Temporal difference learning
Temporal difference (TD) learning is a prediction method. It has been mostly used for solving the reinforcement learning problem. "TD learning is a combination of Monte Carlo ideas and dynamic programming (DP) ideas."[1] TD resembles a Monte Carlo method because it learns by sampling the environment according to some policy. TD is related to dynamic programming techniques because it approximates its current estimate based on previously learned estimates (a process known as bootstrapping). The TD learning algorithm is related to the temporal difference model of animal learning.[2]
As a prediction method, TD learning takes into account the fact that subsequent predictions are often correlated in some sense. In standard supervised predictive learning, one learns only from actually observed values: A prediction is made, and when the observation is available, the prediction is adjusted to better match the observation. As elucidated in,[3] the core idea of TD learning is that we adjust predictions to match other, more accurate, predictions about the future. This procedure is a form of bootstrapping, as illustrated with the following example:
- Suppose you wish to predict the weather for Saturday, and you have some model that predicts Saturday's weather, given the weather of each day in the week. In the standard case, you would wait until Saturday and then adjust all your models. However, when it is, for example, Friday, you should have a pretty good idea of what the weather would be on Saturday - and thus be able to change, say, Monday's model before Saturday arrives.[3]
Mathematically speaking, both in a standard and a TD approach, we would try to optimize some cost function, related to the error in our predictions of the expectation of some random variable, E[z]. However, while in the standard approach we in some sense assume E[z] = z (the actual observed value), in the TD approach we use a model. For the particular case of reinforcement learning, which is the major application of TD methods, z is the total return and E[z] is given by the Bellman equation of the return.
TD algorithm in neuroscience
The TD algorithm has also received attention in the field of neuroscience. Researchers discovered that the firing rate of dopamine neurons in the ventral tegmental area (VTA) and substantia nigra (SNc) appear to mimic the error function in the algorithm.[2] The error function reports back the difference between the estimated reward at any given state or time step and the actual reward received. The larger the error function, the larger the difference between the expected and actual reward. When this is paired with a stimulus that accurately reflects a future reward, the error can be used to associate the stimulus with the future reward.
Dopamine cells appear to behave in a similar manner. In one experiment measurements of dopamine cells were made while training a monkey to associate a stimulus with the reward of juice.[4] Initially the dopamine cells increased firing rates when the monkey received juice, indicating a difference in expected and actual rewards. Over time this increase in firing back propagated to the earliest reliable stimulus for the reward. Once the monkey was fully trained, there was no increase in firing rate upon presentation of the predicted reward. Continually, the firing rate for the dopamine cells decreased below normal activation when the expected reward was not produced. This mimics closely how the error function in TD is used for reinforcement learning.
The relationship between the model and potential neurological function has produced research attempting to use TD to explain many aspects of behavioral research.[5] It has also been used to study conditions such as schizophrenia or the consequences of pharmacological manipulations of dopamine on learning.[6]
Mathematical formulation
Let 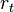 be the reinforcement on time step t. Let
be the reinforcement on time step t. Let 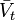 be the correct prediction that is equal to the discounted sum of all future reinforcement. The discounting is done by powers of factor of
be the correct prediction that is equal to the discounted sum of all future reinforcement. The discounting is done by powers of factor of 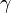 such that reinforcement at distant time step is less important.
such that reinforcement at distant time step is less important.
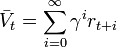
where 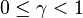 .
This formula can be expanded
.
This formula can be expanded
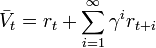
by changing the index of i to start from 0.
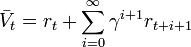
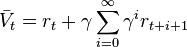
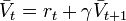
Thus, the reinforcement is the difference between the ideal prediction and the current prediction.
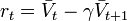
TD-Lambda is a learning algorithm invented by Richard S. Sutton based on earlier work on temporal difference learning by Arthur Samuel.[1] This algorithm was famously applied by Gerald Tesauro to create TD-Gammon, a program that learned to play the game of backgammon at the level of expert human players.[7] The lambda (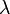 ) parameter refers to the trace decay parameter, with
) parameter refers to the trace decay parameter, with 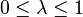 . Higher settings lead to longer lasting traces; that is, a larger proportion of credit from a reward can be given to more distant states and actions when is higher, with
. Higher settings lead to longer lasting traces; that is, a larger proportion of credit from a reward can be given to more distant states and actions when is higher, with 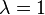 producing parallel learning to Monte Carlo RL algorithms.
producing parallel learning to Monte Carlo RL algorithms.
See also
- Reinforcement learning
- Q-learning
- SARSA
- Rescorla-Wagner model
- PVLV
Notes
- ↑ 1.0 1.1 Richard Sutton and Andrew Barto (1998). Reinforcement Learning. MIT Press. ISBN 0-585-02445-6.
- ↑ 2.0 2.1 Schultz, W, Dayan, P & Montague, PR. (1997). "A neural substrate of prediction and reward". Science 275 (5306): 1593–1599. doi:10.1126/science.275.5306.1593. PMID 9054347.
- ↑ 3.0 3.1 Richard Sutton (1988). "Learning to predict by the methods of temporal differences". Machine Learning 3 (1): 9–44. doi:10.1007/BF00115009. (A revised version is available on Richard Sutton's publication page)
- ↑ Schultz, W. (1998). "Predictive reward signal of dopamine neurons". J Neurophysiology 80 (1): 1–27.
- ↑ Dayan, P. (2001). "Motivated reinforcement learning". Advances in Neural Information Processing Systems (MIT Press) 14: 11–18.
- ↑ Smith, A., Li, M., Becker, S. and Kapur, S. (2006). "Dopamine, prediction error, and associative learning: a model-based account". Network: Computation in Neural Systems 17 (1): 61–84. doi:10.1080/09548980500361624. PMID 16613795.
- ↑ Tesauro, Gerald (March 1995). "Temporal Difference Learning and TD-Gammon". Communications of the ACM 38 (3). Retrieved 2010-02-08.
Bibliography
- Sutton, R.S., Barto A.G. (1990). "Time Derivative Models of Pavlovian Reinforcement". Learning and Computational Neuroscience: Foundations of Adaptive Networks: 497–537.
- Gerald Tesauro (March 1995). "Temporal Difference Learning and TD-Gammon". Communications of the ACM 38 (3).
- Imran Ghory. Reinforcement Learning in Board Games.
- S. P. Meyn, 2007. Control Techniques for Complex Networks, Cambridge University Press, 2007. See final chapter, and appendix with abridged Meyn & Tweedie.
External links
- Scholarpedia Temporal difference Learning
- TD-Gammon
- TD-Networks Research Group
- Connect Four TDGravity Applet (+ mobile phone version) - self-learned using TD-Leaf method (combination of TD-Lambda with shallow tree search)
- Self Learning Meta-Tic-Tac-Toe Example web app showing how temporal difference learning can be used to learn state evaluation constants for a minimax AI playing a simple board game.
- Reinforcement Learning Problem, document explaining how temporal difference learning can be used to speed up Q-learning