Stochastic programming
In the field of mathematical optimization, stochastic programming is a framework for modeling optimization problems that involve uncertainty. Whereas deterministic optimization problems are formulated with known parameters, real world problems almost invariably include some unknown parameters. When the parameters are known only within certain bounds, one approach to tackling such problems is called robust optimization. Here the goal is to find a solution which is feasible for all such data and optimal in some sense. Stochastic programming models are similar in style but take advantage of the fact that probability distributions governing the data are known or can be estimated. The goal here is to find some policy that is feasible for all (or almost all) the possible data instances and maximizes the expectation of some function of the decisions and the random variables. More generally, such models are formulated, solved analytically or numerically, and analyzed in order to provide useful information to a decision-maker.[1]
As an example, consider two-stage linear programs. Here the decision maker takes some action in the first stage, after which a random event occurs affecting the outcome of the first-stage decision. A recourse decision can then be made in the second stage that compensates for any bad effects that might have been experienced as a result of the first-stage decision. The optimal policy from such a model is a single first-stage policy and a collection of recourse decisions (a decision rule) defining which second-stage action should be taken in response to each random outcome.
Stochastic programming has applications in a broad range of areas ranging from finance to transportation to energy optimization.[2][3] This article uses the example of an investment portfolio over time.
Two-Stage Problems
The basic idea of two-stage stochastic programming is that (optimal) decisions should be based on data available at the time the decisions are made and should not depend on future observations. Two-stage formulation is widely used in stochastic programming. The general formulation of a two-stage stochastic programming problem is given by:
![\min_{x\in X}\{ g(x)= f(x) + E[Q(x,\xi)]\}](../I/m/aa9a6f21757a388b66242cb5158cea6d.png)
where 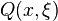 is the optimal value of the second-stage problem
is the optimal value of the second-stage problem
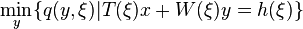
The classical two-stage linear stochastic programming problems can be formulated as
![\begin{array}{llr}
\min\limits_{x\in \mathbb{R}^n} &g(x)= c^T x + E[Q(x,\xi)] & \\
\text{subject to} & Ax = b &\\
& x \geq 0 &
\end{array}](../I/m/e90d2e7e86455b8c804f298106264345.png)
where is the optimal value of the second-stage problem
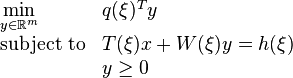
In such formulation 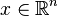 is the first-stage decision variable vector,
is the first-stage decision variable vector, 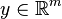 is the second-stage decision variable vector, and
is the second-stage decision variable vector, and 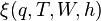 contains the data of the second-stage problem. In this formulation, at the first stage we have to make a "here-and-now" decision
contains the data of the second-stage problem. In this formulation, at the first stage we have to make a "here-and-now" decision 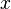 before the realization of the uncertain data
before the realization of the uncertain data 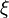 , viewed as a random vector, is known. At the second stage, after a realization of becomes available, we optimize our behavior by solving an appropriate optimization problem.
, viewed as a random vector, is known. At the second stage, after a realization of becomes available, we optimize our behavior by solving an appropriate optimization problem.
At the first stage we optimize (minimize in the above formulation) the cost 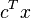 of the first-stage decision plus the expected cost of the (optimal) second-stage decision. We can view the second-stage problem simply as an optimization problem which describes our supposedly optimal behavior when the uncertain data is revealed, or we can consider its solution as a recourse action where the term
of the first-stage decision plus the expected cost of the (optimal) second-stage decision. We can view the second-stage problem simply as an optimization problem which describes our supposedly optimal behavior when the uncertain data is revealed, or we can consider its solution as a recourse action where the term 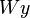 compensates for a possible inconsistency of the system
compensates for a possible inconsistency of the system 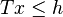 and
and 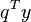 is the cost of this recourse action.
is the cost of this recourse action.
