Tensor rank decomposition
In multilinear algebra, the tensor rank decomposition or canonical polyadic decomposition (CPD) may be regarded as a generalization of the matrix singular value decomposition (SVD) to tensors, which has found application in statistics, signal processing, psychometrics, linguistics and chemometrics. It was introduced by Hitchcock in 1927[1] and later rediscovered several times, notably in psychometrics.[2][3] For this reason, the tensor rank decomposition is sometimes historically referred to as PARAFAC[3] or CANDECOMP.[2]
Definition
Consider a tensor space 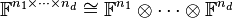 , where
, where  is either the real field
is either the real field 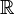 or the complex field
or the complex field 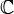 . Every (order-
. Every (order-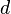 ) tensor in this space may then be represented with a suitably large
) tensor in this space may then be represented with a suitably large  as a linear combination of rank-1 tensors:
as a linear combination of rank-1 tensors:
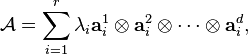
where 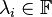 and
and 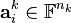 ; note that the superscript
; note that the superscript 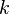 should not be interpreted as an exponent, it is merely another index. When the number of terms is minimal in the above expression, then is called the rank of the tensor, and the decomposition is often referred to as a (tensor) rank decomposition, minimal CP decomposition, or Canonical Polyadic Decomposition (CPD). Contrariwise, if the number of terms is not minimal, then the above decomposition is often referred to as -term decomposition, CANDECOMP/PARAFAC or Polyadic decomposition.
should not be interpreted as an exponent, it is merely another index. When the number of terms is minimal in the above expression, then is called the rank of the tensor, and the decomposition is often referred to as a (tensor) rank decomposition, minimal CP decomposition, or Canonical Polyadic Decomposition (CPD). Contrariwise, if the number of terms is not minimal, then the above decomposition is often referred to as -term decomposition, CANDECOMP/PARAFAC or Polyadic decomposition.
Tensor rank
Contrary to the case of matrices, the rank of a tensor is presently not understood well. It is known that the problem of computing the rank of a tensor is NP-hard.[4] The only notable well-understood case consists of tensors in 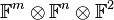 , whose rank can be obtained from the Kronecker–Weierstrass normal form of the linear matrix pencil that the tensor represents.[5] A simple polynomial-time algorithm exists for certifying that a tensor is of rank 1, namely the higher-order singular value decomposition.
, whose rank can be obtained from the Kronecker–Weierstrass normal form of the linear matrix pencil that the tensor represents.[5] A simple polynomial-time algorithm exists for certifying that a tensor is of rank 1, namely the higher-order singular value decomposition.
The rank of the tensor of zeros is zero by convention. The rank of a tensor 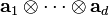 is one, provided that
is one, provided that  .
.
Field dependence
The rank of a tensor depends on the field over which the tensor is decomposed. It is known that some real tensors may admit a complex decomposition whose rank is strictly less than the rank of a real decomposition of the same tensor. As an example,[6] consider the following real tensor
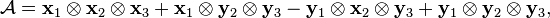
whose rank over the reals is known to be 3, while its complex rank is only 2 because it is the sum of a complex rank-1 tensor with its complex conjugate:
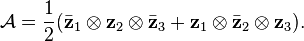
In contrast, the rank of real matrices will never decrease under a field extension to : real matrix rank and complex matrix rank coincide for real matrices.
Generic rank
The generic rank  is defined as the least rank such that the closure in the Zariski topology of the set of tensors of rank at most is the entire space
is defined as the least rank such that the closure in the Zariski topology of the set of tensors of rank at most is the entire space  . In the case of complex tensors, tensors of rank at most form a dense set
. In the case of complex tensors, tensors of rank at most form a dense set 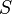 : every tensor in the aforementioned space is either of rank less than the generic rank, or it is the limit in the Euclidean topology of a sequence of tensors from . In the case of real tensors, the set of tensors of rank at most only forms an open set of positive measure in the Euclidean topology. There may exist Euclidean-open sets of tensors of rank strictly higher than the generic rank. All ranks appearing on open sets in the Euclidean topology are called typical ranks. The smallest typical rank is called the generic rank; this definition applies to both complex and real tensors. The generic rank of tensor spaces was initially studied in 1983 by Volker Strassen.[7]
: every tensor in the aforementioned space is either of rank less than the generic rank, or it is the limit in the Euclidean topology of a sequence of tensors from . In the case of real tensors, the set of tensors of rank at most only forms an open set of positive measure in the Euclidean topology. There may exist Euclidean-open sets of tensors of rank strictly higher than the generic rank. All ranks appearing on open sets in the Euclidean topology are called typical ranks. The smallest typical rank is called the generic rank; this definition applies to both complex and real tensors. The generic rank of tensor spaces was initially studied in 1983 by Volker Strassen.[7]
As an illustration of the above concepts, it is known that both 2 and 3 are typical ranks of 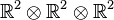 while the generic rank of
while the generic rank of  is 2. Practically, this means that a randomly sampled real tensor (from a continuous probability measure on the space of tensors) of size
is 2. Practically, this means that a randomly sampled real tensor (from a continuous probability measure on the space of tensors) of size 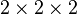 will be a rank-1 tensor with probability zero, a rank-2 tensor with positive probability, and rank-3 with positive probability. On the other hand, a randomly sampled complex tensor of the same size will be a rank-1 tensor with probability zero, a rank-2 tensor with probability one, and a rank-3 tensor with probability zero. It is even known that the generic rank-3 real tensor in will be of complex rank equal to 2.
