Tversky index
The Tversky index, named after Amos Tversky,[1] is an asymmetric similarity measure on sets that compares a variant to a prototype. The Tversky index can be seen as a generalization of Dice's coefficient and Tanimoto coefficient.
For sets X and Y the Tversky index is a number between 0 and 1 given by
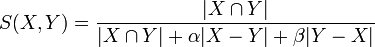 ,
,
Here, 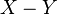 denotes the relative complement of Y in X.
denotes the relative complement of Y in X.
Further, 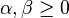 are parameters of the Tversky index. Setting
are parameters of the Tversky index. Setting 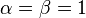 produces the Tanimoto coefficient; setting
produces the Tanimoto coefficient; setting 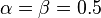 produces Dice's coefficient.
produces Dice's coefficient.
If we consider X to be the prototype and Y to be the variant, then 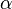 corresponds to the weight of the prototype and
corresponds to the weight of the prototype and 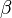 corresponds to the weight of the variant. Tversky measures with
corresponds to the weight of the variant. Tversky measures with 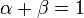 are of special interest.[2]
are of special interest.[2]
Because of the inherent asymmetry, the Tversky index does not meet the criteria for a similarity metric. However, if symmetry is needed a variant of the original formulation has been proposed using max and min functions [3] .
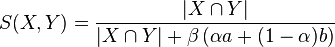 ,
,
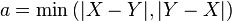 ,
,
 ,
,
This formulation also re-arranges parameters and . Thus, controls the balance between  and
and 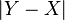 in the denominator. Similarly, controls the effect of the symmetric difference
in the denominator. Similarly, controls the effect of the symmetric difference 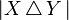 versus
versus 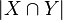 in the denominator.
in the denominator.
Notes
- ↑ Tversky, Amos (1977). "Features of Similarity". Psychological Reviews 84 (4): 327–352.
- ↑ http://www.daylight.com/dayhtml/doc/theory/theory.finger.html
- ↑ Jimenez, S., Becerra, C., Gelbukh, A. SOFTCARDINALITY-CORE: Improving Text Overlap with Distributional Measures for Semantic Textual Similarity. Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 1: Proceedings of the Main Conference and the Shared Task: Semantic Textual Similarity, p.194-201, June 7–8, 2013, Atlanta, Georgia, USA.