Todd–Coxeter algorithm
In group theory, the Todd–Coxeter algorithm, created by J. A. Todd and H. S. M. Coxeter in 1936, is an algorithm for solving the coset enumeration problem. Given a presentation of a group G by generators and relations and a subgroup H of G, the algorithm enumerates the cosets of H on G and describes the permutation representation of G on the space of the cosets. If the order of a group G is relatively small and the subgroup H is known to be uncomplicated (for example, a cyclic group), then the algorithm can be carried out by hand and gives a reasonable description of the group G. Using their algorithm, Coxeter and Todd showed that certain systems of relations between generators of known groups are complete, i.e. constitute systems of defining relations.
The Todd–Coxeter algorithm can be applied to infinite groups and is known to terminate in a finite number of steps, provided that the index of H in G is finite. On the other hand, for a general pair consisting of a group presentation and a subgroup, its running time is not bounded by any computable function of the index of the subgroup and the size of the input data.
Description of the algorithm
One implementation of the algorithm proceeds as follows. Suppose that 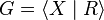 , where
, where 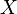 is a set of generators and
is a set of generators and 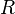 is a set of relations and denote by
is a set of relations and denote by 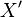 the set of generators and their inverses. Let
the set of generators and their inverses. Let 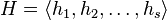 where the
where the 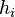 are words of elements of . There are three types of tables that will be used: a coset table, a relation table for each relation in , and a subgroup table for each generator of
are words of elements of . There are three types of tables that will be used: a coset table, a relation table for each relation in , and a subgroup table for each generator of 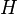 . Information is gradually added to these tables, and once they are filled in, all cosets have been enumerated and the algorithm terminates.
. Information is gradually added to these tables, and once they are filled in, all cosets have been enumerated and the algorithm terminates.
The coset table is used to store the relationships between the known cosets when multiplying by a generator. It has rows representing cosets of and a column for each element of . Let 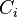 denote the coset of the ith row of the coset table, and let
denote the coset of the ith row of the coset table, and let 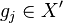 denote generator of the jth column. The entry of the coset table in row i, column j is defined to be (if known) k, where k is such that
denote generator of the jth column. The entry of the coset table in row i, column j is defined to be (if known) k, where k is such that 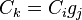 .
.
The relation tables are used to detect when some of the cosets we have found are actually equivalent. One relation table for each relation in is maintained. Let 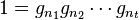 be a relation in , where
be a relation in , where 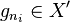 . The relation table has rows representing the cosets of , as in the coset table. It has t columns, and the entry in the ith row and jth column is defined to be (if known) k, where
. The relation table has rows representing the cosets of , as in the coset table. It has t columns, and the entry in the ith row and jth column is defined to be (if known) k, where 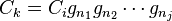 . In particular, the
. In particular, the 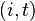 'th entry is initially i, since
'th entry is initially i, since 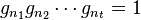 .
.
Finally, the subgroup tables are similar to the relation tables, except that they keep track of possible relations of the generators of . For each generator 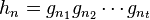 of , with , we create a subgroup table. It has only one row, corresponding to the coset of itself. It has t columns, and the entry in the jth column is defined (if known) to be k, where
of , with , we create a subgroup table. It has only one row, corresponding to the coset of itself. It has t columns, and the entry in the jth column is defined (if known) to be k, where 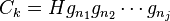 .
.
When a row of a relation or subgroup table is completed, a new piece of information 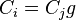 ,
, 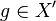 , is found. This is known as a deduction. From the deduction, we may be able to fill in additional entries of the relation and subgroup tables, resulting in possible additional deductions. We can fill in the entries of the coset table corresponding to the equations and
, is found. This is known as a deduction. From the deduction, we may be able to fill in additional entries of the relation and subgroup tables, resulting in possible additional deductions. We can fill in the entries of the coset table corresponding to the equations and 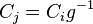 .
.
However, when filling in the coset table, it is possible that we may already have an entry for the equation, but the entry has a different value. In this case, we have discovered that two of our cosets are actually the same, known as a coincidence. Suppose 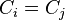 , with
, with 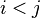 . We replace all instances of j in the tables with i. Then, we fill in all possible entries of the tables, possibly leading to more deductions and coincidences.
. We replace all instances of j in the tables with i. Then, we fill in all possible entries of the tables, possibly leading to more deductions and coincidences.
If there are empty entries in the table after all deductions and coincidences have been taken care of, add a new coset to the tables and repeat the process. We make sure that when adding cosets, if Hx is a known coset, then Hxg will be added at some point for all . (This is needed to guarantee that the algorithm will terminate provided 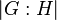 is finite.)
is finite.)
When all the tables are filled, the algorithm terminates. We then have all needed information on the action of 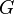 on the cosets of .
on the cosets of .
See also
References
- Todd, J. A.; Coxeter, H. S. M. (1936). "A practical method for enumerating cosets of a finite abstract group". Proceedings of the Edinburgh Mathematical Society. Series II 5: 26–34. doi:10.1017/S0013091500008221. JFM 62.1094.02. Zbl 0015.10103.
- Coxeter, W. O. J.; Moser (1980). Generators and Relations for Discrete Groups. Ergebnisse der Mathematik und ihrer Grenzgebiete 14 (4th ed.). Springer-Verlag 1980. ISBN 3-540-09212-9. MR 0562913.
- Seress, A. (1997). "An Introduction to Computational Group Theory". Notices of the American Mathematical Society.