will be a rank-1 tensor with probability zero, a rank-2 tensor with positive probability, and rank-3 with positive probability. On the other hand, a randomly sampled complex tensor of the same size will be a rank-1 tensor with probability zero, a rank-2 tensor with probability one, and a rank-3 tensor with probability zero. It is even known that the generic rank-3 real tensor in will be of complex rank equal to 2.
The generic rank of tensor spaces depends on the distinction between balanced and unbalanced tensor spaces. A tensor space , where 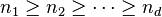 ,
is called unbalanced whenever
,
is called unbalanced whenever
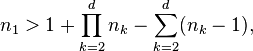
and it is called balanced otherwise.
Unbalanced tensor spaces
When the first factor is very large with respect to the other factors in the tensor product, then the tensor space essentially behaves as a linear space. The generic rank of tensors living in an unbalanced tensor spaces is known to equal
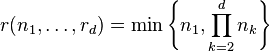
almost everywhere. More precisely, the rank of every tensor in an unbalanced tensor space 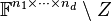 , where
, where 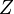 is some indeterminate closed set in the Zariski topology, equals the above value.[8]
is some indeterminate closed set in the Zariski topology, equals the above value.[8]
Balanced tensor spaces
The generic rank of tensors living in a balanced tensor space in is expected to equal
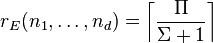
almost everywhere for complex tensors and on a Euclidean-open set for real tensors, where

More precisely, the rank of every tensor in  , where is some indeterminate closed set in the Zariski topology, is expected to equal the above value.[9] For real tensors,
, where is some indeterminate closed set in the Zariski topology, is expected to equal the above value.[9] For real tensors,  is the least rank that is expected to occur on a set of positive Euclidean measure. The value is often referred to as the expected generic rank of the tensor space
is the least rank that is expected to occur on a set of positive Euclidean measure. The value is often referred to as the expected generic rank of the tensor space 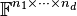 because it is only conjecturally correct. It is known that the true generic rank always satisfies
because it is only conjecturally correct. It is known that the true generic rank always satisfies

The Abo–Ottaviani–Peterson conjecture[9] states that equality is expected, i.e.,  , with the following exceptional cases:
, with the following exceptional cases:

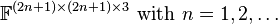
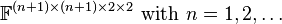
In each of these exceptional cases, the generic rank is known to be 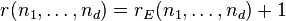 . The conjecture has been proved completely in a number of special cases. Lickteig showed already in 1985 that
. The conjecture has been proved completely in a number of special cases. Lickteig showed already in 1985 that 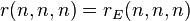 , provided that
, provided that 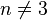 .[10] In 2011, a major breakthrough was established by Catalisano, Geramita, and Gimigliano who proved that
.[10] In 2011, a major breakthrough was established by Catalisano, Geramita, and Gimigliano who proved that 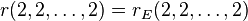 , except for the space
, except for the space 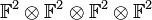 .[11]
.[11]
Maximum rank
The maximum rank that can be admitted by any of the tensors in a tensor space is unknown in general; even a conjecture about this maximum rank is missing. Presently, the best general upper bound states that the maximum rank 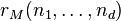 of , where , satisfies
of , where , satisfies
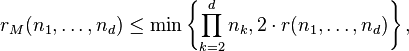
where is the (least) generic rank of .[12]
It is well-known that the foregoing inequality may be strict. For instance, the generic rank of tensors in 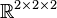 is two, so that the above bound yields
is two, so that the above bound yields 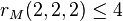 , while it is known that the maximum rank equals 3.[6]
, while it is known that the maximum rank equals 3.[6]
Border rank
A rank- tensor
tensor 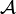 is called a border tensor if there exists a sequence of tensors of rank at most
is called a border tensor if there exists a sequence of tensors of rank at most  whose limit is . If is the least value for which such a convergent sequence exists, then it is called the border rank of . For order-2 tensors, i.e., matrices, rank and border rank always coincide, however, for tensors of order
whose limit is . If is the least value for which such a convergent sequence exists, then it is called the border rank of . For order-2 tensors, i.e., matrices, rank and border rank always coincide, however, for tensors of order 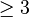 they may differ. Border tensors were first studied in the context of fast approximate matrix multiplication algorithms by Bini, Lotti, and Romani in 1980.[13]
they may differ. Border tensors were first studied in the context of fast approximate matrix multiplication algorithms by Bini, Lotti, and Romani in 1980.[13]
A classic example of a border tensor is the rank-3 tensor
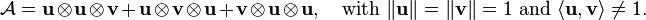
It can be approximated arbitrarily well by the following sequence of rank-2 tensors

as 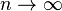 . Therefore, its border rank is 2, which is strictly less than its rank.