The considered two-stage problem is linear because the objective functions and the constraints are linear. Conceptually this is not essential and one can consider more general two-stage stochastic programs. For example, if the first-stage problem is integer, one could add integrality constraints to the first-stage problem so that the feasible set is discrete. Non-linear objectives and constraints could also be incorporated if needed.[4]
Distributional assumption
The formulation of the above two-stage problem assumes that the second-stage data can be modeled as a random vector with a known probability distribution (not just uncertain). This would be justified in many situations. For example could be information derived from historical data and the distribution does not significantly change over the considered period of time. In such situations one may reliably estimate the required probability distribution and the optimization on average could be justified by the Law of Large Numbers. Another example is that could be realizations of a simulation model whose outputs are stochastic. The empirical distribution of the sample could be used as an approximation to the true but unknown output distribution.
Discretization
To solve the two-stage stochastic problem numerically, one often need to assume that the random vector has a finite number of possible realizations, called scenarios, say 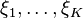 , with respective probability masses
, with respective probability masses 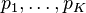 . Then the expectation in the first-stage problem's objective function can be written as the summation:
. Then the expectation in the first-stage problem's objective function can be written as the summation:
![E[Q(x,\xi)]=\sum\limits_{k=1}^{K} p_kQ(x,\xi_k)](../I/m/23d3b03c74f138ee71877ad1c195aeca.png)
and, moreover, the two-stage problem can be formulated as one large linear programming problem (this is called the deterministic equivalent of the original problem, see section § Deterministic equivalent of a stochastic problem).
When has an infinite (or very large) number of possible realizations the standard approach is then to represent this distribution by scenarios. This approach raises three questions, namely:
- How to construct scenarios, see § Scenario Construction;
- How to solve the deterministic equivalent. Optimizers such as CPLEX, GLPK and Gurobi can solve large linear/nonlinear problems. NEOS [5] server hosted at the Argonne National Laboratory allows free access to many modern solvers. The structure of a deterministic equivalent is particularly amenable to apply decomposition methods,[6] such as Benders' decomposition or scenario decomposition;
- How to measure quality of the obtained solution with respect to the "true" optimum.
These questions are not independent. For example, the number of scenarios constructed will affect both the tractability of the deterministic equivalent and the quality of the obtained solutions.
Stochastic linear program
A stochastic linear program is a specific instance of the classical two-stage stochastic program. A stochastic LP is built from a collection of multi-period linear programs (LPs), each having the same structure but somewhat different data. The 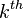 two-period LP, representing the scenario, may be regarded as having the following form:
two-period LP, representing the scenario, may be regarded as having the following form:
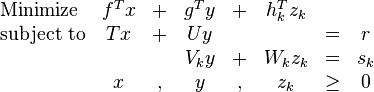
The vectors and 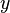 contain the first-period variables, whose values must be chosen immediately. The vector
contain the first-period variables, whose values must be chosen immediately. The vector 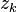 contains all of the variables for subsequent periods. The constraints
contains all of the variables for subsequent periods. The constraints 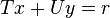 involve only first-period variables and are the same in every scenario. The other constraints involve variables of later periods and differ in some respects from scenario to scenario, reflecting uncertainty about the future.
involve only first-period variables and are the same in every scenario. The other constraints involve variables of later periods and differ in some respects from scenario to scenario, reflecting uncertainty about the future.
Note that solving the two-period LP is equivalent to assuming the scenario in the second period with no uncertainty. In order to incorporate uncertainties in the second stage, one should assign probabilities to different scenarios and solve the corresponding deterministic equivalent.
Deterministic equivalent of a stochastic problem
With a finite number of scenarios, two-stage stochastic linear programs can be modelled as large linear programming problems. This formulation is often called the deterministic equivalent linear program, or abbreviated to deterministic equivalent. (Strictly speaking a deterministic equivalent is any mathematical program that can be used to compute the optimal first-stage decision, so these will exist for continuous probability distributions as well, when one can represent the second-stage cost in some closed form.)
For example, to form the deterministic equivalent to the above stochastic linear program, we assign a probability 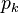 to each scenario
to each scenario 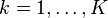 . Then we can minimize the expected value of the objective, subject to the constraints from all scenarios:
. Then we can minimize the expected value of the objective, subject to the constraints from all scenarios:
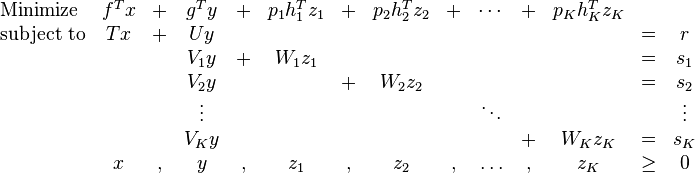
We have a different vector of later-period variables for each scenario 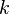 . The first-period variables and are the same in every scenario, however, because we must make a decision for the first period before we know which scenario will be realized. As a result, the constraints involving just and need only be specified once, while the remaining constraints must be given separately for each scenario.
