Sample exclusion dimension
In computational learning theory, sample exclusion dimensions arise in the study of exact concept learning with queries.[1]
In algorithmic learning theory, a concept over a domain X is a Boolean function over X. Here we only consider finite domains. A partial approximation S of a concept c is a Boolean function over 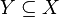 such that c is an extension to S.
such that c is an extension to S.
Let C be a class of concepts and c be a concept (not necessarily in C). Then a specifying set for c w.r.t. C, denoted by S is a partial approximation S of c such that C contains at most one extension to S. If we have observed a specifying set for some concept w.r.t. C, then we have enough information to verify a concept in C with at most one more mind change.
The exclusion dimension, denoted by XD(C), of a concept class is the maximum of the size of the minimum specifying set of c' with respect to C, where c' is a concept not in C.
References
- ↑ D. Angluin (2001). "Queries Revisited". In N. Abe, R. Khardon, T. Zeugmann. Algorithmic Learning Theory: 12th International Conference, ALT 2001, Washington, DC, USA, November 2001, Proceedings. Springer. pp. 26–28. ISBN 3-540-42875-5.