Substitution matrix
In bioinformatics and evolutionary biology, a substitution matrix describes the rate at which one character in a sequence changes to other character states over time. Substitution matrices are usually seen in the context of amino acid or DNA sequence alignments, where the similarity between sequences depends on their divergence time and the substitution rates as represented in the matrix.
Background
In the process of evolution, from one generation to the next the amino acid sequences of an organism's proteins are gradually altered through the action of DNA mutations. For example, the sequence
ALEIRYLRD
could mutate into the sequence
ALEINYLRD
in one step, and possibly
AQEINYQRD
over a longer period of evolutionary time. Each amino acid is more or less likely to mutate into various other amino acids. For instance, a hydrophilic residue such as arginine is more likely to be replaced by another hydrophilic residue such as glutamine, than it is to be mutated into a hydrophobic residue such as leucine. (Here, a residue refers to an amino acid stripped of a hydrogen and/or a hydroxyl group and inserted in the polymeric chain of a protein.) This is primarily due to redundancy in the genetic code, which translates similar codons into similar amino acids. Furthermore, mutating an amino acid to a residue with significantly different properties could affect the folding and/or activity of the protein. There is therefore usually strong selective pressure to remove such mutations quickly from a population.
If we have two amino acid sequences in front of us, we should be able to say something about how likely they are to be derived from a common ancestor, or homologous. If we can line up the two sequences using a sequence alignment algorithm such that the mutations required to transform a hypothetical ancestor sequence into both of the current sequences would be evolutionarily plausible, then we'd like to assign a high score to the comparison of the sequences.
To this end, we will construct a 20x20 matrix where the 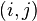 th entry is equal to the probability of the
th entry is equal to the probability of the 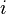 th amino acid being transformed into the
th amino acid being transformed into the 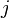 th amino acid in a certain amount of evolutionary time. There are many different ways to construct such a matrix, called a substitution matrix. Here are the most commonly used ones:
th amino acid in a certain amount of evolutionary time. There are many different ways to construct such a matrix, called a substitution matrix. Here are the most commonly used ones:
Identity matrix
The simplest possible substitution matrix would be one in which each amino acid is considered maximally similar to itself, but not able to transform into any other amino acid. This matrix would look like:
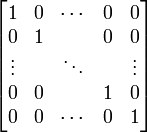
This identity matrix will succeed in the alignment of very similar amino acid sequences but will be miserable at aligning two distantly related sequences. We need to figure out all the probabilities in a more rigorous fashion. It turns out that an empirical examination of previously aligned sequences works best.
Log-odds matrices
We express the probabilities of transformation in what are called log-odds scores. The scores matrix S is defined as
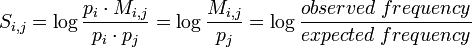
where 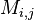 is the probability that amino acid transforms into amino acid and
is the probability that amino acid transforms into amino acid and 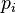 ,
, 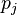 are the frequencies of amino acid i and j. The base of the logarithm is not important, and you will often see the same substitution matrix expressed in different bases.
are the frequencies of amino acid i and j. The base of the logarithm is not important, and you will often see the same substitution matrix expressed in different bases.
PAM
One of the first amino acid substitution matrices, the PAM (Point Accepted Mutation) matrix was developed by Margaret Dayhoff in the 1970s. This matrix is calculated by observing the differences in closely related proteins. The PAM1 matrix estimates what rate of substitution would be expected if 1% of the amino acids had changed. The PAM1 matrix is used as the basis for calculating other matrices by assuming that repeated mutations would follow the same pattern as those in the PAM1 matrix, and multiple substitutions can occur at the same site. Using this logic, Dayhoff derived matrices as high as PAM250. Usually the PAM 30 and the PAM70 are used.
A matrix for more distantly related sequences can be calculated from a matrix for closely related sequences by taking the second matrix to a power. For instance, we can roughly approximate the WIKI2 matrix from the WIKI1 matrix by saying 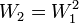 where
where 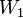 is WIKI1 and
is WIKI1 and 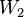 is WIKI2. This is how the PAM250 matrix is calculated.
is WIKI2. This is how the PAM250 matrix is calculated.
BLOSUM
Dayhoff's methodology of comparing closely related species turned out not to work very well for aligning evolutionarily divergent sequences. Sequence changes over long evolutionary time scales are not well approximated by compounding small changes that occur over short time scales. The BLOSUM (BLOck SUbstitution Matrix) series of matrices rectifies this problem. Henikoff constructed these matrices using multiple alignments of evolutionarily divergent proteins. The probabilities used in the matrix calculation are computed by looking at "blocks" of conserved sequences found in multiple protein alignments. These conserved sequences are assumed to be of functional importance within related proteins. To reduce bias from closely related sequences, segments in a block with a sequence identity above a certain threshold were clustered giving weight to each such cluster (Henikoff and Henikoff). For the BLOSUM62 matrix, this threshold was set at 62%. Pairs frequencies were then counted between clusters, hence pairs were only counted between segments less than 62% identical. One would use a higher numbered BLOSUM matrix for aligning two closely related sequences and a lower number for more divergent sequences.
