Substring
A substring of a string 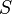 is another string
is another string 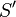 that occurs "in" . For example, "the best of" is a substring of "It was the best of times". This is not to be confused with subsequence, which is a generalization of substring. For example, "Itwastimes" is a subsequence of "It was the best of times", but not a substring.
that occurs "in" . For example, "the best of" is a substring of "It was the best of times". This is not to be confused with subsequence, which is a generalization of substring. For example, "Itwastimes" is a subsequence of "It was the best of times", but not a substring.
Prefix and suffix are refinements of substring. A prefix of a string is a substring of that occurs at the beginning of . A suffix of a string is a substring that occurs at the end of .
Substring
A substring (or factor) of a string 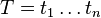 is a string
is a string 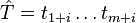 , where
, where 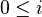 and
and 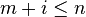 . A substring of a string is a prefix of a suffix of the string, and equivalently a suffix of a prefix. If
. A substring of a string is a prefix of a suffix of the string, and equivalently a suffix of a prefix. If 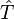 is a substring of
is a substring of 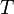 , it is also a subsequence, which is a more general concept. Given a pattern
, it is also a subsequence, which is a more general concept. Given a pattern 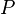 , you can find its occurrences in a string with a string searching algorithm. Finding the longest string which is equal to a substring of two or more strings is known as the longest common substring problem.
, you can find its occurrences in a string with a string searching algorithm. Finding the longest string which is equal to a substring of two or more strings is known as the longest common substring problem.
Example: The string ana is equal to substrings (and subsequences) of banana at two different offsets:
banana ||||| ana|| ||| ana
In the mathematical literature, substrings are also called subwords (in America) or factors (in Europe).
Not including the empty substring, the number of substrings of a string of length  where symbols only occur once, is the number of ways to choose two distinct places between symbols to start/end the substring. Including the very beginning and very end of the string, there are
where symbols only occur once, is the number of ways to choose two distinct places between symbols to start/end the substring. Including the very beginning and very end of the string, there are 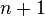 such places. So there are
such places. So there are  non-empty substrings.
non-empty substrings.
Prefix
A prefix of a string is a string 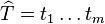 , where
, where 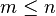 . A proper prefix of a string is not equal to the string itself (
. A proper prefix of a string is not equal to the string itself (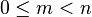 );[1] some sources[2] in addition restrict a proper prefix to be non-empty (
);[1] some sources[2] in addition restrict a proper prefix to be non-empty ( ). A prefix can be seen as a special case of a substring.
). A prefix can be seen as a special case of a substring.
Example: The string ban is equal to a prefix (and substring and subsequence) of the string banana:
banana ||| ban
The square subset symbol is sometimes used to indicate a prefix, so that  denotes that
denotes that 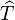 is a prefix of . This defines a binary relation on strings, called the prefix relation, which is a particular kind of prefix order.
is a prefix of . This defines a binary relation on strings, called the prefix relation, which is a particular kind of prefix order.
In formal language theory, the term prefix of a string is also commonly understood to be the set of all prefixes of a string, with respect to that language. See the article on string functions for more details.
Suffix
A suffix of a string is any substring of the string which includes its last letter, including itself. A proper suffix of a string is not equal to the string itself. A more restricted interpretation is that it is also not empty. A suffix can be seen as a special case of a substring.
Example: The string nana is equal to a suffix (and substring and subsequence) of the string banana:
banana |||| nana
A suffix tree for a string is a trie data structure that represents all of its suffixes. Suffix trees have large numbers of applications in string algorithms. The suffix array is a simplified version of this data structure that lists the start positions of the suffixes in alphabetically sorted order; it has many of the same applications.
Border
A border is suffix and prefix of the same string, e.g. "bab" is a border of "babab".
Superstring
Given a set of 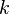 strings
strings 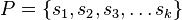 , a superstring of the set is single string that contains every string in as a substring.
For example, a concatenation of the strings of in any order gives a trivial superstring of . For a more interesting example, let
, a superstring of the set is single string that contains every string in as a substring.
For example, a concatenation of the strings of in any order gives a trivial superstring of . For a more interesting example, let 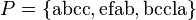 . Then
. Then  is a superstring of , and
is a superstring of , and  is another, shorter superstring of . Generally, we are interested in finding superstrings whose length is small.
is another, shorter superstring of . Generally, we are interested in finding superstrings whose length is small.
See also
- Substring index
- Directed acyclic word graph