Residual sum of squares
In statistics, the residual sum of squares (RSS) is the sum of squares of residuals. It is also known as the sum of squared residuals (SSR) or the sum of squared errors of prediction (SSE). It is a measure of the discrepancy between the data and an estimation model. A small RSS indicates a tight fit of the model to the data.
In general, total sum of squares = explained sum of squares + residual sum of squares. For a proof of this in the multivariate ordinary least squares (OLS) case, see partitioning in the general OLS model.
One explanatory variable
In a model with a single explanatory variable, RSS is given by
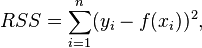
where yi is the i th value of the variable to be predicted, xi is the i th value of the explanatory variable, and 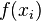 is the predicted value of yi (also termed
is the predicted value of yi (also termed 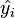 ).
In a standard linear simple regression model,
).
In a standard linear simple regression model, 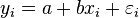 , where a and b are coefficients, y and x are the regressand and the regressor, respectively, and ε is the error term. The sum of squares of residuals is the sum of squares of estimates of εi; that is
, where a and b are coefficients, y and x are the regressand and the regressor, respectively, and ε is the error term. The sum of squares of residuals is the sum of squares of estimates of εi; that is
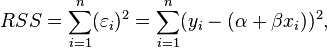
where 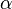 is the estimated value of the constant term
is the estimated value of the constant term 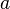 and
and 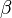 is the estimated value of the slope coefficient b.
is the estimated value of the slope coefficient b.
Matrix expression for the OLS residual sum of squares
The general regression model with n observations and k explanators, the first of which is a constant unit vector whose coefficient is the regression intercept, is
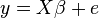
where y is an n × 1 vector of dependent variable observations, each column of the n × k matrix X is a vector of observations on one of the k explanators, is a k × 1 vector of true coefficients, and e is an n× 1 vector of the true underlying errors. The ordinary least squares estimator for is
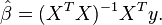
The residual vector 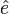 is
is 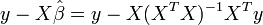 , so the residual sum of squares
, so the residual sum of squares 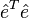 is, after simplification,
is, after simplification,
![RSS = y^T y - y^T X(X^T X)^{-1} X^T y = y^T [I - X(X^T X)^{-1} X^T] y = y^T [I - H] y](../I/m/fe7363b61a9e14a1ad0abd45db909d82.png) , where H is the hat matrix, or the prediction matrix in linear regression.
, where H is the hat matrix, or the prediction matrix in linear regression.
See also
- Sum of squares (statistics)
- Squared deviations
- Errors and residuals in statistics
- Lack-of-fit sum of squares
- Degrees of freedom (statistics)#Sum of squares and degrees of freedom
- Chi-squared distribution#Applications
References
- Draper, N.R.; Smith, H. (1998). Applied Regression Analysis (3rd ed.). John Wiley. ISBN 0-471-17082-8.