v2.v3 | ,app(y, | v2.v3 | )) | → | v2.app(v3,app( | y | ,v2.v3)) | |||||||||
| ↓ | y ↦ nil | ||||||||||||||||
| v2.app(v3,app( | nil | ,v2.v3)) | → | v2.app( | v3 | ,v2. | v3 | ) | |||||||||
| ↓ | ↓ | v3 ↦ nil | |||||||||||||||
| v2.app( | nil | ,v2. | nil | ) | → | v2.v2.nil |
The last term, v2.v2.nil can be syntactically unified with the original right hand side term a.a.nil.
The narrowing lemma[35] ensures that whenever an instance of a term s can be rewritten to a term t by a convergent term rewriting system, then s and t can be narrowed and rewritten to a term s’ and t’, respectively, such that t’ is an instance of s’. Formally: whenever sσ →* t holds for some substitution σ, then there exist terms s’, t’ such that s ~›* s’ and t →* t’ and s’τ = t’ for some substitution τ.
Higher-order unification
Many applications require one to consider the unification of typed lambda-terms instead of first-order terms. Such unification is often called higher-order unification. A well studied branch of higher-order unification is the problem of unifying simply typed lambda terms modulo the equality determined by αβη conversions. Such unification problems do not have most general unifiers. While higher-order unification is undecidable,[36][37][38] Gérard Huet gave a semi-decidable (pre-)unification algorithm[39] that allows a systematic search of the space of unifiers (generalizing the unification algorithm of Martelli-Montanari[2] with rules for terms containing higher-order variables) that seems to work sufficiently well in practice. Huet[40] and Gilles Dowek[41] have written articles surveying this topic.
Dale Miller has described what is now called higher-order pattern unification.[42] This subset of higher-order unification is decidable and solvable unification problems have most-general unifiers. Many computer systems that contain higher-order unification, such as the higher-order logic programming languages λProlog and Twelf, often implement only the pattern fragment and not full higher-order unification.
In computational linguistics, one of the most influential theories of ellipsis is that ellipses are represented by free variables whose values are then determined using Higher-Order Unification (HOU). For instance, the semantic representation of "Jon likes Mary and Peter does too" is like(j; m)R(p) and the value of R (the semantic representation of the ellipsis) is determined by the equation like(j; m) = R(j). The process of solving such equations is called Higher-Order Unification.[43]
For example, the unification problem { f(a, b, a) ≐ d(b, a, c) }, where the only variable is f, has the solutions {f ↦ λx.λy.λz.d(y, x, c) }, {f ↦ λx.λy.λz.d(y, z, c) }, {f ↦ λx.λy.λz.d(y, a, c) }, {f ↦ λx.λy.λz.d(b, x, c) }, {f ↦ λx.λy.λz.d(b, z, c) } and {f ↦ λx.λy.λz.d(b, a, c) }.
Wayne Snyder gave a generalization of both higher-order unification and E-unification, i.e. an algorithm to unify lambda-terms modulo an equational theory.[44]
See also
- Admissible rule
- Explicit substitution in lambda calculus
- Mathematical Equation solving
- Dis-unification: solving inequations between symbolic expression
- Anti-unification: computing a least general generalization (lgg) of two terms, dual to computing a most general instance (mgu)
Notes
- ↑ in this case, still a complete substitution set exists (e.g. the set of all solutions at all); however, each such set contains redundant members.
- ↑ E.g. a ⊕ (b ⊕ f(x)) ≡ a ⊕ (f(x) ⊕ b) ≡ (b ⊕ f(x)) ⊕ a ≡ (f(x) ⊕ b) ⊕ a
- ↑ formally: each unifier τ satisfies ∀x: xτ = (xσ)ρ for some substitution ρ
- ↑ 4.0 4.1 in the presence of equality C, equalities Nl and Nr are equivalent, similar for Dl and Dr
References
- Franz Baader and Tobias Nipkow, Term Rewriting and All That. Cambridge University Press, 1998.
- Franz Baader and Wayne Snyder, Unification Theory. In John Alan Robinson and Andrei Voronkov, editors, Handbook of Automated Reasoning, volume I, pages 447–533. Elsevier Science Publishers, 2001.
