Uncertainty coefficient
In statistics, the uncertainty coefficient, also called proficiency, entropy coefficient or Theil's U, is a measure of nominal association. It was first introduced by Henri Theil and is based on the concept of information entropy.
Definition
Suppose we have samples of two discrete random variables, X and Y. By constructing the joint distribution, PX,Y(x, y), from which we can calculate the conditional distributions, PX|Y(x|y) = PX,Y(x, y)/PY(y) and PY|X(y|x) = PX,Y(x, y)/PX(x), and calculating the various entropies, we can determine the degree of association between the two variables.
The entropy of a single distribution is given as: [1]
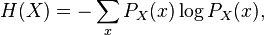
while the conditional entropy is given as:[1]
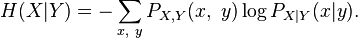
The uncertainty coefficient[2] or proficiency [3] is defined as:
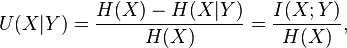
and tells us: given Y, what fraction of the bits of X can we predict? (The above expression makes clear that the uncertainty coefficient is a normalised mutual information I(X;Y).) In this case we can think of X as containing the "true" values. Note that the value of U (but not H!) is independent of the base of the log since all logarithms are proportional.
The uncertainty coefficient is useful for measuring the validity of a statistical classification algorithm and has the advantage over simpler accuracy measures such as precision and recall in that it is not affected by the relative fractions of the different classes, i.e., P(x) .[4] It also has the unique property that it won't penalize an algorithm for predicting the wrong classes, so long as it does so consistently (i.e., it simply rearranges the classes). This is useful in evaluating clustering algorithms since cluster labels typically have no particular ordering.[3]
Variations
Symmetrised: The uncertainty coefficient is not symmetric with respect to the roles of X and Y. The roles can be reversed and a symmetrical measure thus defined as a weighted average between the two:[2]
![\begin{align}
U(X,~Y) & = \frac{H(X)U(X|Y)+H(Y)U(Y|X)}{H(X)+H(Y)} \\[8pt]
& = 2 \left [\frac{H(X) + H(Y) - H(X,~Y)}{H(X)+H(Y)} \right ] .
\end{align}](../I/m/a2114d359a6b818b47fa32cf455ed1d2.png)
Continuous: Although normally applied to discrete variables, the uncertainty coefficient can be extended to continuous variables[1] using density estimation.
See also
References
- ↑ 1.0 1.1 1.2 Claude E. Shannon; Warren Weaver (1963). The Mathematical Theory of Communication. University of Illinois Press.
- ↑ 2.0 2.1 William H. Press; Brian P. Flannery; Saul A. Teukolsky; William T. Vetterling (1992). "14.7.4". Numerical Recipes: the Art of Scientific Computing (3rd ed.). Cambridge University Press. p. 761.
- ↑ 3.0 3.1 White, Jim; Steingold, Sam; Fournelle, Connie. "Performance Metrics for Group-Detection Algorithms" (PDF).
- ↑ Peter, Mills (2011). "Efficient statistical classification of satellite measurements" (PDF). International Journal of Remote Sensing 32 (21): 6109–6132. doi:10.1080/01431161.2010.507795.
External links
- libagf Includes software for calculating uncertainty coefficients.