. Therefore, its border rank is 2, which is strictly less than its rank.
Properties
Ill-posedness of the standard approximation problem
The rank approximation problem asks for the rank- decomposition closest (in the usual Euclidean topology) to some rank- tensor , where . That is, one seeks to solve
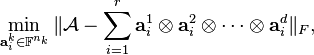
where 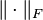 is the Frobenius norm.
is the Frobenius norm.
It was show in a 2008 paper by de Silva and Lim[6] that the above standard approximation problem may be ill-posed. A solution to aforementioned problem may sometimes not exist because the set over which one optimizes is not closed. As such, a minimizer may not exist, even though an infimum would exist. In particular, it is known that certain so-called border tensors may be approximated arbitrarily well by a sequence of tensor of rank at most , even though the limit of the sequence converges to a tensor of rank strictly higher than . The rank-3 tensor

can be approximated arbitrarily well by the following sequence of rank-2 tensors
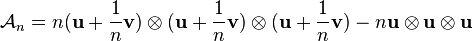
as . This example neatly illustrates the general principle that a sequence of rank- tensors that converges to a tensor of strictly higher rank needs to admit at least two individual rank-1 terms whose norms become unbounded. Stated formally, whenever a sequence
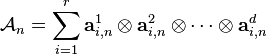
has the property that 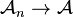 (in the Euclidean topology) as , then there should exist at least
(in the Euclidean topology) as , then there should exist at least 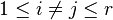 such that
such that
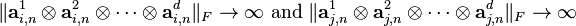
as . This phenomenon is often encountered when attempting to approximate a tensor using numerical optimization algorithms. It is sometimes called the problem of diverging components. It was, in addition, shown that a random low-rank tensor over the reals may not admit a rank-2 approximation with positive probability, leading to the understanding that the ill-posedness problem is an important consideration when employing the tensor rank decomposition.
A common partial solution to the ill-posedness problem consists of imposing an additional inequality constraint that bounds the norm of the individual rank-1 terms by some constant. Other constraints that result in a closed set, and, thus, well-posed optimization problem, include imposing positivity or a bounded inner product strictly less than unity between the rank-1 terms appearing in the sought decomposition.
Calculating the CPD
Alternating algorithms:
- alternating least squares (ALS)
- alternating slice-wise diagonalisation (ASD)
Algebraic algorithms:
- simultaneous diagonalization (SD)
- simultaneous generalized Schur decomposition (SGSD)
Optimization algorithms:
- Levenberg–Marquardt (LM)
- nonlinear conjugate gradient (NCG)
- limited memory BFGS (L-BFGS)
Direct methods:
- Direct multilinear decomposition (DMLD)
Applications of the CPD
Chemometrics
Multi-way data are characterized by several sets of categorical variables that are measured in a crossed fashion. Chemical examples could be fluorescence emission spectra measured at several excitation wavelengths for several samples, fluorescence lifetime measured at several excitation and emission wavelengths or any kind of spectrum measured chromatographically for several samples. Determining such variables will give rise to three-way data; i.e., the data can be arranged in a cube instead of a matrix as in standard multivariate data sets.