- Joseph Goguen, What is Unification?.
- Nachum Dershowitz and Jean-Pierre Jouannaud, Rewrite Systems, in: Jan van Leeuwen (ed.), Handbook of Theoretical Computer Science, vol.B Formal Models and Semantics, Elsevier, 1990, pp. 243–320
- Kevin Knight (Mar 1989). "Unification: A Multidisciplinary Survey" (PDF). ACM Computing Surveys 21 (1): 93–124. doi:10.1145/62029.62030.
- Alex Sakharov, "Unification", MathWorld.
- ↑ Fages, François; Huet, Gérard (1986). "Complete Sets of Unifiers and Matchers in Equational Theories". Theoretical Computer Science 43: 189–200. doi:10.1016/0304-3975(86)90175-1.
- ↑ 2.0 2.1 2.2 Martelli, Alberto; Montanari, Ugo (Apr 1982). "An Efficient Unification Algorithm". ACM Trans. Program. Lang. Syst. 4 (2): 258–282. doi:10.1145/357162.357169.
- ↑ 3.0 3.1 3.2 3.3 J.A. Robinson (Jan 1965). "A Machine-Oriented Logic Based on the Resolution Principle". Journal of the ACM 12 (1): 23–41. doi:10.1145/321250.321253.; Here: sect.5.8, p.32
- ↑ J.A. Robinson (1971). "Computational logic: The unification computation" (PDF). Machine Intelligence 6: 63–72.
- ↑ C.C. Chang; H. Jerome Keisler (1977). A. Heyting and H.J. Keisler and A. Mostowski and A. Robinson and P. Suppes, ed. Model Theory. Studies in Logic and the Foundation of Mathematics 73. North Holland.; here: Sect.1.3
- ↑ Robinson (1965);[3] nr.2.5, 2.14, p.25
- ↑ Robinson (1965);[3] nr.5.6, p.32
- ↑ Robinson (1965);[3] nr.5.8, p.32
- ↑ Alg.1, p.261. Their rule (a) corresponds to rule swap here, (b) to delete, (c) to both decompose and conflict, and (d) to both eliminate and check.
- ↑ Lewis Denver Baxter (Feb 1976). A practically linear unification algorithm (PDF) (Res. Report). CS-76-13. Univ. of Waterloo, Ontario.
- ↑ Gérard Huet (Sep 1976). Resolution d'Equations dans des Langages d'Ordre 1,2,...ω (These d'etat). Universite de Paris VII.
- ↑ 12.0 12.1 Alberto Martelli and Ugo Montanari (Jul 1976). Unification in linear time and space: A structured presentation (Internal Note). IEI-B76-16. Consiglio Nazionale delle Ricerche, Pisa.
- ↑ 13.0 13.1 13.2 Michael Stewart Paterson and M.N. Wegman (Apr 1978). "Linear unification" (PDF). J. Comput. Syst. Sci. 16 (2): 158–167.
- ↑ J.A. Robinson (Jan 1976). Woodrow W. Bledsoe, Michael M. Richter, ed. Proc. Theorem Proving Workshop Oberwolfach. Oberwolfach Workshop Report. 1976/3.
- ↑ M. Venturini-Zilli (Oct 1975). "Complexity of the unification algorithm for first-order expressions". Calcolo 12 (4): 361–372.
- ↑ See Martelli, Montanari (1982),[2] sect.1, p.259. Paterson's and Wegman's paper is dated 1978; however, the journal publisher received it in Sep.1976.
- ↑ McBride, Conor (October 2003). "First-Order Unification by Structural Recursion". Journal of Functional Programming 13 (6): 1061–1076. doi:10.1017/S0956796803004957. ISSN 0956-7968. Retrieved 30 March 2012.
- ↑ e.g. Paterson, Wegman (1978),[13] sect.2, p.159
- ↑ Walther, Christoph (1985). "A Mechanical Solution of Schubert's Steamroller by Many-Sorted Resolution" (PDF). Artif. Intell. 26 (2): 217–224. doi:10.1016/0004-3702(85)90029-3.
