Segmentation-based object categorization
The image segmentation problem is concerned with partitioning an image into multiple regions according to some homogeneity criterion. This article is primarily concerned with graph theoretic approaches to image segmentation. Segmentation-based object categorization can be viewed as a specific case of spectral clustering applied to image segmentation.
Applications of image segmentation
- Image compression
- Segment the image into homogeneous components, and use the most suitable compression algorithm for each component to improve compression.
- Medical diagnosis
- Automatic segmentation of MRI images for identification of cancerous regions.
- Mapping and measurement
- Automatic analysis of remote sensing data from satellites to identify and measure regions of interest.
Segmentation using normalized cuts
Graph theoretic formulation
The set of points in an arbitrary feature space can be represented as a weighted undirected complete graph G = (V, E), where the nodes of the graph are the points in the feature space. The weight 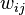 of an edge
of an edge 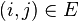 is a function of the similarity between the nodes
is a function of the similarity between the nodes 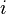 and
and 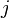 . In this context, we can formulate the image segmentation problem as a graph partitioning problem that asks for a partition
. In this context, we can formulate the image segmentation problem as a graph partitioning problem that asks for a partition 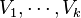 of the vertex set
of the vertex set 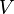 , where, according to some measure, the vertices in any set
, where, according to some measure, the vertices in any set 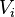 have high similarity, and the vertices in two different sets
have high similarity, and the vertices in two different sets 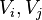 have low similarity.
have low similarity.
Normalized cuts
Let G = (V, E, w) be a weighted graph. Let 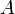 and
and 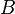 be two subsets of vertices.
be two subsets of vertices.
Let:
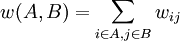
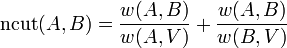
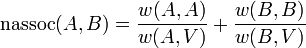
In the normalized cuts approach,[1] for any cut 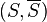 in
in 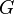 ,
, 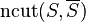 measures the similarity between different parts, and
measures the similarity between different parts, and 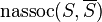 measures the total similarity of vertices in the same part.
measures the total similarity of vertices in the same part.
Since 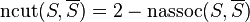 , a cut
, a cut 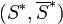 that minimizes also maximizes .
that minimizes also maximizes .
Computing a cut that minimizes is an NP-hard problem. However, we can find in polynomial time a cut of small normalized weight using spectral techniques.
The ncut algorithm
Let:
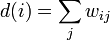
Also, let D be an 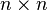 diagonal matrix with
diagonal matrix with 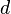 on the diagonal, and let
on the diagonal, and let 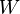 be an symmetric matrix with
be an symmetric matrix with 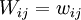 .
.
After some algebraic manipulations, we get:
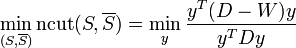
subject to the constraints:
-
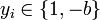 , for some constant
, for some constant 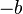
-
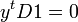
Minimizing  subject to the constraints above is NP-hard. To make the problem tractable, we relax the constraints on
subject to the constraints above is NP-hard. To make the problem tractable, we relax the constraints on  , and allow it to take real values. The relaxed problem can be solved by solving the generalized eigenvalue problem
, and allow it to take real values. The relaxed problem can be solved by solving the generalized eigenvalue problem  for the second smallest generalized eigenvalue.
for the second smallest generalized eigenvalue.
The partitioning algorithm:
- Given a set of features, set up a weighted graph
 , compute the weight of each edge, and summarize the information in
, compute the weight of each edge, and summarize the information in 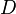 and .
and . - Solve for eigenvectors with the smallest eigenvalues.
- Use the eigenvector with the second smallest eigenvalue to bipartition the graph (e.g. grouping according to sign).
- Decide if the current partition should be subdivided.
- Recursively partition the segmented parts, if necessary.
Computational Complexity
Solving a standard eigenvalue problem for all eigenvectors (using the QR algorithm, for instance) takes 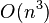 time. This is impractical for image segmentation applications where
time. This is impractical for image segmentation applications where  is the number of pixels in the image.
is the number of pixels in the image.