Other decompositions
PARAFAC is one of several decomposition methods for multi-way data. The two main competitors are the Tucker3 method, and simply unfolding of the multi-way array to a matrix and then performing standard two-way methods as principal component analysis (PCA). The Tucker3 method should rightfully be called three-mode principal component analysis (or N-mode principal component analysis), but here the term Tucker3 or just Tucker decomposition will be used instead. PARAFAC, Tucker and two-way PCA are all multi- or bi-linear decomposition methods, which decompose the array into sets of "scores" and "loadings", that hopefully describe the data in a more condensed form than the original data array. There are advantages and disadvantages with all the methods, and often several methods must be tried to find the most appropriate.
In the field of chemometrics, a number of diagnostic tools and techniques exist to help a PARAFAC user determine the best fitting model. These include the core consistency diagnostic (CORCONDIA),[14] split-half analyses,[15] examination of the loadings,[16] and residual analysis.[16]
See also
- Latent class analysis
- Multilinear subspace learning
- Singular value decomposition
- Tucker decomposition
References
- ↑ F. L. Hitchcock (1927). "The expression of a tensor or a polyadic as a sum of products". Journal of Mathematics and Physics 6: 164–189.
- ↑ 2.0 2.1 Carroll, J. D.; Chang, J. (1970). "Analysis of individual differences in multidimensional scaling via an n-way generalization of 'Eckart–Young' decomposition". Psychometrika 35: 283–319. doi:10.1007/BF02310791.
- ↑ 3.0 3.1 Harshman, Richard A. (1970). "Foundations of the PARAFAC procedure: Models and conditions for an "explanatory" multi-modal factor analysis". UCLA Working Papers in Phonetics (Ann Arbor: University Microfilms) 16: 84. No. 10,085.
- ↑ Hillar, C. J.; Lim, L. (2013). "Most tensor problems are NP-Hard". Journal of the ACM 60: 45.
- ↑ Landsberg, J. M. (2012). Tensors: Geometry and Applications. AMS.
- ↑ 6.0 6.1 6.2 de Silva, V.; Lim, L. (2008). "Tensor Rank and the Ill-Posedness of the Best Low-Rank Approximation Problem". SIAM Journal on Matrix Analysis and Applications 30: 1084–1127.
- ↑ Strassen, V. (1983). "Rank and optimal computation of generic tensors". Linear Algebra and its Applications. 52/53: 645–685.
- ↑ Catalisano, M. V.; Geramita, A. V.; Gimigliano, A. (2002). "Ranks of tensors, secant varieties of Segre varieties and fat points". Linear Algebra and its Applications 355: 263–285.
- ↑ 9.0 9.1 Abo, H.; Ottaviani, G.; Peterson, C. (2009). "Induction for secant varieties of Segre varieties". Transactions of the American Mathematical Society 361: 767–792.
- ↑ Lickteig, Thomas (1985). "Typical tensorial rank". Linear Algebra and its Applications 69: 95–120.
- ↑ Catalisano, M. V.; Geramita, A. V.; Gimigliano, A. (2011). "Secant varieties of ℙ1 × ··· × ℙ1 (n-times) are not defective for n ≥ 5". Journal of Algebraic Geometry 20: 295–327.
- ↑ Blehkerman, G.; Teitler, Z. (2014). "On maximum, typical and generic ranks". Mathematische Annalen. In press.: 1–11. doi:10.1007/s00208-014-1150-3.
- ↑ Bini, D.; Lotti, G.; Romani, F. (1980). "Approximate solutions for the bilinear form computational problem". SIAM Journal on Scientific Computing 9: 692–697.
- ↑ Bro, R.; Kiers, H. A. L. (2003). "A new efficient method for determining the number of components in PARAFAC models". Journal of Chemometrics 17 (5): 274–286. doi:10.1002/cem.801.
- ↑ Bro, R. (1997). "PARAFAC. Tutorial and applications". Chemometrics and Intelligent Laboratory Systems 38 (2): 149–171. doi:10.1016/s0169-7439(97)00032-4.
- ↑ 16.0 16.1 Stedmon, C. A.; Bro, R. (2008). "Characterizing dissolved organic matter fluorescence with parallel factor analysis: a tutorial". Limnology and Oceanography-Methods 6: 572–579. doi:10.4319/lom.2008.6.572.
Further reading
- Kolda, Tamara G.; Bader, Brett W. (2009). "Tensor Decompositions and Applications". SIAM Rev. 51: 455–500. doi:10.1137/07070111X. CiteSeerX: 10
.1 ..1 .153 .2059 - Landsberg, Joseph M. (2012). Tensors: Geometry and Applications. AMS.
External links
- PARAFAC Tutorial
- Parallel Factor Analysis (PARAFAC)
- FactoMineR (free exploratory multivariate data analysis software linked to R)