. The first-period variables and are the same in every scenario, however, because we must make a decision for the first period before we know which scenario will be realized. As a result, the constraints involving just and need only be specified once, while the remaining constraints must be given separately for each scenario.
Scenario Construction
In practice it might be possible to construct scenarios by eliciting expert's opinions on the future. The number of constructed scenarios should be relatively modest so that the obtained deterministic equivalent can be solved with reasonable computational effort. It is often claimed that a solution that is optimal using only a few scenarios provides more adaptable plans than one that assumes a single scenario only. In some cases such a claim could be verified by a simulation. In theory some measures of guarantee that an obtained solution solves the original problem with reasonable accuracy. Typically in applications only the first stage optimal solution 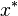 has a practical value since almost always a "true" realization of the random data will be different from the set of constructed (generated) scenarios.
has a practical value since almost always a "true" realization of the random data will be different from the set of constructed (generated) scenarios.
Suppose contains 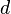 independent random components, each of which has three possible realizations (for example, future realizations of each random parameters are classified as low, medium and high), then the total number of scenarios is
independent random components, each of which has three possible realizations (for example, future realizations of each random parameters are classified as low, medium and high), then the total number of scenarios is 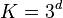 . Such exponential growth of the number of scenarios makes model development using expert opinion very difficult even for reasonable size . The situation becomes even worse if some random components of have continuous distributions.
. Such exponential growth of the number of scenarios makes model development using expert opinion very difficult even for reasonable size . The situation becomes even worse if some random components of have continuous distributions.
Monte Carlo sampling and Sample Average Approximation (SAA) Method
A common approach to reduce the scenario set to a manageable size is by using Monte Carlo simulation. Suppose the total number of scenarios is very large or even infinite. Suppose further that we can generate a sample 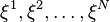 of
of 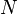 replications of the random vector . Usually the sample is assumed to be independent identically distributed (i.i.d sample). Given a sample, the expectation function
replications of the random vector . Usually the sample is assumed to be independent identically distributed (i.i.d sample). Given a sample, the expectation function ![q(x)=E[Q(x,\xi)]](../I/m/46bb451ee2d7e12bd8d868f4c61556c3.png) is approximated by the sample average
is approximated by the sample average
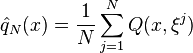
and consequently the first-stage problem is given by
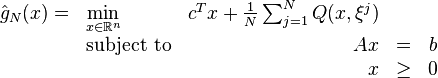
This formulation is known as the Sample Average Approximation method. The SAA problem is a function of the considered sample and in that sense is random. For a given sample the SAA problem is of the same form as a two-stage stochastic linear programming problem with the scenarios 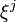 .,
., 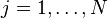 , each taken with the same probability
, each taken with the same probability 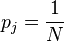 .
.
Statistical Inference
Consider the following stochastic programming problem
![\min\limits_{x\in X}\{ g(x) = f(x)+E[Q(x,\xi)] \}](../I/m/82f36a8801521f9d767323346d881945.png)
Here 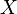 is a nonempty closed subset of
is a nonempty closed subset of 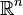 , is a random vector whose probability distribution
, is a random vector whose probability distribution 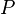 is supported on a set
is supported on a set 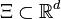 , and
, and 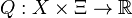 . In the framework of two-stage stochastic programming, is given by the optimal value of the corresponding second-stage problem.
. In the framework of two-stage stochastic programming, is given by the optimal value of the corresponding second-stage problem.
Assume that 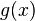 is well defined and finite valued for all
is well defined and finite valued for all 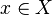 . This implies that for every the value is finite almost surely.
. This implies that for every the value is finite almost surely.
