Similarity measure
In computer science, a similarity measure or similarity function is a real-valued function that quantifies the similarity between two objects. Although no single definition of a similarity measure exists, usually similarity measures are in some sense the inverse of distance metrics: they take on large values for similar objects and either zero or a negative value for very dissimilar objects. E.g., in the context of cluster analysis, Frey and Dueck suggest defining a similarity measure

where 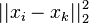 is the squared Euclidean distance.[1]
is the squared Euclidean distance.[1]
In information retrieval, cosine similarity is a commonly used similarity measure, defined on vectors arising from the bag of words model. In machine learning, common kernel functions such as the RBF kernel can be viewed as similarity functions.[2]
References
- ↑ Brendan J. Frey; Delbert Dueck (2007). "Clustering by passing messages between data points". Science 315: 972–976. doi:10.1126/science.1136800. PMID 17218491.
- ↑ Vert, Jean-Philippe; Koji Tsuda; Bernhard Schölkopf (2004). "A primer on kernel methods". Kernel Methods in Computational Biology.
- F. Gregory Ashby; Daniel M. Ennis (2007). "Similarity measures". Scholarpedia 2 (12). doi:10.4249/scholarpedia.4116.