Stack buffer overflow
In software, a stack buffer overflow or stack buffer overrun occurs when a program writes to a memory address on the program's call stack outside of the intended data structure, which is usually a fixed-length buffer.[1][2] Stack buffer overflow bugs are caused when a program writes more data to a buffer located on the stack than what is actually allocated for that buffer. This almost always results in corruption of adjacent data on the stack, and in cases where the overflow was triggered by mistake, will often cause the program to crash or operate incorrectly. Stack buffer overflow is a type of the more general programming malfunction known as buffer overflow (or buffer overrun).[1] Overfilling a buffer on the stack is more likely to derail program execution than overfilling a buffer on the heap because the stack contains the return addresses for all active function calls.
Stack buffer overflow can be caused deliberately as part of an attack known as stack smashing. If the affected program is running with special privileges, or accepts data from untrusted network hosts (e.g. a webserver) then the bug is a potential security vulnerability. If the stack buffer is filled with data supplied from an untrusted user then that user can corrupt the stack in such a way as to inject executable code into the running program and take control of the process. This is one of the oldest and more reliable methods for attackers to gain unauthorized access to a computer.[3][4][5]
Exploiting stack buffer overflows
The canonical method for exploiting a stack based buffer overflow is to overwrite the function return address with a pointer to attacker-controlled data (usually on the stack itself).[3][6] This is illustrated in the example below:
- An example with strcpy
#include <string.h> void foo (char *bar) { char c[12]; strcpy(c, bar); // no bounds checking } int main (int argc, char **argv) { foo(argv[1]); }
This code takes an argument from the command line and copies it to a local stack variable c. This works fine for command line arguments smaller than 12 characters (as you can see in figure B below). Any arguments larger than 11 characters long will result in corruption of the stack. (The maximum number of characters that is safe is one less than the size of the buffer here because in the C programming language strings are terminated by a zero byte character. A twelve-character input thus requires thirteen bytes to store, the input followed by the sentinel zero byte. The zero byte then ends up overwriting a memory location that's one byte beyond the end of the buffer.)
- The program stack in
foo()with various inputs
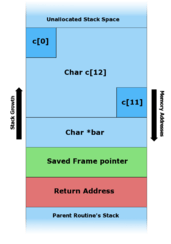 A. - Before data is copied. |
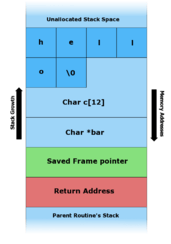 B. - "hello" is the first command line argument. |
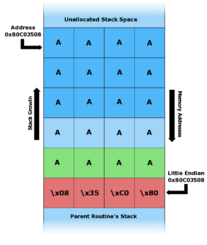 C. - "AAAAAAAAAAAAAAAAAAAA\x08\x35\xC0\x80" is the first command line argument. |
Notice in figure C above, when an argument larger than 11 bytes is supplied on the command line foo() overwrites local stack data, the saved frame pointer, and most importantly, the return address. When foo() returns it pops the return address off the stack and jumps to that address (i.e. starts executing instructions from that address). Thus, the attacker has overwritten the return address with a pointer to the stack buffer char c[12], which now contains attacker-supplied data. In an actual stack buffer overflow exploit the string of "A"'s would instead be shellcode suitable to the platform and desired function. If this program had special privileges (e.g. the SUID bit set to run as the superuser), then the attacker could use this vulnerability to gain superuser privileges on the affected machine.[3]
The attacker can also modify internal variable values to exploit some bugs. With this example:
#include <string.h> #include <stdio.h> void foo (char *bar) { float My_Float = 10.5; // Addr = 0x0023FF4C char c[28]; // Addr = 0x0023FF30 // Will print 10.500000 printf("My Float value = %f\n", My_Float); /* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Memory map: @ : c allocated memory # : My_Float allocated memory *c *My_Float 0x0023FF30 0x0023FF4C | | @@@@@@@@@@@@@@@@@@@@@@@@@@@@##### foo("my string is too long !!!!! XXXXX"); memcpy will put 0x1010C042 (little endian) in My_Float value. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/ memcpy(c, bar, strlen(bar)); // no bounds checking... // Will print 96.031372 printf("My Float value = %f\n", My_Float); } int main (int argc, char **argv) { foo("my string is too long !!!!! \x10\x10\xc0\x42"); return 0; }
Platform related differences