Suppose that we have a sample 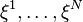 of realizations of the random vector . This random sample can be viewed as historical data of observations of , or it can be generated by Monte Carlo sampling techniques. Then we can formulate a corresponding sample average approximation
of realizations of the random vector . This random sample can be viewed as historical data of observations of , or it can be generated by Monte Carlo sampling techniques. Then we can formulate a corresponding sample average approximation
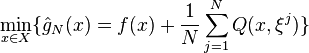
By the Law of Large Numbers we have that, under some regularity conditions  converges pointwise with probability 1 to
converges pointwise with probability 1 to ![E[Q(x,\xi)]](../I/m/eed1927613821187b6aee908639a93ff.png) as
as  . Moreover, under mild additional conditions the convergence is uniform. We also have
. Moreover, under mild additional conditions the convergence is uniform. We also have ![E[\hat{g}_N(x)]=g(x)](../I/m/a96927a9bf39d401ffa708227e945e6f.png) , i.e.,
, i.e., 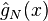 is an unbiased estimator of . Therefore it is natural to expect that the optimal value and optimal solutions of the SAA problem converge to their counterparts of the true problem as .
is an unbiased estimator of . Therefore it is natural to expect that the optimal value and optimal solutions of the SAA problem converge to their counterparts of the true problem as .
Consistency of SAA estimators
Suppose the feasible set of the SAA problem is fixed, i.e., it is independent of the sample. Let  and
and 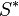 be the optimal value and the set of optimal solutions, respectively, of the true problem and let
be the optimal value and the set of optimal solutions, respectively, of the true problem and let 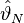 and
and 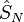 be the optimal value and the set of optimal solutions, respectively, of the SAA problem.
be the optimal value and the set of optimal solutions, respectively, of the SAA problem.
- Let
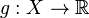 and
and 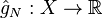 be a sequence of (deterministic) real valued functions. The following two properties are equivalent:
be a sequence of (deterministic) real valued functions. The following two properties are equivalent:
- for any
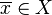 and any sequence
and any sequence 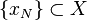 converging to
converging to 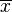 it follows that
it follows that 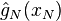 converges to
converges to 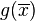
- the function
 is continuous on and
is continuous on and 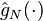 converges to
converges to 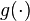 uniformly on any compact subset of
uniformly on any compact subset of
- for any
- If the objective of the SAA problem converges to the true problem's objective with probability 1, as , uniformly on the feasible set . Then converges to with probability 1 as .
- Suppose that there exists a compact set
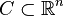 such that
such that
- the set
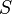 of optimal solutions of the true problem is nonempty and is contained in
of optimal solutions of the true problem is nonempty and is contained in 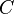
- the function is finite valued and continuous on
- the sequence of functions converges to with probability 1, as , uniformly in
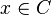
- for large enough the set is nonempty and
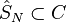 with probability 1
with probability 1
- the set
- then
 and
and 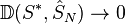 with probability 1 as . Note that
with probability 1 as . Note that 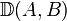 denotes the deviation of set
denotes the deviation of set 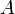 from set
from set 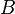 , defined as
, defined as
- then
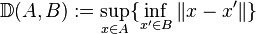
In some situations the feasible set of the SAA problem is estimated, then the corresponding SAA problem takes the form
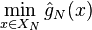
where 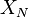 is a subset of depending on the sample and therefore is random. Nevertheless consistency results for SAA estimators can still be derived under some additional assumptions:
is a subset of depending on the sample and therefore is random. Nevertheless consistency results for SAA estimators can still be derived under some additional assumptions:
- Suppose that there exists a compact set such that
- the set of optimal solutions of the true problem is nonempty and is contained in
- the function is finite valued and continuous on
- the sequence of functions converges to with probability 1, as , uniformly in
- for large enough the set is nonempty and with probability 1
- if
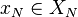 and
and 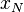 converges with probability 1 to a point , then
converges with probability 1 to a point , then - for some point
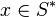 there exists a sequence such that
there exists a sequence such that 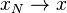 with probability 1.
with probability 1.
- the set
- then and with probability 1 as .
