Schema (genetic algorithms)
A schema is a template in computer science used in the field of genetic algorithms that identifies a subset of strings with similarities at certain string positions. Schemata are a special case of cylinder sets; and so form a topological space.[1]
Description
For example, consider binary strings of length 6. The schema 1**0*1 describes the set of all words of length 6 with 1's at the first and sixth positions and a 0 at the fourth position. The * is a wildcard symbol, which means that positions 2, 3 and 5 can have a value of either 1 or 0. The order of a schema is defined as the number of fixed positions in the template, while the defining length 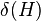 is the distance between the first and last specific positions. The order of 1**0*1 is 3 and its defining length is 5. The fitness of a schema is the average fitness of all strings matching the schema. The fitness of a string is a measure of the value of the encoded problem solution, as computed by a problem-specific evaluation function.
is the distance between the first and last specific positions. The order of 1**0*1 is 3 and its defining length is 5. The fitness of a schema is the average fitness of all strings matching the schema. The fitness of a string is a measure of the value of the encoded problem solution, as computed by a problem-specific evaluation function.
Length
The length of a schema 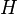 , called
, called 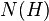 , is defined as the total number of nodes in the schema. is also equal to the number of nodes in the programs matching .[2]
, is defined as the total number of nodes in the schema. is also equal to the number of nodes in the programs matching .[2]
Disruption
If the child of an individual that matches schema H does not itself match H, the schema is said to have been disrupted.[2]
See also
References
- ↑ Holland, John Henry (1992). Adaptation in Natural and Artificial Systems (reprint ed.). The MIT Press. ISBN 9780472084609. Retrieved 22 April 2014.
- ↑ 2.0 2.1 "Foundations of Genetic Programming". UCL UK. Retrieved 13 July 2010.