- ↑ Smolka, Gert (Nov 1988). Logic Programming with Polymorphically Order-Sorted Types. Int. Workshop Algebraic and Logic Programming. LNCS 343. Springer. pp. 53–70.
- ↑ Schmidt-Schauß, Manfred (Apr 1988). Computational Aspects of an Order-Sorted Logic with Term Declarations. LNAI 395. Springer.
- ↑ Gordon D. Plotkin, Lattice Theoretic Properties of Subsumption, Memorandum MIP-R-77, Univ. Edinburgh, Jun 1970
- ↑ Mark E. Stickel, A Unification Algorithm for Associative-Commutative Functions, J. Assoc. Comput. Mach., vol.28, no.3, pp. 423–434, 1981
- ↑ 24.0 24.1 F. Fages, Associative-Commutative Unification, J. Symbolic Comput., vol.3, no.3, pp. 257–275, 1987
- ↑ Franz Baader, Unification in Idempotent Semigroups is of Type Zero, J. Automat. Reasoning, vol.2, no.3, 1986
- ↑ J. Makanin, The Problem of Solvability of Equations in a Free Semi-Group, Akad. Nauk SSSR, vol.233, no.2, 1977
- ↑ F. Fages (1987). "Associative-Commutative Unification". J. Symbolic Comput. 3 (3): 257–275. doi:10.1016/s0747-7171(87)80004-4.
- ↑ Martin, U., Nipkow, T. (1986). "Unification in Boolean Rings". In Jörg H. Siekmann. Proc. 8th CADE. LNCS 230. Springer. pp. 506–513.
- ↑ A. Boudet, J.P. Jouannaud, M. Schmidt-Schauß (1989). "Unification of Boolean Rings and Abelian Groups" (PDF). Journal of Symbolic Computation 8: 449–477. doi:10.1016/s0747-7171(89)80054-9.
- ↑ 30.0 30.1 Baader and Snyder (2001), p. 486.
- ↑ F. Baader and S. Ghilardi, Unification in modal and description logics, Logic Journal of the IGPL 19 (2011), no. 6, pp. 705–730.
- ↑ P. Szabo, Unifikationstheorie erster Ordnung (First Order Unification Theory), Thesis, Univ. Karlsruhe, West Germany, 1982
- ↑ Jörg H. Siekmann, Universal Unification, Proc. 7th Int. Conf. on Automated Deduction, Springer LNCS vol.170, pp. 1–42, 1984
- ↑ N. Dershowitz and G. Sivakumar, Solving Goals in Equational Languages, Proc. 1st Int. Workshop on Conditional Term Rewriting Systems, Springer LNCS vol.308, pp. 45–55, 1988
- ↑ Fay (1979). "First-Order Unification in an Equational Theory". Proc. 4th Workshop on Automated Deduction. pp. 161–167.
- ↑ Warren D. Goldfarb (1981). "The Undecidability of the Second-Order Unification Problem" (PDF). TCS 13: 225–230. doi:10.1016/0304-3975(81)90040-2.
- ↑ Gérard P. Huet (1973). "The Undecidability of Unification in Third Order Logic" (PDF). Information and Control 22: 257–267. doi:10.1016/S0019-9958(73)90301-X.
- ↑ Claudio Lucchesi: The Undecidability of the Unification Problem for Third Order Languages (Research Report CSRR 2059; Department of Computer Science, University of Waterloo, 1972)
- ↑ Gérard Huet: A Unification Algorithm for typed Lambda-Calculus []
- ↑ Gérard Huet: Higher Order Unification 30 Years Later
- ↑ Gilles Dowek: Higher-Order Unification and Matching. Handbook of Automated Reasoning 2001: 1009–1062
- ↑ Miller, Dale (1991). "A Logic Programming Language with Lambda-Abstraction, Function Variables, and Simple Unification" (PDF). Journal of Logic and Computation: 497–536.
- ↑ Claire Gardent; Michael Kohlhase; Karsten Konrad (1997). "A Multi-Level, Higher-Order Unification Approach to Ellipsis". Submitted to European Association for Computational Linguistics (EACL).
- ↑ Wayne Snyder (Jul 1990). "Higher order E-unification". Proc. 10th Conference on Automated Deduction. LNAI 449. Springer. pp. 573–587.