A number of platforms have subtle differences in their implementation of the call stack that can affect the way a stack buffer overflow exploit will work. Some machine architectures store the top level return address of the call stack in a register. This means that any overwritten return address will not be used until a later unwinding of the call stack. Another example of a machine specific detail that can affect the choice of exploitation techniques is the fact that most RISC style machine architectures will not allow unaligned access to memory.[7] Combined with a fixed length for machine opcodes this machine limitation can make the jump to ESP technique almost impossible to implement (with the one exception being when the program actually contains the unlikely code to explicitly jump to the stack register).[8][9]
Stacks that grow up
Within the topic of stack buffer overflows, an often discussed but rarely seen architecture is one in which the stack grows in the opposite direction. This change in architecture is frequently suggested as a solution to the stack buffer overflow problem because any overflow of a stack buffer that occurs within the same stack frame can not overwrite the return pointer. Further investigation of this claimed protection finds it to be a naive solution at best. Any overflow that occurs in a buffer from a previous stack frame will still overwrite a return pointer and allow for malicious exploitation of the bug.[10] For instance, in the example above, the return pointer for foo will not be overwritten because the overflow actually occurs within the stack frame for strcpy. However, because the buffer that overflows during the call to strcpy resides in a previous stack frame, the return pointer for strcpy will have a numerically higher memory address than the buffer. This means that instead of the return pointer for foo being overwritten, the return pointer for strcpy will be overwritten. At most this means that growing the stack in the opposite direction will change some details of how stack buffer overflows are exploitable, but it will not reduce significantly the number of exploitable bugs.
Protection schemes
Over the years a number of schemes have been developed to inhibit malicious stack buffer overflow exploitation. These may usually be classified into three categories:
- Detect that a stack buffer overflow has occurred and thus prevent redirection of the instruction pointer to malicious code.
- Prevent the execution of malicious code from the stack without directly detecting the stack buffer overflow.
- Randomize the memory space such that finding executable code becomes unreliable.
Stack canaries
Stack canaries, named for their analogy to a canary in a coal mine, are used to detect a stack buffer overflow before execution of malicious code can occur. This method works by placing a small integer, the value of which is randomly chosen at program start, in memory just before the stack return pointer. Most buffer overflows overwrite memory from lower to higher memory addresses, so in order to overwrite the return pointer (and thus take control of the process) the canary value must also be overwritten. This value is checked to make sure it has not changed before a routine uses the return pointer on the stack.[2] This technique can greatly increase the difficulty of exploiting a stack buffer overflow because it forces the attacker to gain control of the instruction pointer by some non-traditional means such as corrupting other important variables on the stack.[2]
Nonexecutable stack
Another approach to preventing stack buffer overflow exploitation is to enforce a memory policy on the stack memory region that disallows execution from the stack (W^X, "Write XOR Execute"). This means that in order to execute shellcode from the stack an attacker must either find a way to disable the execution protection from memory, or find a way to put her/his shellcode payload in a non-protected region of memory. This method is becoming more popular now that hardware support for the no-execute flag is available in most desktop processors.
While this method definitely makes the canonical approach to stack buffer overflow exploitation fail, it is not without its problems. First, it is common to find ways to store shellcode in unprotected memory regions like the heap, and so very little need change in the way of exploitation.[11]
Even if this were not so, there are other ways. The most damning is the so-called return to libc method for shellcode creation. In this attack the malicious payload will load the stack not with shellcode, but with a proper call stack so that execution is vectored to a chain of standard library calls, usually with the effect of disabling memory execute protections and allowing shellcode to run as normal.[12] This works because the execution never actually vectors to the stack itself.
