Uncertain inference
Uncertain inference was first described by C. J. van Rijsbergen[1] as a way to formally define a query and document relationship in Information retrieval. This formalization is a logical implication with an attached measure of uncertainty.
Definitions
Rijsbergen proposes that the measure of uncertainty of a document d to a query q be the probability of its logical implication, i.e.:
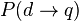
A user's query can be interpreted as a set of assertions about the desired document. It is the system's task to infer, given a particular document, if the query assertions are true. If they are, the document is retrieved.
In many cases the contents of documents are not sufficient to assert the queries. A knowledge base of facts and rules is needed, but some of them may be uncertain because there may be a probability associated to using them for inference. Therefore, we can also refer to this as plausible inference. The plausibility of an inference 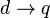 is a function of the plausibility of each query assertion. Rather than retrieving a document that exactly matches the query we should rank the documents based on their plausibility in regards to that query.
Since d and q are both generated by users, they are error prone; thus is uncertain. This will affect the plausibility of a given query.
is a function of the plausibility of each query assertion. Rather than retrieving a document that exactly matches the query we should rank the documents based on their plausibility in regards to that query.
Since d and q are both generated by users, they are error prone; thus is uncertain. This will affect the plausibility of a given query.
By doing this it accomplishes two things:
- Separate the processes of revising probabilities from the logic
- Separate the treatment of relevance from the treatment of requests
Multimedia documents, like images or videos, have different inference properties for each datatype. They are also different from text document properties. The framework of plausible inference allows us to measure and combine the probabilities coming from these different properties.
Uncertain inference generalizes the notions of autoepistemic logic, where truth values are either known or unknown, and when known, they are true or false.
Example
If we have a query of the form:
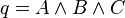
where A, B and C are query assertions, then for a document D we want the probability:
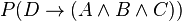
If we transform this into the conditional probability 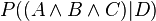 and if the query assertions are independent we can calculate the overall probability of the implication as the product of the individual assertions probabilities.
and if the query assertions are independent we can calculate the overall probability of the implication as the product of the individual assertions probabilities.
Further work
Croft and Krovetz[2] applied uncertain inference to an information retrieval system for office documents they called OFFICER. In office documents the independence assumption is valid since the query will focus on their individual attributes. Besides analysing the content of documents one can also query about the author, size, topic or collection for example. They devised methods to compare document and query attributes, infer their plausibility and combine it into an overall rating for each document. Besides that uncertainty of document and query contents also had to be addressed.
Probabilistic logic networks is a system for performing uncertain inference; crisp true/false truth values are replaced not only by a probability, but also by a confidence level, indicating the certitude of the probability.
Markov logic networks allow uncertain inference to be performed; uncertainties are computed using the maximum entropy principle, in analogy to the way that Markov chains describe the uncertainty of finite state machines.
See also
References
- ↑ C. J. van Rijsbergen (1986), A non-classical logic for information retrieval, The Computer Journal, pp. 481–485
- ↑ W. B. Croft; R. Krovetz (1988), Interactive retrieval office documents