Statistical benchmarking
In statistics, benchmarking is a method of using auxiliary information to adjust the sampling weights used in an estimation process, in order to yield more accurate estimates of totals.
Suppose we have a population where each unit 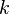 has a "value"
has a "value" 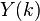 associated with it. For example, could be a wage of an employee , or the cost of an item . Suppose we want to estimate the sum
associated with it. For example, could be a wage of an employee , or the cost of an item . Suppose we want to estimate the sum 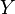 of all the . So we take a sample of the , get a sampling weight W(k) for all sampled , and then sum up
of all the . So we take a sample of the , get a sampling weight W(k) for all sampled , and then sum up 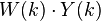 for all sampled .
for all sampled .
One property usually common to the weights 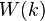 described here is that if we sum them over all sampled , then this sum is an estimate of the total number of units in the population (for example, the total employment, or the total number of items). Because we have a sample, this estimate of the total number of units in the population will differ from the true population total. Similarly, the estimate of total (where we sum for all sampled ) will also differ from true population total.
described here is that if we sum them over all sampled , then this sum is an estimate of the total number of units in the population (for example, the total employment, or the total number of items). Because we have a sample, this estimate of the total number of units in the population will differ from the true population total. Similarly, the estimate of total (where we sum for all sampled ) will also differ from true population total.
We do not know what the true population total value is (if we did, there would be no point in sampling!). Yet often we do know what the sum of the are over all units in the population. For example, we may not know the total earnings of the population or the total cost of the population, but often we know the total employment or total volume of sales. And even if we don't know these exactly, there often are surveys done by other organizations or at earlier times, with very accurate estimates of these auxiliary quantities. One important function of a population census is to provide data that can be used for benchmarking smaller surveys.
The benchmarking procedure begins by first breaking the population into benchmarking cells. Cells are formed by grouping units together that share common characteristics, for example, similar , yet anything can be used that enhances the accuracy of the final estimates. For each cell 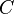 , we let
, we let 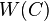 be the sum of all , where the sum is taken over all sampled in the cell . For each cell , we let
be the sum of all , where the sum is taken over all sampled in the cell . For each cell , we let 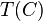 be the auxiliary value for cell , which is commonly called the "benchmark target" for cell . Next, we compute a benchmark factor
be the auxiliary value for cell , which is commonly called the "benchmark target" for cell . Next, we compute a benchmark factor 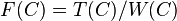 . Then, we adjust all weights by multiplying it by its benchmark factor
. Then, we adjust all weights by multiplying it by its benchmark factor 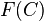 , for its cell . The net result is that the estimated
, for its cell . The net result is that the estimated 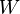 [formed by summing
[formed by summing 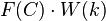 ] will now equal the benchmark target total
] will now equal the benchmark target total 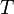 . But the more important benefit is that the estimate of the total of [formed by summing
. But the more important benefit is that the estimate of the total of [formed by summing 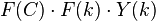 ] will tend to be more accurate.
] will tend to be more accurate.
Relationship to stratified sampling
Benchmarking is sometimes referred to as 'post-stratification' because of its similarities to stratified sampling. The difference between the two is that in stratified sampling, we decide in advance how many units will be sampled from each stratum (equivalent to benchmarking cells); in benchmarking, we select units from the broader population, and the number chosen from each cell is a matter of chance.
The advantage of stratified sampling is that the sample numbers in each stratum can be controlled for desired accuracy outcomes. Without this control, we may end up with too much sample in one stratum and not enough in another - indeed, it's possible that a sample will contain no members from a certain cell, in which case benchmarking fails because 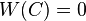 , leading to a divide-by-zero problem. In such cases, it is necessary to 'collapse' cells together so that each remaining cell has an adequate sample size.
, leading to a divide-by-zero problem. In such cases, it is necessary to 'collapse' cells together so that each remaining cell has an adequate sample size.
For this reason, benchmarking is generally used in situations where stratified sampling is impractical. For instance, when selecting people from a telephone directory, we can't tell what age they are so we can't easily stratify the sample by age. However, we can collect this information from the people sampled, allowing us to benchmark against demographic information.