It turns out that the BLOSUM62 matrix does an excellent job detecting similarities in distant sequences, and this is the matrix used by default in most recent alignment applications such as BLAST.
Differences between PAM and BLOSUM
- PAM matrices are based on an explicit evolutionary model (i.e. replacements are counted on the branches of a phylogenetic tree), whereas the BLOSUM matrices are based on an implicit model of evolution.
- The PAM matrices are based on mutations observed throughout a global alignment, this includes both highly conserved and highly mutable regions. The BLOSUM matrices are based only on highly conserved regions in series of alignments forbidden to contain gaps.
- The method used to count the replacements is different: unlike the PAM matrix, the BLOSUM procedure uses groups of sequences within which not all mutations are counted the same.
- Higher numbers in the PAM matrix naming scheme denote larger evolutionary distance, while larger numbers in the BLOSUM matrix naming scheme denote higher sequence similarity and therefore smaller evolutionary distance. Example: PAM150 is used for more distant sequences than PAM100; BLOSUM62 is used for closer sequences than BLOSUM50.
Extensions and improvements
Many specialized substitution matrices have been developed that describe the amino acid substitution rates in specific structural or sequence contexts, such as in transmembrane alpha helices,[1] for combinations of secondary structure states and solvent accessibility states,[2][3][4] or for local sequence-structure contexts.[5] These context-specific substitution matrices lead to generally improved alignment quality at some cost of speed but are not yet widely used. Recently, sequence context-specific amino acid similarities have been derived that do not need substitution matrices but that rely on a library of sequence contexts instead. Using this idea, a context-specific extension of the popular BLAST program has been demonstrated to achieve a twofold sensitivity improvement for remotely related sequences over BLAST at similar speeds (CS-BLAST).
Terminology
Although "transition matrix" is often used interchangeably with "substitution matrix" in fields other than bioinformatics, the former term is problematic in bioinformatics. With regards to nucleotide substitutions, "transition" is also used to indicate those substitutions that are between the two-ring purines (A → G and G → A) or are between the one-ring pyrimidines (C → T and T → C). Because these substitutions do not require a change in the number of rings, they occur more frequently than the other substitutions. "Transversion" is the term used to indicate the slower-rate substitutions that change a purine to a pyrimidine or vice versa (A ↔ C, A ↔ T, G ↔ C, and G ↔ T).
See also
References
- ↑ Müller, T; Rahmann, S; Rehmsmeier, M (2001). "Non-symmetric score matrices and the detection of homologous transmembrane proteins". Bioinformatics (Oxford, England). 17 Suppl 1: S182–9. doi:10.1093/bioinformatics/17.suppl_1.s182. PMID 11473008.
- ↑ Rice, DW; Eisenberg, D (1997). "A 3D-1D substitution matrix for protein fold recognition that includes predicted secondary structure of the sequence". Journal of Molecular Biology 267 (4): 1026–38. doi:10.1006/jmbi.1997.0924. PMID 9135128.
- ↑ Gong, Sungsam; Blundell, Tom L. (2008). Levitt, Michael, ed. "Discarding functional residues from the substitution table improves predictions of active sites within three-dimensional structures". PLoS Computational Biology 4 (10): e1000179. doi:10.1371/journal.pcbi.1000179. PMC 2527532. PMID 18833291.
- ↑ Goonesekere, NC; Lee, B (2008). "Context-specific amino acid substitution matrices and their use in the detection of protein homologs". Proteins 71 (2): 910–9. doi:10.1002/prot.21775. PMID 18004781.
- ↑ Huang, YM; Bystroff, C (2006). "Improved pairwise alignments of proteins in the Twilight Zone using local structure predictions". Bioinformatics 22 (4): 413–22. doi:10.1093/bioinformatics/bti828. PMID 16352653.
Further reading
- Altschul, SF (1991). "Amino acid substitution matrices from an information theoretic perspective". Journal of Molecular Biology 219 (3): 555–65. doi:10.1016/0022-2836(91)90193-A. PMID 2051488.
- Dayhoff, M. O.; Schwartz, R. M.; Orcutt, B. C. (1978). "A model of evolutionary change in proteins". Atlas of Protein Sequence and Structure 5 (3): 345–352.
- Henikoff, S; Henikoff, JG (1992). "Amino acid substitution matrices from protein blocks". Proceedings of the National Academy of Sciences of the United States of America 89 (22): 10915–9. doi:10.1073/pnas.89.22.10915. PMC 50453. PMID 1438297.
- Eddy, SR (2004). "Where did the BLOSUM62 alignment score matrix come from?". Nature Biotechnology 22 (8): 1035–6. doi:10.1038/nbt0804-1035. PMID 15286655.
- Henikoff, S; Henikoff, JG (1992). "Amino acid substitution matrices from protein blocks". Proceedings of the National Academy of Sciences of the United States of America 89 (22): 10915–9. doi:10.1073/pnas.89.22.10915. PMC 50453. PMID 1438297.