- then
Asymptotics of the SAA optimal value
Suppose the sample is i.i.d. and fix a point . Then the sample average estimator , of , is unbiased and have variance 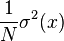 , where
, where ![\sigma^2(x):=Var[Q(x,\xi)]](../I/m/4c0a29ef9866efddca9be09a02954e49.png) is supposed to be finite. Moreover, by the central limit theorem we have that
is supposed to be finite. Moreover, by the central limit theorem we have that
![\sqrt{N} [\hat{g}_N- g(x)] \xrightarrow{\mathcal{D}} Y_x](../I/m/a38f3abc4a886a2afe95368bc8104e89.png)
where 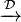 denotes convergence in distribution and
denotes convergence in distribution and 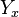 has a normal distribution with mean
has a normal distribution with mean 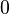 and variance
and variance 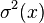 , written as
, written as 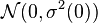 .
.
In other words, has asymptotically normal distribution, i.e., for large , has approximately normal distribution with mean and variance . This leads to the following (approximate) 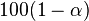 % confidence interval for
% confidence interval for 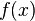 :
:
![\left[ \hat{g}_N(x)-z_{\alpha/2} \frac{\hat{\sigma}(x)}{\sqrt{N}}, \hat{g}_N(x)+z_{\alpha/2} \frac{\hat{\sigma}(x)}{\sqrt{N}}\right]](../I/m/c17b8f96a4c0c7625d52d519e4c44203.png)
where 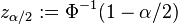 (here
(here 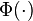 denotes the cdf of the standard normal distribution) and
denotes the cdf of the standard normal distribution) and
![\hat{\sigma}^2(x) := \frac{1}{N-1}\sum_{j=1}^{N} \left[ Q(x,\xi^j)-\frac{1}{N} \sum_{j=1}^N Q(x,\xi^j) \right]^2](../I/m/39195e354606db2bbbd9e08a02a99afe.png)
is the sample variance estimate of . That is, the error of estimation of is (stochastically) of order 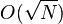 .
.
Multistage Portfolio Optimization
The following is an example from finance of multi-stage stochastic programming.
Suppose that at time 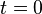 we have initial capital
we have initial capital 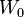 to invest in
to invest in  assets. Suppose further that we are allowed to rebalance our portfolio at times
assets. Suppose further that we are allowed to rebalance our portfolio at times 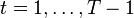 but without injecting additional cash into it. At each period
but without injecting additional cash into it. At each period 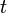 we make a decision about redistributing the current wealth
we make a decision about redistributing the current wealth 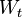 among the assets. Let
among the assets. Let 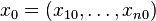 be the initial amounts invested in the n assets. We require that each
be the initial amounts invested in the n assets. We require that each 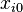 is nonnegative and that the balance equation
is nonnegative and that the balance equation 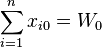 should hold.
should hold.
Consider the total returns 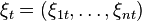 for each period
for each period 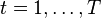 . This forms a vector-valued random process
. This forms a vector-valued random process 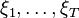 . At time period
. At time period  , we can rebalance the portfolio by specifying the amounts
, we can rebalance the portfolio by specifying the amounts 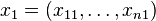 invested in the respective assets. At that time the returns in the first period have been realized so it is reasonable to use this information in the rebalancing decision. Thus, the second-stage decisions, at time , are actually functions of realization of the random vector
invested in the respective assets. At that time the returns in the first period have been realized so it is reasonable to use this information in the rebalancing decision. Thus, the second-stage decisions, at time , are actually functions of realization of the random vector 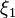 , i.e.,
, i.e., 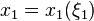 . Similarly, at time the decision
. Similarly, at time the decision 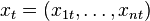 is a function
is a function ![x_t=x_t(\xi_{[t]})](../I/m/c59634c6b60833ac426fa573666240ef.png) of the available information given by
of the available information given by ![\xi_{[t]}=(\xi_{1},\dots,\xi_{t})](../I/m/b2e327c1ef372276632fd8a9c7e619ea.png) the history of the random process up to time . A sequence of functions ,
the history of the random process up to time . A sequence of functions , 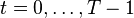 , with
, with 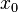 being constant, defines an implementable policy of the decision process. It is said that such a policy is feasible if it satisfies the model constraints with probability 1, i.e., the nonnegativity constraints
being constant, defines an implementable policy of the decision process. It is said that such a policy is feasible if it satisfies the model constraints with probability 1, i.e., the nonnegativity constraints ![x_{it}(\xi_{[t]})\geq 0](../I/m/1510eaa2f553c182a140fad3fc0a4e0f.png) ,
, 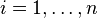 , , and the balance of wealth constraints,
, , and the balance of wealth constraints,
![\sum_{i=1}^{n}x_{it}(\xi_{[t]}) = W_t,](../I/m/af83f62b335b387ae7e4c3c755b52c38.png)
where in period the wealth is given by
![W_t = \sum_{i=1}^{n}\xi_{it} x_{i,t-1}(\xi_{[t-1]}),](../I/m/24b252899181231eba1f8825e67618ea.png)
which depends on the realization of the random process and the decisions up to time .