Since only one eigenvector, corresponding to the second smallest generalized eigenvalue, is used by the ncut algorithm, efficiency can be dramatically improved if the solve of the corresponding eigenvalue problem is performed in a matrix-free fashion, i.e., without explicitly manipulating with or even computing the matrix W, as, e.g., in the Lanczos algorithm. Matrix-free methods require only a function that performs a matrix-vector product for a given vector, on every iteration. For image segmentaion, the matrix W is typically sparse, with a number of nonzero entries 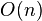 , so such a matrix-vector product takes time.
, so such a matrix-vector product takes time.
For high-resolution images, the second eigenvalue is often ill-conditioned, leading to slow convergence of iterative eigenvalue solvers, such as the Lanczos algorithm.Preconditioning is a key technology accelerating the convergence, e.g., in the matrix-free LOBPCG method. Computing the eigenvector using an optimally preconditioned matrix-free method takes time, which is the optimal complexity, since the eigenvector has components.
OBJ CUT
OBJ CUT[2] is an efficient method that automatically segments an object. The OBJ CUT method is a generic method, and therefore it is applicable to any object category model. Given an image D containing an instance of a known object category, e.g. cows, the OBJ CUT algorithm computes a segmentation of the object, that is, it infers a set of labels m.
Let m be a set of binary labels, and let  be a shape parameter( is a shape prior on the labels from a layered pictorial structure (LPS) model). An energy function
be a shape parameter( is a shape prior on the labels from a layered pictorial structure (LPS) model). An energy function  is defined as follows.
is defined as follows.
-
 (1)
(1)
The term  is called a unary term, and the term
is called a unary term, and the term  is called a pairwise term.
A unary term consists of the likelihood
is called a pairwise term.
A unary term consists of the likelihood 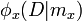 based on color, and the unary potential
based on color, and the unary potential 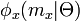 based on the distance from . A pairwise term consists of a prior
based on the distance from . A pairwise term consists of a prior 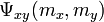 and a contrast term
and a contrast term 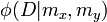 .
.
The best labeling 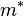 minimizes
minimizes 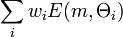 , where
, where 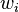 is the weight of the parameter
is the weight of the parameter 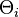 .
.
-
 (2)
(2)
Algorithm
- Given an image D, an object category is chosen, e.g. cows or horses.
- The corresponding LPS model is matched to D to obtain the samples
- The objective function given by equation (2) is determined by computing
 and using
and using 
- The objective function is minimized using a single MINCUT operation to obtain the segmentation m.
Other approaches
- Jigsaw approach[3]
- Image parsing [4]
- Interleaved segmentation [5]
- LOCUS [6]
- LayoutCRF [7]
- Minimum spanning tree-based segmentation
References
- ↑ Jianbo Shi and Jitendra Malik (1997): "Normalized Cuts and Image Segmentation", IEEE Conference on Computer Vision and Pattern Recognition, pp 731–737
- ↑ M. P. Kumar, P. H. S. Torr, and A. Zisserman. Obj cut. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, San Diego, pages 18–25, 2005.
- ↑ E. Borenstein, S. Ullman: Class-specic, top-down segmentation. In Proceedings of the 7th European Conference on Computer Vision, Copenhagen, Denmark, pages 109–124, 2002.
- ↑ Z. Tu, X. Chen, A. L. Yuille, S. C. Zhu: Image Parsing: Unifying Segmentation, Detection, and Recognition. Toward Category-Level Object Recognition 2006: 545–576
- ↑ B. Leibe, A. Leonardis, B. Schiele: An Implicit Shape Model for Combined Object Categorization and Segmentation. Toward Category-Level Object Recognition 2006: 508–524
- ↑ J. Winn, N. Joijic. Locus: Learning object classes with unsupervised segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, 2005.
- ↑ J. M. Winn, J. Shotton: The Layout Consistent Random Field for Recognizing and Segmenting Partially Occluded Objects. CVPR (1) 2006: 37–44