Siegel–Tukey test
In statistics, the Siegel–Tukey test, named after Sidney Siegel and John Tukey, is a non-parametric test which may be applied to data measured at least on an ordinal scale. It tests for differences in scale between two groups.
The test is used to determine if one of two groups of data tends to have more widely dispersed values than the other. In other words, the test determines whether one of the two groups tends to move, sometimes to the right, sometimes to the left, but away from the center (of the ordinal scale).
The test was published in 1960 by Sidney Siegel and John Wilder Tukey in the Journal of the American Statistical Association, in the article "A Nonparametric Sum of Ranks Procedure for Relative Spread in Unpaired Samples."
Principle
The principle is based on the following idea:
Suppose there are two groups A and B with n observations for the first group and m observations for the second (so there are N = n + m total observations). If all N observations are arranged in ascending order, it can be expected that the values of the two groups will be mixed or sorted randomly, if there are no differences between the two groups (following the null hypothesis H0). This would mean that among the ranks of extreme (high and low) scores, there would be similar values from Group A and Group B.
If, say, Group A were more inclined to extreme values (the alternative hypothesis H1), then there will be a higher proportion of observations from group A with low or high values, and a reduced proportion of values at the center.
- Hypothesis H0: σ2A = σ2B & MeA = MeB (where σ2 and Me are the variance and the median, respectively)
- Hypothesis H1: σ2A > σ2B
Method
Two groups, A and B, produce the following values (already sorted in ascending order):
- A: 33 62 84 85 88 93 97 B: 4 16 48 51 66 98
By combining the groups, a group of 13 entries is obtained. The ranking is done by alternate extremes (rank 1 is lowest, 2 and 3 are the two highest, 4 and 5 are the two next lowest, etc.).
| Group: | B | B | A | B | B | A | B | A | A | A | A | A | B | (source of value) |
| Value: | 4 | 16 | 33 | 48 | 51 | 62 | 66 | 84 | 85 | 88 | 93 | 97 | 98 | (sorted) |
| Rank: | 1 | 4 | 5 | 8 | 9 | 12 | 13 | 11 | 10 | 7 | 6 | 3 | 2 | (alternate extremes) |
The sum of the ranks within each W group:
- WA = 5 + 12 + 11 + 10 + 7 + 6 + 3 = 54
- WB = 1 + 4 + 8 + 9 + 13 + 2 = 37
If the null hypothesis is true, it is expected that the sum of the ranks (taking into account the size of the two groups) will be roughly the same.
If one of the two groups is more dispersed its sum will be lower, due to receiving more of the low ranks reserved for the extreme tails, while the other group will receive more of the high scores assigned to the center (this is analogous to the Wilcoxon rank sum test, which also accounts for the use of the notation WA and WB in calculating the rank sums).
From the rank sums the U statistics are calculated by subtracting off the minimum possible score, n(n + 1)/2 for each group:[1]
- UA = 54 − 7(8)/2 = 26
- UB = 37 − 6(7)/2 = 16
Since
![\Pr\left[X \le \min(U_A,U_B) \right] \!](../I/m/b41a01ea94105c217ed3ca4ddd348dd4.png)
where
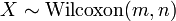
is the desired p-value, a table of the Wilcoxon rank-sum distribution can be used to find the statistical significance of the results.
Using the example's data again, with groups of sizes 6 and 7:
![\Pr\left[x \le 16 \right] = 0.2669.\,\!](../I/m/0026afb32be642c61cd3b4dd5b59aafe.png)
indicating little or no reason to reject the null hypothesis that the dispersion of the two groups is the same.
Remarks
The Siegel–Tukey test has relatively low power. For example, in the presence of values distributed as a Gaussian, power is equal to 61%.
See also
- Non-parametric statistics
- Statistical hypothesis testing
References
- ↑ Lehmann, Erich L., Nonparametrics: Statistical Methods Based on Ranks, Springer, 2006, pp. 9, 11–12.