Tree kernel
In machine learning, tree kernels are the application of the more general concept of positive-definite kernel to tree structures. They find applications in natural language processing, where they can be used for machine-learned parsing, or classification of sentences.
Motivation
In natural language processing, it is often necessary to compare tree structures (e.g. parse trees) for similarity. Such comparisons can be performed by computing dot products of vectors of features of the trees, but these vectors tend to be very large: NLP techniques have come to a point where a simple dependency relation over two words is encoded with a vector of several millions of features.[1] It can be impractical to represent complex structures such as trees with features vectors. Well-designed kernels allow to compute similarity over trees without explicitly computing the features vectors of these trees. Moreover, kernel methods have been widely used in machine learning tasks ( e.g. SVM ), and thus plenty of algorithms are working natively with kernels, or have an extension that handles kernelization.
An example application is classification of sentences, such as different types of questions.[2]
Examples

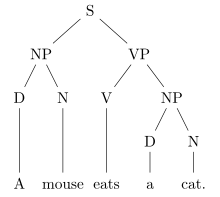
Here are presented two examples of tree kernel applied to the constituency trees of the sentences "A cat eats a mouse." and "A mouse eats a cat.". In this example "A" and "a" are the same words, and in most of the NLP applications they would be represented with the same token.
The interest of these two kernels is that they show very different granularity (the subset tree kernel being far more fine-grained than the subtree kernel), for the same computation complexity. Both can be computed recursively in time O(|T1|.|T2|).[3]
Subtree kernel
In the case of constituency tree, a subtree is defined as a node and all its children (e.g., [NP [D [A]] [N [mouse]]] is a subtree of the two trees). Terminals are not considered subtree (e.g. [a] is not a subtree). The subtree kernel count the number of common subtrees between two given trees.
In this example, there are seven common subtrees:
- [NP [D [a]] [N [cat]]],
- [NP [D [a]] [N [mouse]]],
- [N [mouse]],
- [N [cat]],
- [V [eats]],
- [D [a]] (counted twice as it appears twice).
Subset tree kernel
A subset tree is a more general structure than a subtree. The basic definition is the same, but in the case of subset trees, leaves need not be terminals (e.g., [VP [V] [NP]] is a subset tree of both trees), but here too single nodes are not considered as trees. Because of this more general definition, there are more subset trees than subtrees, and more common subset trees than common subtrees.
In this example, there are 54 common subset trees. The seven common subtrees plus among others:
- [NP [D] [N]] (counted twice),
- [VP [V [eats]] [NP]]...
See also
Notes
- ↑ McDonald, Ryan; Pereira, Fernando; Ribarov, Kiril; Hajič, Jan (2005). Non-projective Dependency Parsing using Spanning Tree Algorithms. HLT–EMNLP.
- ↑ Zhang, Dell; Lee, Wee Sun (2003). Question classification using support vector machines. SIGIR.
- ↑ Collins, Michael; Duffy, Nigel (2001). Convolution kernels for natural language. Advances in Neural Information Processing Systems.
References
- Jun Sun, Min Zhang and Chew Lim Tan. Tree Sequence Kernel for Natural Language
- Alessandro Moschitti. Making Tree Kernels practical for Natural Language Learning
External links
- http://disi.unitn.it/moschitti/Tree-Kernel.htm -- Application of tree kernel to SVM, on Alessandro Moschitti web-page.