A variant of return-to-libc is return-oriented programming, which sets up a series of return addresses, each of which executes a small sequence of cherry-picked machine instructions within the existing program code or system libraries, sequence which ends with a return. These so-called gadgets each accomplish some simple register manipulation or similar execution before returning, and stringing them together achieves the attacker's ends. It is even possible to use "returnless" return-oriented programming by exploiting instructions or groups of instructions that behave much like a return instruction.[13]
Randomization
Instead of separating the code from the data another mitigation technique is to introduce randomization to the memory space of the executing program. Since the attacker needs to determine where executable code that can be used resides, either an executable payload is provided (with an executable stack) or one is constructed using code reuse such as in ret2libc or ROP (Return Oriented Programming) randomizing the memory layout will as a concept prevent the attacker from knowing where any code is. However implementations typically will not randomize everything, usually the executable itself is loaded at a fixed address and hence even when ASLR (Address Space Layout Randomization) is combined with a nonexecutable stack the attacker can use this fixed region of memory. Therefore all programs should be compiled with PIE (position-independent executables) such that even this region of memory is randomized. The entropy of the randomization is different from implementation to implementation and a low enough entropy can in itself be a problem in terms of brute forcing the memory space that is randomized.
Notable examples
- The Morris worm spread in part by exploiting a stack buffer overflow in the Unix finger server.
- The Witty worm spread by exploiting a stack buffer overflow in the Internet Security Systems BlackICE Desktop Agent.
- The Slammer worm spread by exploiting a stack buffer overflow in Microsoft's SQL server.
- The Blaster worm spread by exploiting a stack buffer overflow in Microsoft DCOM service.
- The Twilight hack was made for the Wii by giving a lengthy character name for the horse ('Epona') in The Legend of Zelda: Twilight Princess. This caused a stack buffer overflow, allowing arbitrary code to be run on an unmodified system.
See also
- Address space layout randomization
- Buffer overflow
- Call stack
- Computer security
- ExecShield
- Executable space protection
- Exploit (computer security)
- Format string attack
- grsecurity
- Heap overflow
- Integer overflow
- NX bit
- PaX
- Return-oriented programming
- Security-Enhanced Linux
- Stack overflow
- Storage violation
- Vulnerability (computing)
References
- ↑ 1.0 1.1 Fithen, William L.; Seacord, Robert (2007-03-27). "VT-MB. Violation of Memory Bounds". US CERT.
- ↑ 2.0 2.1 2.2 Dowd, Mark; McDonald, John; Schuh, Justin (November 2006). The Art Of Software Security Assessment. Addison Wesley. pp. 169–196. ISBN 0-321-44442-6.
- ↑ 3.0 3.1 3.2 Levy, Elias (1996-11-08). "Smashing The Stack for Fun and Profit". Phrack 7 (49): 14.
- ↑ Pincus, J.; Baker, B. (July–August 2004). "Beyond Stack Smashing: Recent Advances in Exploiting Buffer Overruns". IEEE Security and Privacy Magazine 2 (4): 20–27. doi:10.1109/MSP.2004.36.
- ↑ Burebista. "Stack Overflows" (PDF). (dead link)
- ↑ Bertrand, Louis (2002). "OpenBSD: Fix the Bugs, Secure the System". MUSESS '02: McMaster University Software Engineering Symposium.
- ↑ pr1. "Exploiting SPARC Buffer Overflow vulnerabilities".
- ↑ Curious (2005-01-08). "Reverse engineering - PowerPC Cracking on Mac OS X with GDB". Phrack 11 (63): 16.
- ↑ Sovarel, Ana Nora; Evans, David; Paul, Nathanael. "Where’s the FEEB? The Effectiveness of Instruction Set Randomization".
- ↑ Zhodiac (2001-12-28). "HP-UX (PA-RISC 1.1) Overflows". Phrack 11 (58): 11.
- ↑ Foster, James C.; Osipov, Vitaly; Bhalla, Nish; Heinen, Niels (2005). Buffer Overflow Attacks: Detect, Exploit, Prevent (PDF). United States of America: Syngress Publishing, Inc. ISBN 1-932266-67-4.
- ↑ Nergal (2001-12-28). "The advanced return-into-lib(c) exploits: PaX case study". Phrack 11 (58): 4.
- ↑ Checkoway, S.; Davi, L.; Dmitrienko, A.; Sadeghi, A. R.; Shacham, H.; Winandy, M. (October 2010). "Return-Oriented Programming without Returns". Proceedings of the 17th ACM conference on Computer and communications security - CCS '10. pp. 559–572. doi:10.1145/1866307.1866370. ISBN 978-1-4503-0245-6.