Suppose the objective is to maximize the expected utility of this wealth at the last period, that is, to consider the problem
![\max E[U(W_T)].](../I/m/8d8ceae3d00a0bd3f2fe0ad492678729.png)
This is a multistage stochastic programming problem, where stages are numbered from to 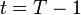 . Optimization is performed over all implementable and feasible policies. To complete the problem description one also needs to define the probability distribution of the random process . This can be done in various ways. For example, one can construct a particular scenario tree defining time evolution of the process. If at every stage the random return of each asset is allowed to have two continuations, independent of other assets, then the total number of scenarios is
. Optimization is performed over all implementable and feasible policies. To complete the problem description one also needs to define the probability distribution of the random process . This can be done in various ways. For example, one can construct a particular scenario tree defining time evolution of the process. If at every stage the random return of each asset is allowed to have two continuations, independent of other assets, then the total number of scenarios is 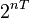 .
.
In order to write dynamic programming equations, consider the above multistage problem backward in time. At the last stage , a realization ![\xi_{[T-1]}=(\xi_{1},\dots,\xi_{T-1})](../I/m/9be3f5000b48028555274c7e8db7d6f7.png) of the random process is known and
of the random process is known and 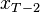 has been chosen. Therefore, one needs to solve the following problem
has been chosen. Therefore, one needs to solve the following problem
![\begin{array}{lrclr}
\max\limits_{x_{T-1}} & E[U(W_T)|\xi_{[T-1]}] & \\
\text{subject to} & W_T &=& \sum_{i=1}^{n}\xi_{iT}x_{i,T-1} \\
&\sum_{i=1}^{n}x_{i,T-1}&=&W_{T-1}\\
& x_{T-1} &\geq& 0
\end{array}](../I/m/d784a26949d29f7673cdc834b94a4521.png)
where ![E[U(W_T)|\xi_{[T-1]}]](../I/m/531fd941c3cf4a90379e737b3fc1fd18.png) denotes the conditional expectation of
denotes the conditional expectation of 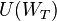 given
given ![\xi_{[T-1]}](../I/m/6b28d68b9340ae7433ea57db45bce290.png) . The optimal value of the above problem depends on
. The optimal value of the above problem depends on 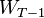 and and is denoted
and and is denoted ![Q_{T-1}(W_{T-1},\xi_{[T-1]})](../I/m/56a0787d2287acbc1a085fb2af934f57.png) .
.
Similarly, at stages 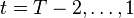 , one should solve the problem
, one should solve the problem
![\begin{array}{lrclr}
\max\limits_{x_{t}} & E[Q_{t+1}(W_{t+1},\xi_{[t+1]})|\xi_{[t]}] & \\
\text{subject to} & W_{t+1} &=& \sum_{i=1}^{n}\xi_{i,t+1}x_{i,t} \\
&\sum_{i=1}^{n}x_{i,t}&=&W_{t}\\
& x_{t} &\geq& 0
\end{array}](../I/m/f7419680184a3d1b4b3fb2425933b84c.png)
whose optimal value is denoted by ![Q_{t}(W_{t},\xi_{[t]})](../I/m/205eaa3519f8286756aa12367755ea80.png) . Finally, at stage , one solves the problem
. Finally, at stage , one solves the problem
![\begin{array}{lrclr}
\max\limits_{x_{0}} & E[Q_{1}(W_{1},\xi_{[1]})] & \\
\text{subject to} & W_{1} &=& \sum_{i=1}^{n}\xi_{i,1}x_{i0} \\
&\sum_{i=1}^{n}x_{i0}&=&W_{0}\\
& x_{0} &\geq& 0
\end{array}](../I/m/b7ef17d5d17926655f1a0e708ec467dc.png)
Stagewise independent random process
For a general distribution of the process 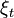 , it may be hard to solve these dynamic programming equations. The situation simplifies dramatically if the process is stagewise independent, i.e., is (stochastically) independent of
, it may be hard to solve these dynamic programming equations. The situation simplifies dramatically if the process is stagewise independent, i.e., is (stochastically) independent of 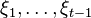 for
for 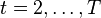 . In this case, the corresponding conditional expectations become unconditional expectations, and the function
. In this case, the corresponding conditional expectations become unconditional expectations, and the function 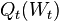 , does not depend on
, does not depend on ![\xi_{[t]}](../I/m/96cd9075848d14e54640f283ba9b4fe5.png) . That is,
. That is, 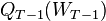 is the optimal value of the problem
is the optimal value of the problem
![\begin{array}{lrclr}
\max\limits_{x_{T-1}} & E[U(W_T)] & \\
\text{subject to} & W_T &=& \sum_{i=1}^{n}\xi_{iT}x_{i,T-1} \\
&\sum_{i=1}^{n}x_{i,T-1}&=&W_{T-1}\\
& x_{T-1} &\geq& 0
\end{array}](../I/m/46a6e9e2dc56eb9a9961c2eefb9948ec.png)
and is the optimal value of
![\begin{array}{lrclr}
\max\limits_{x_{t}} & E[Q_{t+1}(W_{t+1})] & \\
\text{subject to} & W_{t+1} &=& \sum_{i=1}^{n}\xi_{i,t+1}x_{i,t} \\
&\sum_{i=1}^{n}x_{i,t}&=&W_{t}\\
& x_{t} &\geq& 0
\end{array}](../I/m/3d06ac0233f66acb8f2608a6e5cb4bee.png)
for .
Stochastic programming for nonlinear optimization
Many of the optimization problems in science and engineering involve nonlinear objective functions with uncertain model. In these cases, stochastic programming is applied to optimize the expected objective (sample average) over a set of realizations generated using Monte Carlo simulation.
For expensive function evaluations, model selection is used to reduce the number of realizations. Techniques such as out-of-sample validation is used to reduce the number of required realizations and the number of representative realizations. Recently, optimization with sample validation (OSV) is proposed to significantly reduce the computational cost in stochastic programming for expensive function evaluations. Optimization with sample validation determines, in a systematic way, the number of realizations in optimization to adequately represent the entire set. Stochastic programming with OSV has been applied for optimization of oil field development planning (well placement and control optimization). [7]
Biological applications
Stochastic dynamic programming is frequently used to model animal behaviour in such fields as behavioural ecology.[8][9] Empirical tests of models of optimal foraging, life-history transitions such as fledging in birds and egg laying in parasitoid wasps have shown the value of this modelling technique in explaining the evolution of behavioural decision making. These models are typically many-staged, rather than two-staged.
Economic applications
Stochastic dynamic programming is a useful tool in understanding decision making under uncertainty. The accumulation of capital stock under uncertainty is one example; often it is used by resource economists to analyze bioeconomic problems[10] where the uncertainty enters in such as weather, etc.
Software tools
Modelling languages
All discrete stochastic programming problems can be represented with any algebraic modeling language, manually implementing explicit or implicit non-anticipativity to make sure the resulting model respects the structure of the information made available at each stage. An instance of an SP problem generated by a general modelling language tends to grow quite large (linearly in the number of scenarios), and its matrix looses the structure that is intrinsic to this class of problems, which could otherwise be exploited at solution time by specific decomposition algorithms. Extensions to modelling languages specifically designed for SP are starting to appear, see:
- AIMMS - supports the definition of SP problems
- FuncDesigner - free software that includes stochastic programming and optimization by OpenOpt solvers; example1, example2, example3
- SAMPL - a set of extensions to AMPL specifically designed to express stochastic programs (includes syntax for chance constraints, integrated chance constraints and Robust Optimization problems)
They both can generate SMPS instance level format, which conveys in a non-redundant form the structure of the problem to the solver.
Solvers
- FortSP - solver for stochastic programming problems; it accepts SMPS input and implements various decomposition algorithms.
- NEOS Solvers - Three solvers are available in the Neos Server: Bouncing Nested Benders Solvers (BNBS) for multi-stage stochastic linear programs, ddsip for two-stage stochastic programs with integer recourse, and Stochastic Decomposition (SD) for two-stage stochastic linear programs.
- COIN-OR Stochastic Modeling Interface - An open source project within COIN-OR. It can read Stochastic MPS[11] input format as well as supports direct interfaces for scenario input, and generates the deterministic equivalent linear program for solution by COIN-OR solvers.
See also
- Probabilistic-based design optimization
- SAMPL algebraic modeling language
- Scenario optimization
- Stochastic optimization
References
- ↑ Shapiro, Alexander; Dentcheva, Darinka; Ruszczyński, Andrzej (2009). Lectures on stochastic programming: Modeling and theory. MPS/SIAM Series on Optimization 9. Philadelphia, PA: Society for Industrial and Applied Mathematics (SIAM). Mathematical Programming Society (MPS). pp. xvi+436. ISBN 978-0-89871-687-0. MR 2562798.
- ↑ Stein W. Wallace and William T. Ziemba (eds.). Applications of Stochastic Programming. MPS-SIAM Book Series on Optimization 5, 2005.
- ↑ Applications of stochastic programming are described at the following website, Stochastic Programming Community.
- ↑ Shapiro, Alexander; Philpott, Andy. A tutorial on Stochastic Programming.
- ↑ http://www.neos-server.org/neos/
- ↑ Ruszczyński, Andrzej; Shapiro, Alexander (2003). Stochastic Programming. Handbooks in Operations Research and Management Science 10. Philadelphia: Elsevier. p. 700. ISBN 978-0444508546.
- ↑ Closed-loop field development optimization under uncertainty. http://dx.doi.org/10.2118/173219-MS
- ↑ Mangel, M. & Clark, C. W. 1988. Dynamic modeling in behavioral ecology. Princeton University Press ISBN 0-691-08506-4
- ↑ Houston, A. I & McNamara, J. M. 1999. Models of adaptive behaviour: an approach based on state. Cambridge University Press ISBN 0-521-65539-0
- ↑ Howitt, R., Msangi, S., Reynaud, A and K. Knapp. 2002. "Using Polynomial Approximations to Solve Stochastic Dynamic Programming Problems: or A "Betty Crocker " Approach to SDP." University of California, Davis, Department of Agricultural and Resource Economics Working Paper.
- ↑ J.R. Birge, M.A.H. Dempster, H.I. Gassmann, E.A. Gunn, A.J. King and S.W. Wallace, A standard input format for multiperiod stochastic linear programs, COAL Newsletter #17 (1987) pp. 1-19.
Further reading
- John R. Birge and François V. Louveaux. Introduction to Stochastic Programming. Springer Verlag, New York, 1997.
- Kall, Peter; Wallace, Stein W. (1994). Stochastic programming. Wiley-Interscience Series in Systems and Optimization. Chichester: John Wiley & Sons, Ltd. pp. xii+307. ISBN 0-471-95158-7. MR 1315300.
- G. Ch. Pflug: Optimization of Stochastic Models. The Interface between Simulation and Optimization. Kluwer, Dordrecht, 1996.
- Andras Prekopa. Stochastic Programming. Kluwer Academic Publishers, Dordrecht, 1995.
- Andrzej Ruszczynski and Alexander Shapiro (eds.) (2003) Stochastic Programming. Handbooks in Operations Research and Management Science, Vol. 10, Elsevier.
- Shapiro, Alexander; Dentcheva, Darinka; Ruszczyński, Andrzej (2009). Lectures on stochastic programming: Modeling and theory. MPS/SIAM Series on Optimization 9. Philadelphia, PA: Society for Industrial and Applied Mathematics (SIAM). Mathematical Programming Society (MPS). pp. xvi+436. ISBN 978-0-89871-687-0. MR 2562798.
- Stein W. Wallace and William T. Ziemba (eds.) (2005) Applications of Stochastic Programming. MPS-SIAM Book Series on Optimization 5
- King, Alan J.; Wallace, Stein W. (2012). Modeling with Stochastic Programming. Springer Series in Operations Research and Financial Engineering. New York: Springer. ISBN 978-0-387-87816-4.